
你真的了解 sync.Mutex吗
Mutex是一个互斥的排他锁,零值Mutex为未上锁状态,Mutex一旦被使用 禁止被拷贝。使用起来也比较简单
package main
import "sync"
func main() {
m := sync.Mutex{}
m.Lock()
defer m.Unlock()
// do something
}
Mutex有两种操作模式:
正常模式(非公平模式)
阻塞等待的goroutine保存在FIFO的队列中,唤醒的goroutine不直接拥有锁,需要与新来的goroutine竞争获取锁。因为新来的goroutine很多已经占有了CPU,所以唤醒的goroutine在竞争中很容易输;但如果一个goroutine获取锁失败超过1ms,则会将Mutex切换为饥饿模式。
饥饿模式(公平模式)
这种模式下,直接将等待队列队头goroutine解锁goroutine;新来的gorountine也不会尝试获得锁,而是直接插入到等待队列队尾。
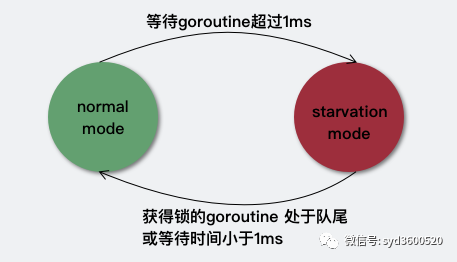
如果一个goroutine获得了锁,并且他在等待队列队尾 或者 他等待小于1ms,则会将Mutex的模式切换回正常模式。正常模式有更好的性能,新来的goroutine通过几次竞争可以直接获取到锁,尽管当前仍有等待的goroutine。而饥饿模式则是对正常模式的补充,防止等待队列中的goroutine永远没有机会获取锁。
其数据结构为:
type Mutex struct {
state int32 // 锁竞争的状态值
sema uint32 // 信号量
}
state代表了当前锁的状态、 是否是存在自旋、是否是饥饿模式、阻塞goroutine数量
mutexLocked = 1 << iota // mutex is locked
mutexWoken
mutexStarving
mutexWaiterShift = iota

mutex.state & mutexLocked 加锁状态 1 表示已加锁 0 表示未加锁
mutex.state & mutexWoken 唤醒状态 1 表示已唤醒状态 0 表示未唤醒
mutex.state & mutexStarving 饥饿状态 1 表示饥饿状态 0表示正常状态
mutex.state >> mutexWaiterShift得到当前goroutine数目
Lock
上锁大致分为fast-path和slow-path
Fast-path
lock通过调用atomic.CompareAndSwapInt32来竞争更新m.state,成功则获得锁;失败,则进入slow-path
func (m *Mutex) Lock() {
// Fast path: grab unlocked mutex.
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
return
}
// Slow path (outlined so that the fast path can be inlined)
m.lockSlow()
}
atomic.CompareAndSwapInt32正如签名一样,进行比较和交换操作,这过程是原子的
// CompareAndSwapInt32 executes the compare-and-swap operation for an int32 value.
func CompareAndSwapInt32(addr *int32, old, new int32) (swapped bool)
源码中我们并不能看到该函数的具体实现,他的实现跟硬件平台有关,我们可以查看汇编代码一窥究竟,go tool compile -S mutex.go也可以对二进制文件go tool objdump -s methodname binary
0x0036 00054 (loop.go:6) MOVQ AX, CX
0x0039 00057 ($GOROOT/src/sync/mutex.go:74) XORL AX, AX
0x003b 00059 ($GOROOT/src/sync/mutex.go:74) MOVL $1, DX
0x0040 00064 ($GOROOT/src/sync/mutex.go:74) LOCK
0x0041 00065 ($GOROOT/src/sync/mutex.go:74) CMPXCHGL DX, (CX)
0x0044 00068 ($GOROOT/src/sync/mutex.go:74) SETEQ AL
0x0047 00071 ($GOROOT/src/sync/mutex.go:74) TESTB AL, AL
0x0049 00073 ($GOROOT/src/sync/mutex.go:74) JEQ 150
0x004b 00075 (loop.go:8) MOVL $8, ""..autotmp_6+16(SP)
0x0053 00083 (loop.go:8) LEAQ sync.(*Mutex).Unlock·f(SB), AX
重点关注第5行CMPXCHGL DX, (CX)这个CMPXCHGL是x86和Intel架构中的compare and exchange指令,Java的那套AtomicXX底层也是依赖这个指令来保证原子性操作的。
所以我们看到Mutex是互斥排他锁且不可重入,当我们在一个goroutine获取同一个锁会导致死锁。
package main
import "sync"
func main() {
m := sync.Mutex{}
m.Lock()
//这里会导致死锁
m.Lock()
defer m.Unlock()
}
slow-path
如果goroutinefast-path失败,则调用m.lockSlow()进入slow-path,函数内部主要是一个for{}死循环,进入循环的goroutine大致分为两类:
新来的 gorountine被唤醒的 goroutine
Mutex默认为正常模式,若新来的goroutine抢占成功,则另一个就需要阻塞等待;阻塞等待一旦超过阈值1ms则会将Mutex切换到饥饿模式,这个模式下新来的goroutine只能阻塞等待在队列尾部,没有抢占的资格。当然等待阻塞->唤醒->参与抢占锁,这个过程显示不是很高效,所以这里有一个自旋的优化
当mutex处于正常模式且能够自旋,会让当前goroutine自旋等待,同时设置mutex.state的mutexWoken位为1,保证自旋等待的goroutine一定比新来goroutine更有优先权。这样unlock操作也会优先保证自旋等待的goroutine获取锁
golang对自旋做了些限制要求 需要:
多核CPU GOMAXPROCS>1 至少有一个运行的P并且local的P队列为空 感兴趣的可以跟下源码比较简单
func (m *Mutex) lockSlow() {
var waitStartTime int64
starving := false
awoke := false
iter := 0
old := m.state
for {
//饥饿模式下不能自旋,也没有资格抢占,锁是手递手给到等待的goroutine
if old&(mutexLocked|mutexStarving) == mutexLocked && runtime_canSpin(iter) {//当Mutex处于正常模式且能够自旋
//设置mutexWoken为1 告诉unlock操作,存在自旋gorountine unlock后不需要唤醒其他goroutine
if !awoke && old&mutexWoken == 0 && old>>mutexWaiterShift != 0 &&
atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) {
awoke = true
}
runtime_doSpin()
iter++
old = m.state
continue
}
// 自旋完了 还是没拿到锁
new := old
//当mutex处于正常模式,将new的mutexLocked设置为1 即准备抢占锁
if old&mutexStarving == 0 {
new |= mutexLocked
}
//加锁状态或饥饿模式下 新来的goroutine进入等待队列
if old&(mutexLocked|mutexStarving) != 0 {
new += 1 << mutexWaiterShift
}
//将Mutex切换为饥饿模式,若未加锁则不必切换
//Unlock操作希望饥饿模式存在等待者
if starving && old&mutexLocked != 0 {
new |= mutexStarving
}
if awoke {
// 当前goroutine自旋过 已被被唤醒,则需要将mutexWoken重置
if new&mutexWoken == 0 {
throw("sync: inconsistent mutex state")
}
new &^= mutexWoken //重置mutexWoken
}
if atomic.CompareAndSwapInt32(&m.state, old, new) {
// 当前goroutine获取锁前mutex处于未加锁 正常模式下
if old&(mutexLocked|mutexStarving) == 0 {
break // 使用CAS成功抢占到锁
}
// waitStartTime!=0表示当前goroutine是等待状态唤醒的
// 为了与第一次调用Lock的goroutine划分不同的优先级
queueLifo := waitStartTime != 0
if waitStartTime == 0 {
//开始记录等待时间
waitStartTime = runtime_nanotime()
}
// 将被唤醒但是没有获得锁的goroutine插入到当前等待队列队首
// 使用信号量阻塞当前goroutine
runtime_SemacquireMutex(&m.sema, queueLifo, 1)
// 当goroutine等待时间超过starvationThresholdNs,mutex进入饥饿模式
starving = starving || runtime_nanotime()-waitStartTime > starvationThresholdNs
old = m.state
if old&mutexStarving != 0 {
//如果当前goroutine被唤醒且mutex处于饥饿模式 则将锁手递手交给当前goroutine
if old&(mutexLocked|mutexWoken) != 0 || old>>mutexWaiterShift == 0 {
throw("sync: inconsistent mutex state")
}
//等待状态的goroutine - 1
delta := int32(mutexLocked - 1< //如果等待时间小于1ms 或 当前goroutine是队列中最后一个
if !starving || old>>mutexWaiterShift == 1 {
// 退出饥饿模式
delta -= mutexStarving
}
atomic.AddInt32(&m.state, delta)
break
}
awoke = true
iter = 0
} else {
old = m.state
}
}
}
Unlock
解锁分两种情况
当前只有一个goroutine占有锁 unlock完 直接结束
func (m *Mutex) Unlock() {
// 去除加锁状态
new := atomic.AddInt32(&m.state, -mutexLocked)
if new != 0 {//存在等待的goroutine
m.unlockSlow(new)
}
}
unlock完毕mutex.state!=0 则存在以下可能 直接将锁交给等待队列的第一个goroutine 当前存在等待goroutine 然后唤醒它 但不是第一个goroutine 当前存在自旋等待的goroutine 则不唤醒其他等待gorotune 正常模式下 饥饿模式下
func (m *Mutex) unlockSlow(new int32) {
//未加锁的情况下不能多次调用unlock
if (new+mutexLocked)&mutexLocked == 0 {
throw("sync: unlock of unlocked mutex")
}
if new&mutexStarving == 0 {//正常模式下
old := new
for {
//没有等待的goroutine 或 已经存在一个获得锁 或被唤醒 或处于饥饿模式下不需要唤醒任何处于等待的goroutine
if old>>mutexWaiterShift == 0 || old&(mutexLocked|mutexWoken|mutexStarving) != 0 {
return
}
// 等待状态goroutine数量-1 并设置唤醒状态为1 然后唤醒一个等待goroutine
new = (old - 1< if atomic.CompareAndSwapInt32(&m.state, old, new) {
//唤醒一个阻塞的goroutine 但不是第一个等待者
runtime_Semrelease(&m.sema, false, 1)
return
}
old = m.state
}
} else {
//饥饿模式下手递手将锁交给队列第一个等待的goroutine
//即使期间有新来的goroutine到来,只要处于饥饿模式 锁就不会被新来的goroutine抢占
runtime_Semrelease(&m.sema, true, 1)
}
}
信号量
上面可以看到Mutex对goroutine的阻塞和唤醒操作是利用semaphore来实现的,大致的思路是:Go runtime维护了一个全局的变量semtable,它保持了所有的信号量
// Prime to not correlate with any user patterns.
const semTabSize = 251
var semtable [semTabSize]struct {
root semaRoot
pad [cpu.CacheLinePadSize - unsafe.Sizeof(semaRoot{})]byte
}
每个信号量都由一个变量地址指定,Mutex的栗子里就是mutex.sema的地址
type semaRoot struct {
lock mutex
treap *sudog // root of balanced tree of unique waiters.
nwait uint32 // Number of waiters. Read w/o the lock.
}
大致画了下其数据结构
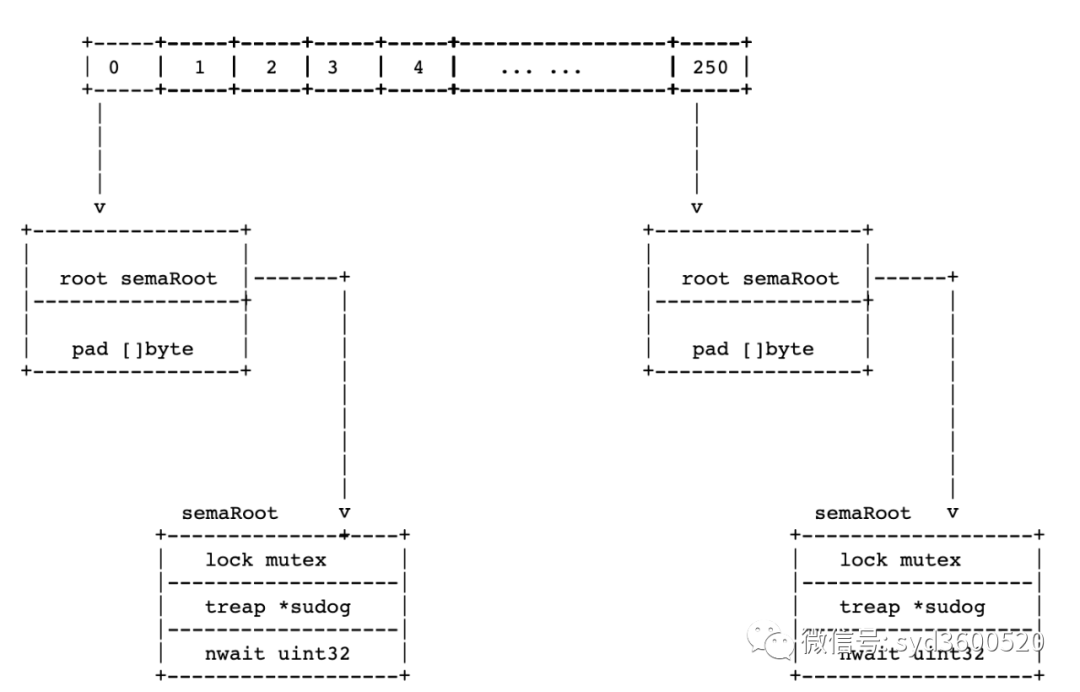
当 goroutine未获取到锁,需要阻塞时调用sync.runtime_SemacquireMutex进入阻塞逻辑
//go:linkname sync_runtime_SemacquireMutex sync.runtime_SemacquireMutex
func sync_runtime_SemacquireMutex(addr *uint32, lifo bool, skipframes int) {
semacquire1(addr, lifo, semaBlockProfile|semaMutexProfile, skipframes)
}
func semacquire1(addr *uint32, lifo bool, profile semaProfileFlags, skipframes int) {
gp := getg()
if gp != gp.m.curg {
throw("semacquire not on the G stack")
}
// 低成本case
// 若addr大于1 并通过CAS -1 成功,则获取信号量成功 不需要阻塞
if cansemacquire(addr) {
return
}
// 复杂 case:
// 增加等待goroutine数量
// 再次尝试cansemacquire 成功则返回
// 失败则将自己作为一个waiter入队
// sleep
// (waiter descriptor is dequeued by signaler)
s := acquireSudog()
root := semroot(addr)
t0 := int64(0)
s.releasetime = 0
s.acquiretime = 0
s.ticket = 0
if profile&semaBlockProfile != 0 && blockprofilerate > 0 {
t0 = cputicks()
s.releasetime = -1
}
if profile&semaMutexProfile != 0 && mutexprofilerate > 0 {
if t0 == 0 {
t0 = cputicks()
}
s.acquiretime = t0
}
for {
lock(&root.lock)
// 给nwait+1 这样semrelease中不会进低成本路径了
atomic.Xadd(&root.nwait, 1)
// 检查 cansemacquire 避免错过唤醒
if cansemacquire(addr) {
atomic.Xadd(&root.nwait, -1)
unlock(&root.lock)
break
}
//cansemacquire之后的semrelease都可以知道我们正在等待
//上面设置了nwait,所以会直接进入sleep 即goparkunlock
root.queue(addr, s, lifo)
goparkunlock(&root.lock, waitReasonSemacquire, traceEvGoBlockSync, 4+skipframes)
if s.ticket != 0 || cansemacquire(addr) {
break
}
}
if s.releasetime > 0 {
blockevent(s.releasetime-t0, 3+skipframes)
}
releaseSudog(s)
}
如果addr大于1并通过CAS-1成功则获取信号量成功,直接返回
否则通过对信号量地址偏移取模&semtable[(uintptr(unsafe.Pointer(addr))>>3)%semTabSize].root拿到semaRoot(这里个3和251 没有明白为什么是这两个数???),semaRoot包含了一个sudog链表和一个nwait整型字段。nwait表示该信号量上阻塞等待的g的数量,同时为了保证线程安全需要一个互斥量来保护链表。
这里需要注意的是 此处的runtime.mutex并不是之前所说的sync.Mutex,是内部的一个简单版本
简单来说,sync_runtime_Semacquire就是wait知道*s>0 然后原子的递减它,来完成同步过程中简单的睡眠原语
当 goroutine要释放锁 唤醒等待的g时调用sync.runtime_Semrelease
//go:linkname sync_runtime_Semrelease sync.runtime_Semrelease
func sync_runtime_Semrelease(addr *uint32, handoff bool, skipframes int) {
semrelease1(addr, handoff, skipframes)
}
func semrelease1(addr *uint32, handoff bool, skipframes int) {
root := semroot(addr)
atomic.Xadd(addr, 1)
// Easy case: no waiters?
// 这个检查必须发生在xadd之后 避免错过唤醒
// (see loop in semacquire).
if atomic.Load(&root.nwait) == 0 {
return
}
// Harder case: 搜索一个waiter 并唤醒它
lock(&root.lock)
if atomic.Load(&root.nwait) == 0 {
// count值已经被另一个goroutine消费了
// 所以不需要唤醒其他goroutine
unlock(&root.lock)
return
}
s, t0 := root.dequeue(addr)
if s != nil {
atomic.Xadd(&root.nwait, -1)
}
unlock(&root.lock)
if s != nil { // May be slow, so unlock first
acquiretime := s.acquiretime
if acquiretime != 0 {
mutexevent(t0-acquiretime, 3+skipframes)
}
if s.ticket != 0 {
throw("corrupted semaphore ticket")
}
if handoff && cansemacquire(addr) {
s.ticket = 1
}
readyWithTime(s, 5+skipframes)
}
}
关于信号量更深层的研究可以看下semaphore in plan9
总结
通过看源码发现个有意思的问题:如果goroutine g1加的锁 可以被另一个goroutine g2解锁,但是等到g1解锁的时候就会panic
推荐阅读