
注意:雪花算法并不是ID的唯一选择!
Hollis的新书限时折扣中,一本深入讲解Java基础的干货笔记!
在《悟空传》篇外篇里,有一个忧伤的故事。
秋天,树上掉下两片叶子,你要和它们说再见。但你如何知道这片叶子,不是另外一片叶子?是通过它的形状,还是通过它的重量?
当我们在分布式环境中存储一些数据的时候,不得不面对的一个选择,就是ID生成器。
使用一个唯一的字符串,来标识一条完整的记录。
这时候,不能使用md5或者sha1来对整个记录做摘要,因为我们后续还要改动这个记录。也不能使用单机的计数器,因为计数器容易重启清零,也会存在多台机器上的数值重复,这违背了无状态服务的建设目标。
无奈的选择UUID
虽然UUID在大多数语言中都有相关的类库,但除非迫不得以,我们一般不会使用它。UUID虽然不会重复,但它非常的长,长的让人望而生畏。
XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX
标准的UUID有5个部分组成:8-4-4-4-12,一共32个十六进制字符。因此,一共是128位。

当把UUID作为数据库的索引时,会因为它没有顺序性造成索引的随机分布和;因为数据量巨大造成查询性能降低。
同时,UUID也是不可读的。如果你把它打印在纸质的订单上,并不是一个好的主意。
UUID同时还有信息安全的隐患,它的数据计算里有MAC地址的参与,比较知名的是,曾被用于寻找梅丽莎病毒的制作者位置。
改造时间戳
如果你是单机应用,那么使用时间戳没什么问题,即使不用纳秒,使用毫秒也是足够的。但在分布式环境下面,时间戳同样不是一个好的选择。
即使你在机器安装了ntpd时间同步,但由于网络和机器的差异,计算机的时钟总是存在差异,你的时间戳总会出现重复。为了解决这个问题,你需要增加一些其他的标识,比如机器的ID,或者更多细分的信息减少时间的碰撞。
这种自定义的ID生成器,只适合特定的业务。
做着做着你就会发现,它本质上是雪花算法的变种。
雪花算法
雪花算法生成的ID是long类型,默认字符串长度是19位,它分为4个部分。
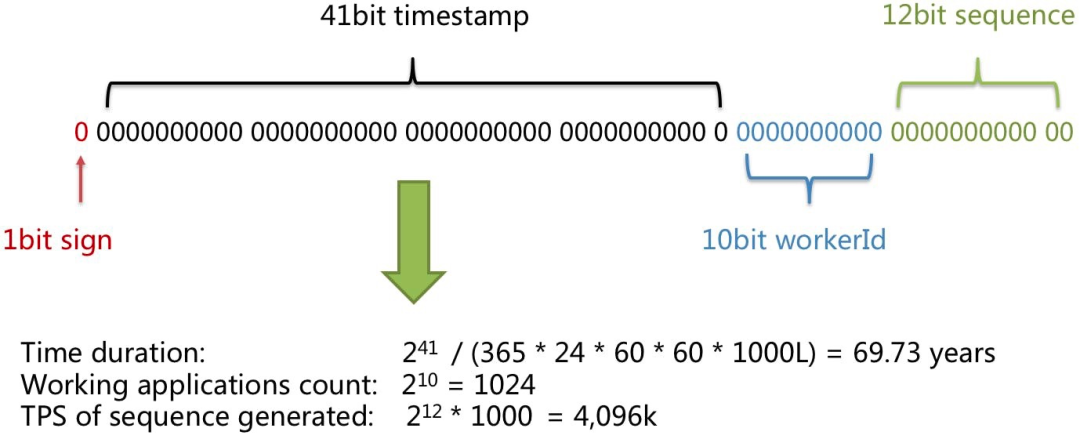
保留位 1 位。 毫秒时间戳 — 41 位(比如从现在开始,支持到未来的69年),这个其实也挺尴尬的,因为70年之后就会失效。但你不会在一家公司工作70年,所以,随它去吧。 配置的机器/节点/分片 ID — 10 位(总共支持 2^10 = 1024 个节点) 序列号 - 12 位(机器的本地计数,所以支持的并发已经很高了)
相比起UUID来,雪花算法所生成的ID是排序的,具有更好的紧凑性,是目前大多数业务优先采用的ID生成算法。
值得注意的是,雪花算法在JavaScript中有一个坑。后端在返回ID的时候,需要使用String类型代替Long类型,否则会产生预想不到的错误。
这是因为。在JavaScript中,存在两种数字。Number和BigInt。最常用的,就是number。
最大的Number,叫做Number.MAX_SAFE_INTEGER,它的值为:
2^53-1 或者 +/- 9,007,199,254,740,991
众所周知,Java中的Long,是64位的。Js中的这个安全Integer,完全达不到Java中定义的长度。
这就是万恶的IEEE_754规范,它在Long长度大于17位时会出现精度丢失的问题。
NanoID
NanoID是从JavaScript库中演变过来的,目前在多个语言上通用。它长下面这样。
V1StGXR8_Z5jdHi6B-myT
虽然NanoID无法替代雪花算法,但就凭这长度,替换UUID是绰绰有余的。NanoID 大小只有 108 字节,比UUID小了35%,更加紧凑。
另外,它的速度更快,它可以使用默认字母表每秒生成超过 220 万个唯一 ID,使用自定义字母表时每秒可以生成超过 180 万个唯一 ID,且几乎没有碰撞几率。
如果你的ID对顺序性没有什么严格的要求,比如使用了kv等非常松散的数据库,那么NanoID是你的不二选择。
End
介绍了这么多,你会用哪种ID生成器呢?其实,一个组件如果使用的量增加到一定程度,都会出现问题,需要专门进行组件设计。
比如美团的leaf,在大型互联网中肯定有用武之地。但对于一般互联网,甚至是中型互联网来说,这到底是糖衣还是炮弹,作为决策者的你不得不思量思量。
完
我的新书《深入理解Java核心技术》已经上市了,上市后一直蝉联京东畅销榜中,目前正在6折优惠中,想要入手的朋友千万不要错过哦~长按二维码即可购买~
长按扫码享受6折优惠
往期推荐

一次简单的 JVM 调优,拿去写到简历里

高并发下如何防重?

入职就想run的公司特征