
雪花算法SnowFlake生成唯一ID
这个算法的好处很简单可以在每秒产生约400W个不同的16位数字ID(10进制)
1. 分布式ID常见生成策略:
分布式ID生成策略常见的有如下几种:
数据库自增ID。
UUID生成。
Redis的原子自增方式。
数据库水平拆分,设置初始值和相同的自增步长。
批量申请自增ID。
雪花算法。
百度UidGenerator算法(基于雪花算法实现自定义时间戳)。
美团Leaf算法(依赖于数据库,ZK)。
本文主要介绍SnowFlake 算法,是 Twitter 开源的分布式 id 生成算法。
其核心思想就是:使用一个 64 bit 的 long 型的数字作为全局唯一 id。在分布式系统中的应用十分广泛,且ID 引入了时间戳,保持自增性且不重复。
2. 雪花算法的结构:
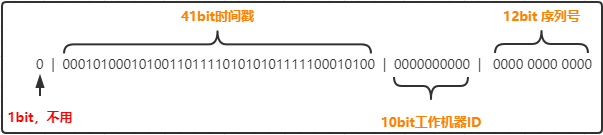
主要分为以下几个部分:
是 1 个 bit:0,这个是无意义的。
是 41 个 bit:表示的是时间戳。
是 10 个 bit:表示的是机房 id,0000000000,因为我传进去的就是0。
是 12 个 bit:表示的序号,就是某个机房某台机器上这一毫秒内同时生成的 id 的序号,0000 0000 0000。
我们分别解释一下四个部分:
1 bit,是无意义的:
因为二进制里第一个 bit 为如果是 1,那么都是负数,但是我们生成的 id 都是正数,所以第一个 bit 统一都是 0。
41 bit:表示的是时间戳,单位是毫秒。
41 bit 可以表示的数字多达 2^41 - 1,也就是可以标识 2 ^ 41 - 1 个毫秒值,换算成年就是表示 69 年的时间。
10 bit:记录工作机器 id,代表的是这个服务最多可以部署在 2^10 台机器上,也就是 1024 台机器。
但是 10 bit 里 5 个 bit 代表机房 id,5 个 bit 代表机器 id。意思就是最多代表 2 ^ 5 个机房(32 个机房),每个机房里可以代表 2 ^ 5 个机器(32 台机器),这里可以随意拆分,比如拿出4位标识业务号,其他6位作为机器号。可以随意组合。
12 bit:这个是用来记录同一个毫秒内产生的不同 id。
12 bit 可以代表的最大正整数是 2 ^ 12 - 1 = 4096,也就是说可以用这个 12 bit 代表的数字来区分同一个毫秒内的 4096 个不同的 id。也就是同一毫秒内同一台机器所生成的最大ID数量为4096
简单来说,你的某个服务假设要生成一个全局唯一 id,那么就可以发送一个请求给部署了 SnowFlake 算法的系统,由这个 SnowFlake 算法系统来生成唯一 id。这个 SnowFlake 算法系统首先肯定是知道自己所在的机器号,(这里姑且讲10bit全部作为工作机器ID)接着 SnowFlake 算法系统接收到这个请求之后,首先就会用二进制位运算的方式生成一个 64 bit 的 long 型 id,64 个 bit 中的第一个 bit 是无意义的。接着用当前时间戳(单位到毫秒)占用41 个 bit,然后接着 10 个 bit 设置机器 id。最后再判断一下,当前这台机房的这台机器上这一毫秒内,这是第几个请求,给这次生成 id 的请求累加一个序号,作为最后的 12 个 bit。
二、PHP源码实现案例
1.demo1:
/**
* 雪花算法类
* @package app\helpers
*/
class SnowFlake
{
const EPOCH = 1479533469598;
const max12bit = 4095;
const max41bit = 1099511627775;
static $machineId = null;
public static function machineId($mId = 0) {
self::$machineId = $mId;
}
public static function generateParticle() {
/*
* Time - 42 bits
*/
$time = floor(microtime(true) * 1000);
/*
* Substract custom epoch from current time
*/
$time -= self::EPOCH;
/*
* Create a base and add time to it
*/
$base = decbin(self::max41bit + $time);
/*
* Configured machine id - 10 bits - up to 1024 machines
*/
if(!self::$machineId) {
$machineid = self::$machineId;
} else {
$machineid = str_pad(decbin(self::$machineId), 10, "0", STR_PAD_LEFT);
}
/*
* sequence number - 12 bits - up to 4096 random numbers per machine
*/
$random = str_pad(decbin(mt_rand(0, self::max12bit)), 12, "0", STR_PAD_LEFT);
/*
* Pack
*/
$base = $base.$machineid.$random;
/*
* Return unique time id no
*/
return bindec($base);
}
public static function timeFromParticle($particle) {
/*
* Return time
*/
return bindec(substr(decbin($particle),0,41)) - self::max41bit + self::EPOCH;
}
}
2.demo2:
public function createID(){
//假设一个机器id
$machineId = 1234567890;
//41bit timestamp(毫秒)
$time = floor(microtime(true) * 1000);
//0bit 未使用
$suffix = 0;
//datacenterId 添加数据的时间
$base = decbin(pow(2,40) - 1 + $time);
//workerId 机器ID
$machineid = decbin(pow(2,9) - 1 + $machineId);
//毫秒类的计数
$random = mt_rand(1, pow(2,11)-1);
$random = decbin(pow(2,11)-1 + $random);
//拼装所有数据
$base64 = $suffix.$base.$machineid.$random;
//将二进制转换int
$base64 = bindec($base64);
$id = sprintf('%.0f', $base64);
return $id;
}
SnowFlake的优点是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由数据中心ID和机器ID作区分),效率较高。但是依赖与系统时间的一致性,如果系统时间被回调,或者改变,可能会造成id冲突或者重复。实际中我们的机房并没有那么多,我们可以改进改算法,将10bit的机器id优化,成业务表或者和我们系统相关的业务。