
CVPR 2021|一个绝妙的想法:在类别不平衡的数据上施展半监督学习

极市导读
本文介绍了一篇中稿CVPR2021的工作,关于半监督场景下的长尾分布问题。论文作者通过FixMatch模型实验发现对于样本数目非常少的点,虽recall非常的差,但是precision却很高。于是提出了对打上伪标签的数据根据类别多少来进行采样的框架。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
CReST: A Class-Rebalancing Self-Training Framework for Imbalanced Semi-Supervised Learning. (CVPR, 2021)
这篇文章是在组会上听到的,觉得真的是太太妙了。本文考虑的是半监督场景下的长尾分布问题,即此时我们不仅没有足够的有标记样本,而且这些有标记样本的分布还是长尾分布的(类别不平衡的)。 我当时心想,“好家伙,长尾分布问题和半监督问题两个这么难啃的骨头,你放在一块啃?”接下来就来看看本文作者是如何四两拨千斤的。
长尾分布(Long-Tailed Distribution)
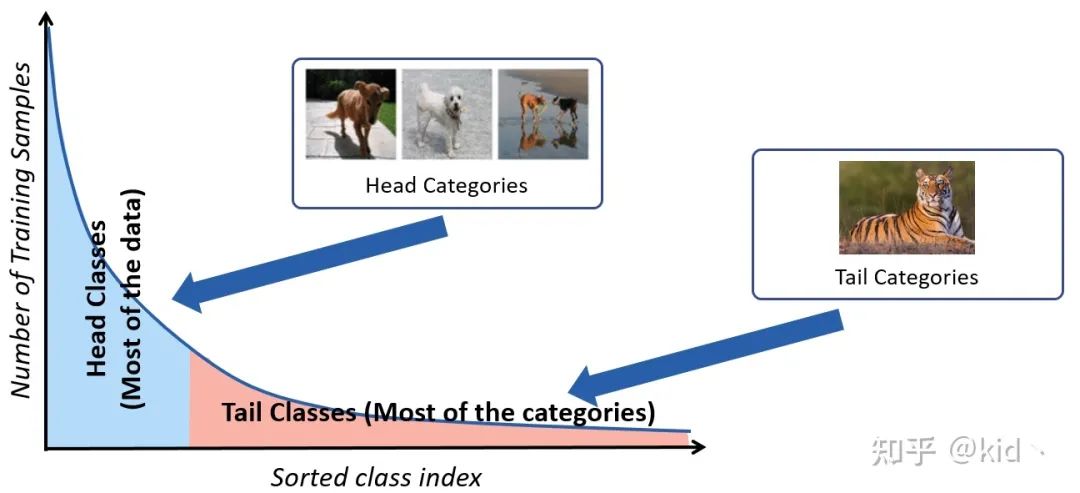
自然界中收集的样本通常呈长尾分布,即收集得到的绝大多数样本都属于常见的头部类别(例如猫狗之类的),而绝大部分尾部类别却只能收集到很少量的样本(例如熊猫、老虎),这造成收集得到的数据集存在着严重的类别不平衡问题(Class-Imbalanced),从而使得训练得到的模型严重的过拟合于头部类别。
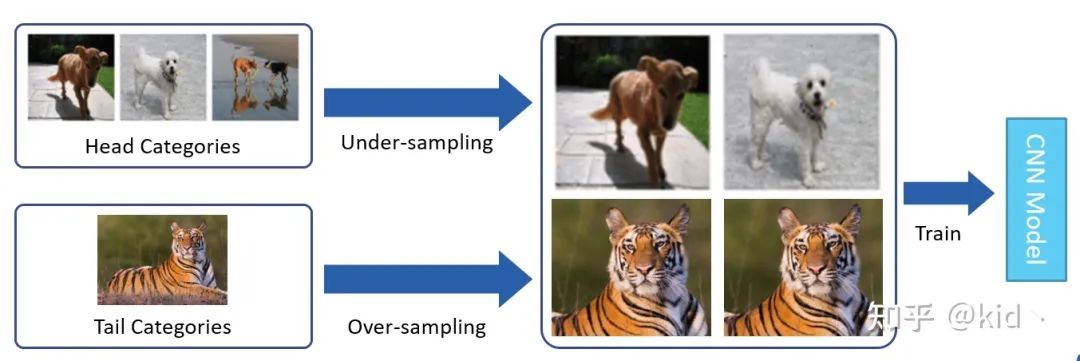
对于解决长尾分布的方法有很多,例如重采样 (Re-Sampling) 以及重加权 (Re-Weighting)。重采样简单来说可以划分为两类,一是通过对头部类别进行欠采样减少头部类别的样本数,二是通过过采样对尾部类别进行重复采样增加其样本数,从而使得类别“平衡”。但这样naive的方法存在的缺点也显而易见,即模型对尾部类别过拟合以及对头部类别欠拟合。
重加权方法的核心思想是类别少的样本应该赋予更大的权重,类别多的样本赋予更少的权重。此外有一篇文章[1]提出样本之间存在大量的信息冗余,因此提出了一个类别有效样本数的概念,还挺有意思,这里就不展开了。
动机(Motivation)
本文的问题设置更为复杂,考虑的是半监督场景下的长尾分布问题,即此时我们不仅没有足够的有标记样本,而且这些有标记样本的分布还是长尾分布的(类别不平衡的)。面对这么困难的问题,作者倒是不慌不忙,首先做了一个很有意思的实验。
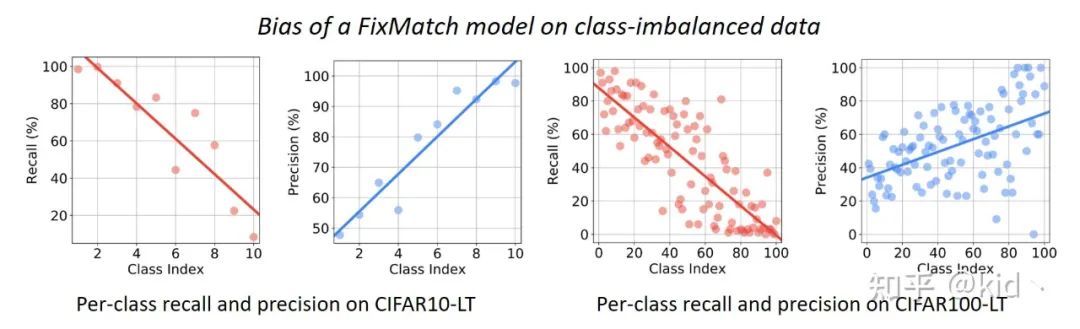
作者使用 FixMatch 模型 (一个解决半监督问题的SOTA方法) 分别在具有长尾分布的CIFAR10-LT (左边两张图) 以及 CIFAR100-LT (右边两张图) 上进行了实验。其中横坐标代表长尾分布的不同类别,越小的数字代表是头部类别,越大的数字代表是尾部类别;纵坐标对应红点和蓝点分别是 Recall 和 Precision。
实验现象表明,模型对头部类别的样本 Recall 很高,对尾部类别的 Recall 很低;模型对头部类别样本的 Precision 很低,但对尾部类别的 Precision 却很高。这是一个很常见的类别不平衡问题里的过拟合现象,换句话来说,模型对不确定性很高的尾部类别样本都预测成头部类别了。 举个例子,我在训练阶段喂入模型100张猫的图片以及10张狗的图片,在测试阶段时会发现对于模型把握不准的狗的图片都会预测成猫,只有模型特别有把握的狗的图片才会预测成狗,此时会造成猫这个类别的 Recall 会非常高 Precision 却会非常低,反之狗这个类别的 Recall 会非常低但 Precision 却会非常高。
这个实验现象是符合直观的,但是怎么来运用上述这一信息呢?作者开始了他的 “白嫖计划”
方法(Method)
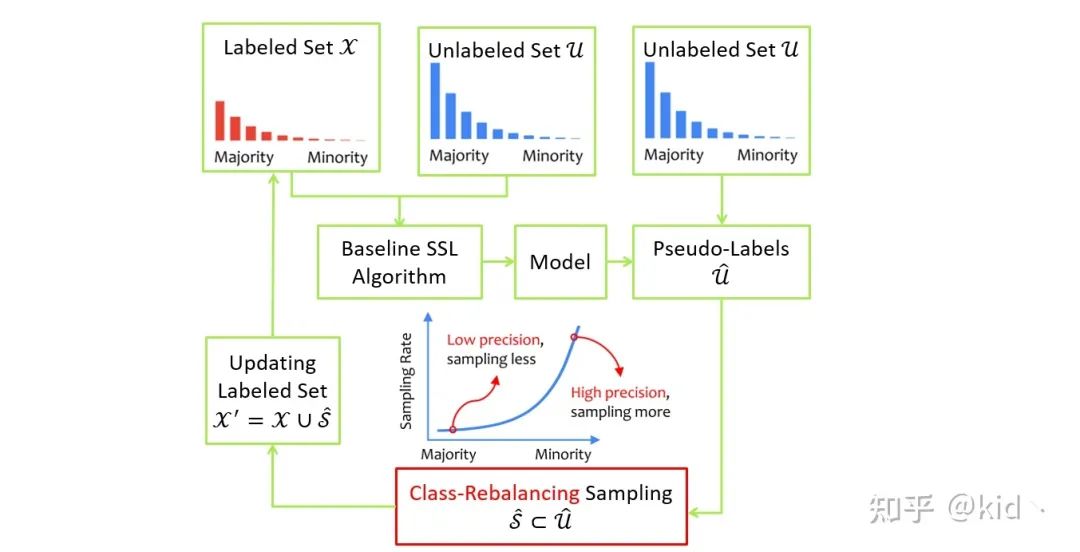
作者 follow 半监督学习中 self-training 的过程:
使用标准的 SSL 算法利用已标记集和未标记集的信息训练一个有效的模型 给未标记集 中的每个样本打上伪标记得到新的数据集 挑选出模型的预测类别属于尾部类别的样本作为候选集 加入到已标记集合中
最妙的一步在第三步,模型预测的类别属于尾部类别意味着这些样本的伪标记具有很高的置信度的(High precision),因为此时的模型是对头部类别过拟合的,此时模型还将某一样本预测为尾部类别说明该伪标记真的是该样本的 ground-truth。从另一方面,这一采样又巧妙的引入了尾部类别样本,从而缓解了类别不平衡问题。
讨论
首先用两字总结该方法,白嫖。感觉啥外部信息都没有,仅仅利用了模型学习长尾分布样本表现出来的规律,既“嫖”了未标记样本的真实标记,又“嫖”了尾部类别的样本。
后面深度思考了一下这件事:
这些被挑选出来的样本虽然有很大的可能具有正确的伪标记,但它可能不太具备代表性,即不能很好的代表这个类。换句话来说,模型对这些样本具有很大的置信度,即这些极可能是简单样本,对模型的学习帮助性可能不大,因此此时模型已经很确信能将其预测对了,此时再引入这些样本的loss其实很小,对模型的影响也不大。 针对前面所提到的,所以我认为可能性能的提升绝大部分来自于类别平衡了,当然正确的简单样本的引入也会对模型性能提升有帮助。 这个方法由此也会在半监督场景下作用明显,因此本来就没啥有标记样本,还如此的类别不平衡,此时给一些正确标记的虽然简单的样本对模型训练也是很有帮助的。
推荐阅读
2021-03-25

2021-03-18
2021-03-10


# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
