
基于TensorRT完成NanoDet模型部署
【GiantPandaCV导语】本文为大家介绍了一个TensorRT int8 量化部署 NanoDet 模型的教程,并开源了全部代码。主要是教你如何搭建tensorrt环境,对pytorch模型做onnx格式转换,onnx模型做tensorrt int8量化,及对量化后的模型做推理,实测在1070显卡做到了2ms一帧!
NanoDet简介
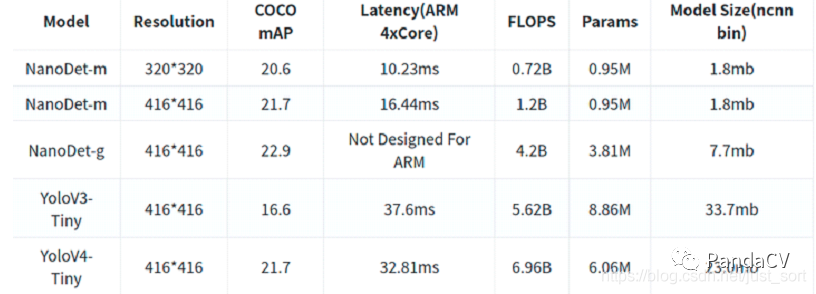
NanoDet (https://github.com/RangiLyu/nanodet)是一个速度超快和轻量级的Anchor-free 目标检测模型;和yolov4 tiny作比较(如下图),精度相当,但速度却快了1倍;对于速度优先的场景,nanodet无疑是一个好的选择。
NanoDet损失函数GFocal Loss
目前比较强力的one-stage anchor-free的检测器(以FCOS,ATSS为代表)基本会包含3个表示:
分类表示 检测框表示 检测框的质量估计(在FCOS/ATSS中,目前采用centerness,当然也有一些其他类似的工作会采用IoU,这些score基本都在0~1之间)
存在问题1:classification score 和 IoU/centerness score 训练测试不一致。存在问题2:bbox regression 表示不够灵活,没有办法建模复杂场景下的uncertainty
对于第一个问题,为了保证training和test一致,同时还能够兼顾分类score和质量预测score都能够训练到所有的正负样本,作者提出一个方案:就是将两者的表示进行联合
对于第二个问题,作者选择直接回归一个任意分布来建模框的表示。一句话总结:基于任意one-stage 检测器上,调整框本身与框质量估计的表示,同时用泛化版本的GFocal Loss训练该改进的表示,无cost涨点(一般1个点出头)AP
NanoDet 检测头FCOS架构
FCOS系列使用了共享权重的检测头,即对FPN出来的多尺度Feature Map使用同一组卷积预测检测框,然后每一层使用一个可学习的Scale值作为系数,对预测出来的框进行缩放。FCOS的检测头使用了4个256通道的卷积作为一个分支,也就是说在边框回归和分类两个分支上一共有8个c=256的卷积,计算量非常大。为了将其轻量化,作者首先选择使用深度可分离卷积替换普通卷积,并且将卷积堆叠的数量从4个减少为2组。在通道数上,将256维压缩至96维,之所以选择96,是因为需要将通道数保持为8或16的倍数,这样能够享受到大部分推理框架的并行加速。最后,借鉴了yolo系列的做法,将边框回归和分类使用同一组卷积进行计算,然后split成两份。
FPN层改进PAN
原版的PAN和yolo中的PAN,使用了stride=2的卷积进行大尺度Feature Map到小尺度的缩放。作者为了轻量化的原则,选择完全去掉PAN中的所有卷积,只保留从骨干网络特征提取后的1x1卷积来进行特征通道维度的对齐,上采样和下采样均使用插值来完成。与yolo使用的concatenate操作不同,作者选择将多尺度的Feature Map直接相加,使得整个特征融合模块的计算量变得非常非常小。
NanoDet 骨干网络ShuffleNetV2(原始版本)
作者选择使用ShuffleNetV2 1.0x作为backbone,去掉了最后一层卷积,并且抽取8、16、32倍下采样的特征输入进PAN做多尺度的特征融合
环境配置
环境配置和之前的文章《基于TensorRT量化部署yolov5 4.0模型》类似 ubuntu:18.04 cuda:11.0 cudnn:8.0 tensorrt:7.2.16 OpenCV:3.4.2 cuda,cudnn,tensorrt和OpenCV安装包(编译好了,也可以自己从官网下载编译)可以从链接: https://pan.baidu.com/s/1dpMRyzLivnBAca2c_DIgGw 密码: 0rct cuda安装 如果系统有安装驱动,运行如下命令卸载 sudo apt-get purge nvidia* 禁用nouveau,运行如下命令 sudo vim /etc/modprobe.d/blacklist.conf 在末尾添加 blacklist nouveau 然后执行 sudo update-initramfs -u chmod +x cuda_11.0.2_450.51.05_linux.run sudo ./cuda_11.0.2_450.51.05_linux.run 是否接受协议: accept 然后选择Install 最后回车 vim ~/.bashrc 添加如下内容: export PATH=/usr/local/cuda-11.0/bin:$PATH export LD_LIBRARY_PATH=/usr/local/cuda-11.0/lib64:$LD_LIBRARY_PATH source ~/.bashrc 激活环境 cudnn 安装 tar -xzvf cudnn-11.0-linux-x64-v8.0.4.30.tgz cd cuda/include sudo cp *.h /usr/local/cuda-11.0/include cd cuda/lib64 sudo cp libcudnn* /usr/local/cuda-11.0/lib64 tensorrt及OpenCV安装 定位到用户根目录 tar -xzvf TensorRT-7.2.1.6.Ubuntu-18.04.x86_64-gnu.cuda-11.0.cudnn8.0.tar.gz cd TensorRT-7.2.1.6/python,该目录有4个python版本的tensorrt安装包 sudo pip3 install tensorrt-7.2.1.6-cp37-none-linux_x86_64.whl(根据自己的python版本安装) pip install pycuda 安装python版本的cuda 定位到用户根目录 tar -xzvf opencv-3.4.2.zip 以备推理调用
NanoDet 模型转换onnx
pip install onnx pip install onnx-simplifier git clone https://github.com/Wulingtian/nanodet.git cd nanodet cd config 配置模型文件(注意激活函数要换为relu!tensorrt支持relu量化),训练模型 定位到nanodet目录,进入tools目录,打开export.py文件,配置cfg_path model_path out_path三个参数 定位到nanodet目录,运行 python tools/export.py 得到转换后的onnx模型 python3 -m onnxsim onnx模型名称 nanodet-simple.onnx 得到最终简化后的onnx模型
onnx模型转换为 int8 tensorrt引擎
git clone https://github.com/Wulingtian/nanodet_tensorrt_int8_tools.git(求star) cd nanodet_tensorrt_int8_tools vim convert_trt_quant.py 修改如下参数 BATCH_SIZE 模型量化一次输入多少张图片 BATCH 模型量化次数 height width 输入图片宽和高 CALIB_IMG_DIR 训练图片路径,用于量化 onnx_model_path onnx模型路径 python convert_trt_quant.py 量化后的模型存到models_save目录下
tensorrt模型推理
git clone https://github.com/Wulingtian/nanodet_tensorrt_int8.git(求star) cd nanodet_tensorrt_int8 vim CMakeLists.txt 修改USER_DIR参数为自己的用户根目录 vim nanodet_infer.cc 修改如下参数 output_name模型有一个输出 我们可以通过netron查看模型输出名 pip install netron 安装netron vim netron_nanodet.py 把如下内容粘贴 import netron netron.start('此处填充简化后的onnx模型路径', port=3344) python netron_nanodet.py 即可查看 模型输出名 trt_model_path 量化的的tensorrt推理引擎(models_save目录下trt后缀的文件) test_img 测试图片路径 INPUT_W INPUT_H 输入图片宽高 NUM_CLASS 训练的模型有多少类 NMS_THRESH nms阈值 CONF_THRESH 置信度阈值 参数配置完毕 mkdir build cd build cmake .. make ./NanoDetEngine 输出平均推理时间,以及保存预测图片到当前目录下,至此,部署完成!
预测结果展示

欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:
为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。