
数据类别不平衡/长尾分布?不妨利用半监督或自监督学习
点击上方“机器学习与生成对抗网络”,关注星标
获取有趣、好玩的前沿干货!
文章 知乎 侵删 链接:https://zhuanlan.zhihu.com/p/259710601
来给大家介绍一下我们的最新工作,目前已被NeurIPS 2020接收:Rethinking the Value of Labels for Improving Class-Imbalanced Learning。这项工作主要研究一个经典而又非常实际且常见的问题:数据类别不平衡(也泛称数据长尾分布)下的分类问题。我们通过理论推导和大量实验发现,半监督和自监督均能显著提升不平衡数据下的学习表现。
目前代码(以及相应数据,30多个预训练好的模型)已开源。Github链接:https://github.com/YyzHarry/imbalanced-semi-self
那么开篇首先用一句话概括本文的主要贡献:我们分别从理论和实验上验证了,对于类别不均衡的学习问题,利用
都可以大大提升模型的表现,并且对于不同的平衡/不平衡的训练方法,从最基本的交叉熵损失,到进阶的类平衡损失[1][2],重采样[3],重加权[4][5],以及之前的state-of-the-art最优的decouple算法[6]等,都能带来一致的&较大的提升。相信我们从和现有方法正交的角度的分析,可以作为解决不平衡长尾问题的新的思路,其简单和通用性也使得能够很容易和不同方法相结合,进一步提升学习结果。
接下来我们进入正文,我会先抛开文章本身,大体梳理一下imbalance这个问题以及一部分研究现状,在此基础上尽量详细的介绍我们的思路和方法,省去不必要的细节。
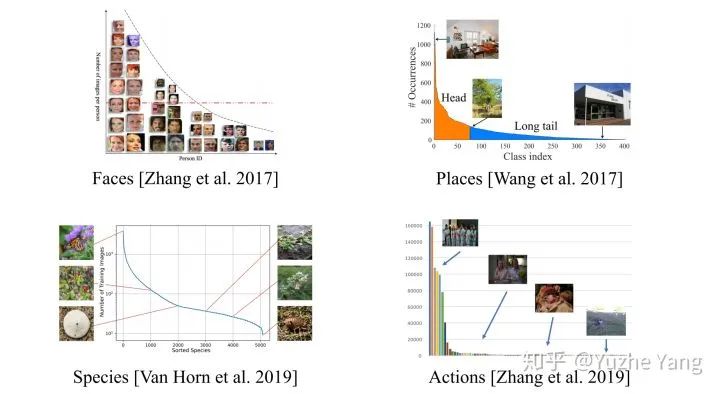
1.重采样(re-sampling):更具体可分为对少样本的过采样[3],或是对多样本的欠采样[8]。但因过采样容易overfit到minor class,无法学到更鲁棒易泛化的特征,往往在非常不平衡数据上表现会更差;而欠采样则会造成major class严重的信息损失,导致欠拟合发生。
2.数据合成(synthetic samples):即生成和少样本相似的“新”数据。经典方法SMOTE[9],思路简单来讲是对任意选取的少类样本,用K近邻选取其相似样本,通过对样本线性插值得到新样本。这里会想到和mixup[10]很相似,于是也有imbalance的mixup版本出现[11]。
3.重加权(re-weighting):对不同类别(甚至不同样本)分配不同权重。注意这里的权重可以是自适应的。此类方法的变种有很多,有最简单的按照类别数目的倒数来做加权[12],按照“有效”样本数加权[1],根据样本数优化分类间距的loss加权[4],等等。
4.迁移学习(transfer learning):这类方法的基本思路是对多类样本和少类样本分别建模,将学到的多类样本的信息/表示/知识迁移给少类别使用。代表性文章有[13][14]。
5.度量学习(metric learning):本质上是希望能够学到更好的embedding,对少类附近的boundary/margin更好的建模。有兴趣的同学可以看看[15][16]。
6.元学习/域自适应(meta learning/domain adaptation):分别对头部和尾部的数据进行不同处理,可以去自适应的学习如何重加权[17],或是formulate成域自适应问题[18]。
7.解耦特征和分类器(decoupling representation & classifier):最近的研究发现将特征学习和分类器学习解耦,把不平衡学习分为两个阶段,在特征学习阶段正常采样,在分类器学习阶段平衡采样,可以带来更好的长尾学习结果[5][6]。这也是目前的最优长尾分类算法。
于是,我们尝试系统性的分解并且分别分析上述两种不同的角度。我们的结论表明对于正面的和负面的角度,不平衡标签的价值都可被充分利用,从而极大的提高最后分类器的准确性:
从正面价值的角度,我们发现当有更多的无标签数据时,这些不平衡的标签提供了稀缺的监督信息。通过利用这些信息,我们可以结合半监督学习去显著的提高最后的分类结果,即使无标签数据也存在长尾分布。
从负面价值的角度,我们证明了不平衡标签并非在所有情况下都是有用的。标签的不平衡大概率会产生label bias。因此在训练中,我们首先想到“抛弃”标签的信息,通过自监督的学习方式先去学到好的起始表示形式。我们的结果表面通过这样的自监督预训练方式得到的模型也能够有效的提高分类的准确性。
 和
和  ,但是相同方差的Guassian mixture模型,我们可以很容易验证其贝叶斯最优分类器为:
,但是相同方差的Guassian mixture模型,我们可以很容易验证其贝叶斯最优分类器为:  。因此为了更好的分类,我们希望学习到他们的平均均值,
。因此为了更好的分类,我们希望学习到他们的平均均值,  。
。 以及一定量的无标签的数据,我们可以通过这个基础分类器给这些数据做pseudo-label。令
以及一定量的无标签的数据,我们可以通过这个基础分类器给这些数据做pseudo-label。令  和
和  代表pseudo-label为正和为负的数据的数量。为了估计
代表pseudo-label为正和为负的数据的数量。为了估计  ,最简单的方法我们可以通过pseudo-label给这些对应的没有标签的数据取平均得到
,最简单的方法我们可以通过pseudo-label给这些对应的没有标签的数据取平均得到  。假设
。假设  代表基础分类器对于两个类的准确度的gap。这样的话我们推出以下定理:
代表基础分类器对于两个类的准确度的gap。这样的话我们推出以下定理: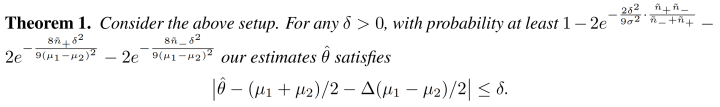 。越大的 影响我们的estimator 到理想的均值之间的距离。
。越大的 影响我们的estimator 到理想的均值之间的距离。 可以看做是对于无标签数据集的不平衡性的近似。我们可以看到,当
可以看做是对于无标签数据集的不平衡性的近似。我们可以看到,当  ,如果无标签数据很不平衡,那么数据少的一项会主导另外一项,从而影响最后的概率。
,如果无标签数据很不平衡,那么数据少的一项会主导另外一项,从而影响最后的概率。半监督的不平衡学习框架:我们的理论发现表明,利用pseudo-label伪标签(以及训练数据中的标签信息)可以有助于不平衡学习;而数据的不平衡程度会影响学习的结果。受此启发,我们系统地探索了无标记数据的有效性。我们采用最简单的自训练(self-training)的半监督学习方法,即对无标记数据生成伪标签(pseudo-labeling)进而一起训练。准确来讲,我们首先在原始的不平衡数据集  上正常训练获得一个中间步骤分类器
上正常训练获得一个中间步骤分类器  ,并将其应用于生成未标记数据
,并将其应用于生成未标记数据  的伪标签
的伪标签  ;通过结合两部分数据,我们最小化损失函数
;通过结合两部分数据,我们最小化损失函数  以学习最终模型
以学习最终模型  。
。
和 的学习策略,因此半监督框架也能很轻易的和现有类别不平衡的算法相结合。 和 的典型分布如下):

 维Guassian mixture的toy example。这次我们考虑两个类有相同的均值(都为0)但是不同的方差,
维Guassian mixture的toy example。这次我们考虑两个类有相同的均值(都为0)但是不同的方差,  和
和  。其中,我们假设负类是主要的类(mix 概率
。其中,我们假设负类是主要的类(mix 概率  )。我们考虑线性的分类器
)。我们考虑线性的分类器  ,
,  ,并且用标准的error probability,
,并且用标准的error probability, ,作为分类器的衡量标准。在正常的训练中,公式里的feature代表的是raw data,
,作为分类器的衡量标准。在正常的训练中,公式里的feature代表的是raw data,  。在这种情况下,我们可以首先证明上述的线性分类器一定会有至少
。在这种情况下,我们可以首先证明上述的线性分类器一定会有至少  的error probability(详见文章)。
的error probability(详见文章)。 ,
, 。我们考虑用
。我们考虑用  作为线性分类器的输入。在上述的分类器范围内, 我们可以得到一个分类器,
作为线性分类器的输入。在上述的分类器范围内, 我们可以得到一个分类器,  ,
, ,满足下面的定理:
,满足下面的定理: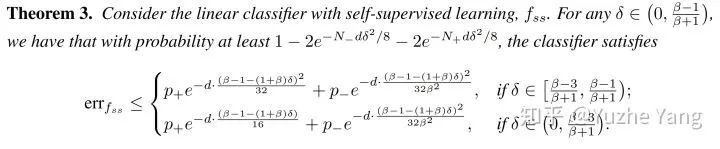
同样的,我们尝试直观的解释这个定理的意义。我们发现在这样简单的情况下,如果通过一个好的self-supervised task学习到了有用的表达形式,我们能得到:
的增加而指数型减小。对于如今常见的高维数据(如图像)这种性质是我们希望得到的。 和
和  代表训练数据里不同类的数量。从
代表训练数据里不同类的数量。从  和
和  这两项中我们可以发现,当数据越多且越平衡,我们就有更高的概率得到一个好的分类器。
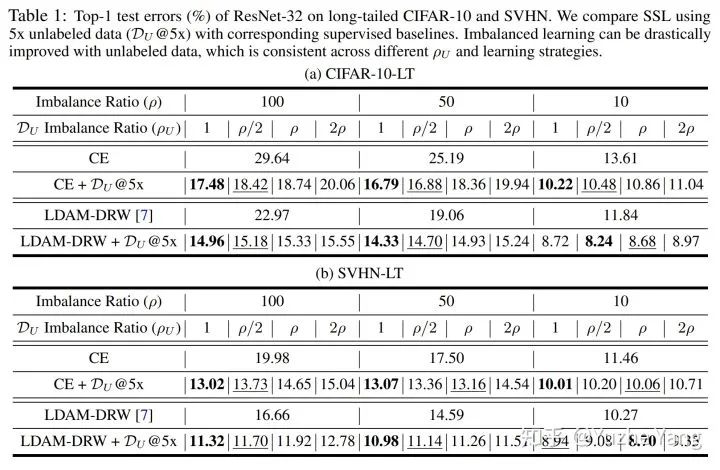
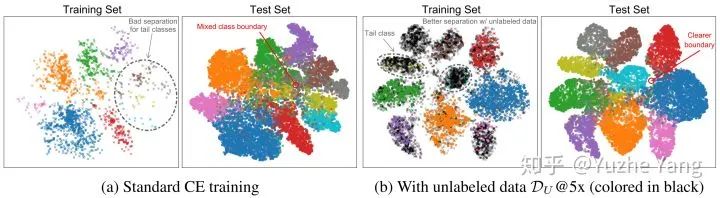
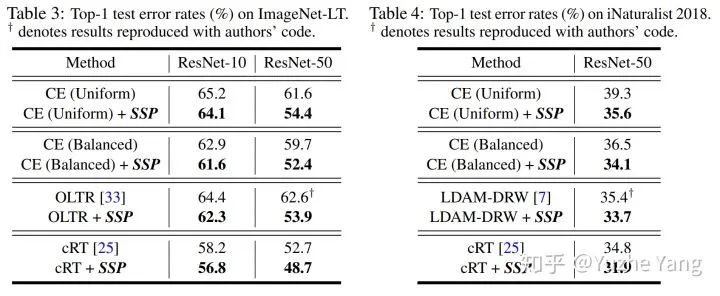
这两项中我们可以发现,当数据越多且越平衡,我们就有更高的概率得到一个好的分类器。具体实验结果如以下两表格所示。一言以蔽之,使用SSP能够对不同的 (1) 数据集,(2) 不平衡比率,以及 (3) 不同的基础训练算法,都带来了一致的、肉眼可见的提升,并且在不同数据集上都超过了之前最优的长尾分类算法。


参考文献:
【1】^abYin Cui, Menglin Jia, Tsung-Yi Lin, Yang Song, and Serge Belongie. Class-balanced loss based on effective number of samples. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 9268–9277, 2019.
【2】^Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. In ICCV, pages 2980–2988, 2017.
【3】^abSamira Pouyanfar, et al. Dynamic sampling in convolutional neural networks for imbalanced data classification.
【4】^abLearning Imbalanced Datasets with Label-Distribution-Aware Margin Loss. NeurIPS, 2019.
【5】^abBBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition. CVPR, 2020.
【6】^abDecoupling representation and classifier for long-tailed recognition. ICLR, 2020.
【7】^abiNatrualist 2018 competition dataset. https://github.com/visipedia/inat_comp/tree/master/2018
【8】^He, H. and Garcia, E. A. Learning from imbalanced data. TKDE, 2008.
【9】^Chawla, N. V., et al. SMOTE: synthetic minority oversampling technique. JAIR, 2002.
【10】^mixup: Beyond Empirical Risk Minimization. ICLR 2018.
【11】^H. Chou et al. Remix: Rebalanced Mixup. 2020.
【12】^Deep Imbalanced Learning for Face Recognition and Attribute Prediction. TPAMI, 2019.
【13】^Large-scale long-tailed recognition in an open world. CVPR, 2019.
【14】^Feature transfer learning for face recognition with under-represented data. CVPR, 2019.
【15】^Range Loss for Deep Face Recognition with Long-Tail. CVPR, 2017.
【16】^Learning Deep Representation for Imbalanced Classification. CVPR, 2016.
【17】^Meta-Weight-Net: Learning an Explicit Mapping For Sample Weighting. NeurIPS, 2019.
【18】^Rethinking Class-Balanced Methods for Long-Tailed Recognition from a Domain Adaptation Perspective. CVPR, 2020.
【19】^Spyros Gidaris, Praveer Singh, and Nikos Komodakis. Unsupervised representation learning by predicting image rotations. arXiv preprint arXiv:1803.07728, 2018.
【20】^Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. arXiv preprint arXiv:1911.05722, 2019.
END
猜您喜欢:
CVPR 2021 | GAN的说话人驱动、3D人脸论文汇总
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 | 超100篇!CVPR 2020最全GAN论文梳理汇总!