
你真的了解深度学习生成对抗网络(GAN)吗?
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

生成对抗网络(GANshttps://en.wikipedia.org/wiki/Generative_adversarial_network)是一类具有基于网络本身即可以生成数据能力的神经网络结构。由于GANs的强大能力,在深度学习领域里对它们的研究是一个非常热门的话题。在过去很短的几年里,它们已经从产生模糊数字成长到创造如真实人像般逼真的图像。


GANs属于生成模型的一类(https://en.wikipedia.org/wiki/Generative_model)。这意味着它们能够产生,或者说是生成完全新的“有效”数据。有效数据是指网络的输出结果应该是我们认为可以接受的目标。
举例说明,举一个我们希望为训练一个图像分类网络生成一些新图像的例子。当然对于这样的应用来说,我们希望训练图像越真实越好,可能在风格上与其他图像分类训练数据非常相似。
下面的图片展示的例子是GANs已经生成的一系列图片。它们看起来非常真实!如果没人告诉我们它们是计算机生成的,我们真可能认为它们是人工搜集的。

渐进式GAN生成的图像示例(图源:https://arxiv.org/pdf/1710.10196.pdf)
为了做到这些,GANs是以两个独立的对抗网络组成:生成器和判别器。当仅将嘈杂的图像阵列作为输入时,会对生成器进行训练以创建逼真的图像。判别器经过训练可以对图像是否真实进行分类。
GANs真正的能力来源于它们遵循的对抗训练模式。生成器的权重是基于判别器的损失所学习到的。因此,生成器被它生成的图像所推动着进行训练,很难知道生成的图像是真的还是假的。同时,生成的图像看起来越来越真实,判别器在分辨图像真实与否的能力变得越来越强,无论图像用肉眼看起来多么的相似。
从技术的角度来看,判别器的损失即是分类图像是真是假的错误值;我们正在测量它区分真假图像的能力。生成器的损失将取决于它在用假图像“愚弄”判别器的能力,即判别器仅对假图像的分类错误,因为生成器希望该值越高越好。
因此,GANs建立了一种反馈回路,其中生成器帮助训练判别器,而判别器又帮助训练生成器。它们同时变得更强。下面的图表有助于说明这一点。
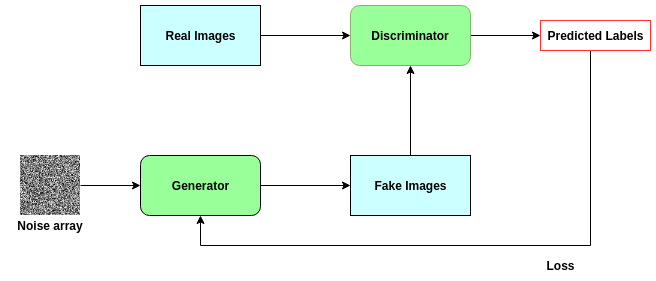
生成对抗网络的结构说明
现在我们将通过一个例子来展示如何使用PyTorch建立和训练我们自己的GAN!MNIST数据集包含60000个训练数据,数据是像素尺寸28x28的1-9的黑白数字图片。这个数据集非常适合我们的用例,同时也是非常普遍的用于机器学习的概念验证以及一个非常完备的集合。

MNIST 数据部分集,图源:https://www.researchgate.net/figure/A-subset-of-the-MNIST-database-of-handwritten-digits_fig4_232650721
我们将从 import 开始,所需的仅仅是PyTorch中的东西。
import torchfrom torch import nn, optimfrom torch.autograd.variable import Variableimport torchvisionimport torchvision.transforms as transforms
接下来,我们为训练数据准备DataLoader。请记住,我们想要的是为MNIST生成随机数字,即从0到9。因此,我也将需要为这10个数字建立标签。
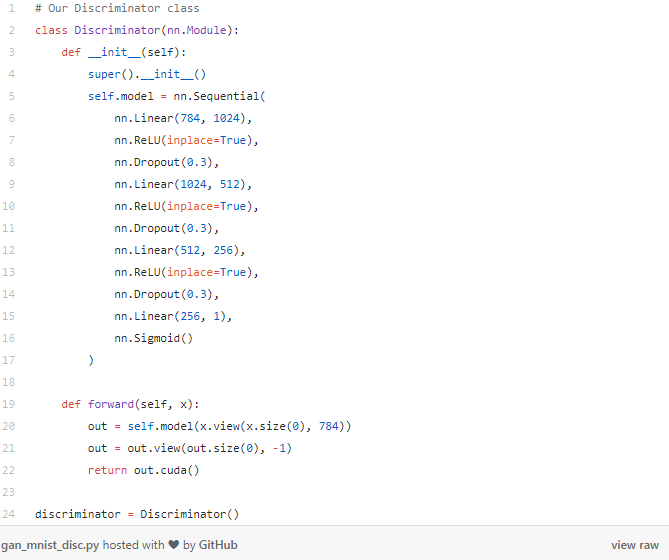
现在我们可以开始建立网络了,从下面的Discriminator(判别器)网络开始,回想一下,判别器网络是对图像真实与否进行分类——它是一个图像分类网络。因此,我们的输入是符合标准MNIST大小的图像:28x28像素。我们把这张图像展平成一个长度为784的向量。输出是一个单独的值,表示图像是否是实际的MNIST数字。
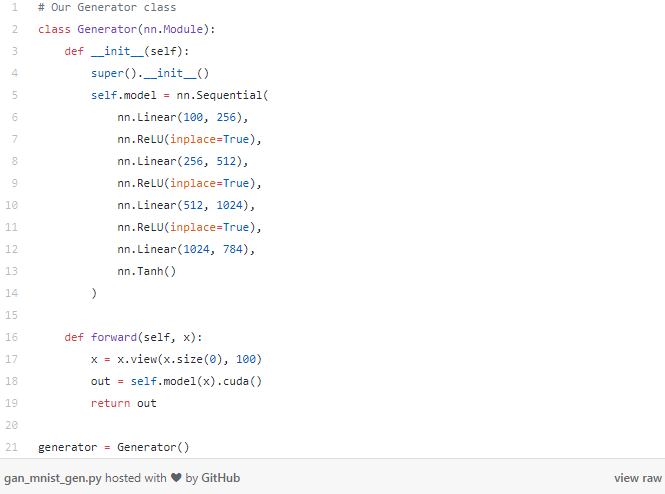
接下来到了生成器部分。生成器网络负责创建实际的图像——它可以从一个纯噪声的输入做到这一点!在这个例子中,我们要让生成器从一个长度为100的向量开始——注意:这只是纯随机噪声。从这个向量,我们的生成器将输出一个长度为784的向量,稍后我们可以将其重塑为标准MNIST的28x28像素。
1 . 损失函数 2 . 每个网络的优化器 3 . 训练次数 4 . batch数量
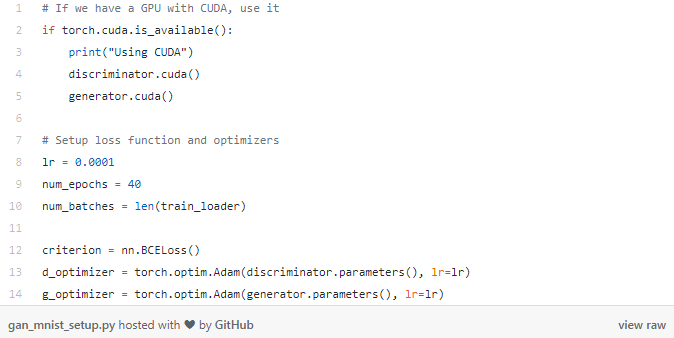

(2)接下来,我们将为生成器准备输入向量以便生成假图像。回想一下,我们的生成器网络采用长度为100的输入向量,这就是我们在这里所创建的向量。images.size(0)用于批处理大小。
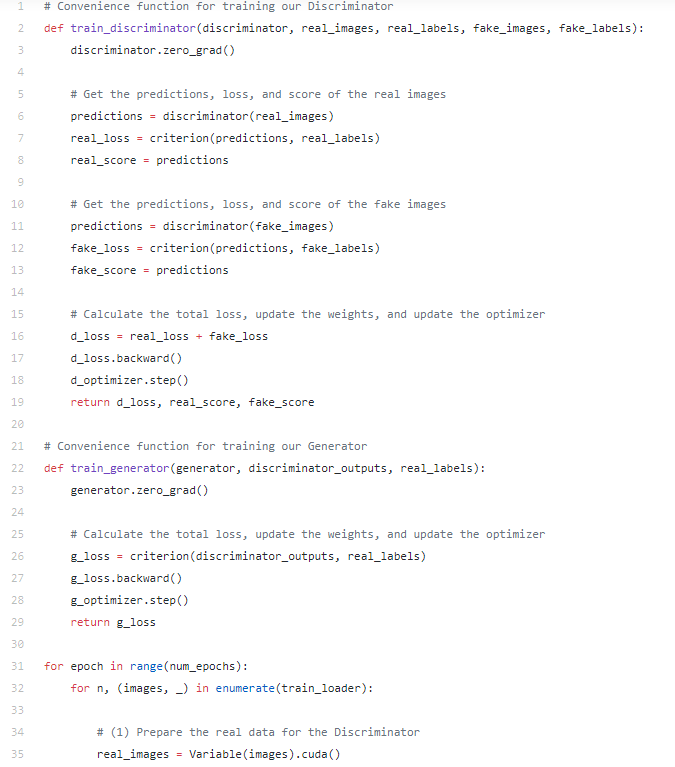
(3)通过从步骤(2)中创建的随机噪声数据向量,我们可以绕过这个向量到生成器来生成假的图像数据。这将结合我们从步骤1的实际数据来训练判别器。请注意,这次我们的标签向量全为0,因为0代表假图像的类标签。
(4)通过假的和真的图像以及它们的标签,我们可以训练我们的判别器进行分类。总损失将是假图像的损失+真图像的损失。
(5)现在我们的判别器已经更新,我们可以用它来进行预测。这些预测的损失将通过生成器反向传播,这样生成器的权重将根据它欺骗判别器的程度进行具体更新
(5a)生成一些假图像进行预测
(5b)使用判别器对假图像进行分批次预测并保存输出。
(6)使用判别器的预测训练生成器。注意,我们使用全为1的 _real_labels_ 作为目标,因为我们的生成器的目标是创建看起来真实的图像并且预测为1!因此,生成器的损失为0将意味着判别器预测全为1.
瞧,这就是我们训练GAN生成MNIST图像的全部代码!只需要安装PyTorch即可运行。下面的gif就是经过超过40个训练周期生成的图像。


* via https://towardsdatascience.com/an-easy-introduction-to-generative-adversarial-networks-6f8498dc4bcd
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~