
Datapane 008 - 团队版
Datapane 团队版 - 简介
Python 开源生态系统的灵活与强大已被众多数据团队认可,但把 Python 分析结果转化为可分享、自动化、能提供商业价值的最后一步却难的让人望而却步。Datapane 团队版的 API 平台利用 Python 实现在公司内部生成与分享数据报告。让数据团队使用自己熟悉的工具驱动商业决策,让相关方自行浏览分析报告,无需每次都要等待别人生成报告。
除了安全、可验证的报告分享机制之外,Datapane 团队版还支持在云端部署 Python 脚本和 Jupyter Notebook,自动生成报告。通过网页表单输入参数,即可生成自定义报告,还可以按计划定时生成报告,或通过我们的 HTTP 和 Python API 按需生成报告。
验证与分享
Datapane 团队版为分享报告、脚本、Blob 对象、密钥等对象提供了安全、可验证的方式。Datapane 虚拟机(如,https://acme.datapane.net)的每个用户都有自己私有的、受密码保护的账户。
每个 Datapane 虚拟机都存在于独立的数据库租户里,因此,不同虚拟机之间的账户并不互通,同一个账户不能在不同虚拟机之间进行验证。
Datapane 虚拟机上创建的项目都有 visibility 设置项,用于管理有访问权限的用户。这些 visibility 选项包括 PUBLIC、PRIVATE、ORG。创建对象时,一般都要配置这个选项,默认值是 ORG。
以下列报告为例:
# 任何人都可见
report.publish(visibility='PUBLIC')
# 只有在 Datapane 虚拟机上的注册用户可见
report.publish(visibility='ORG')
# 只有账户所有者本人可见,其它用户不可见
report.publish(visibility='PRIVATE')
在网页界面上也可以设置报告或脚本的 visibility 选项。

访问 Token
如需向客户、合同商等外部人员分享私有报告,请用 Share 按钮旁的链接生成带安全标记的 Token。这个链接包含的 Token 可以让任何持有此链接的人访问报告,无需注册 Datapane 账户。
此 Token 也适用于嵌入式报告,比如,嵌入到 Confluence 或网页等平台的报告。为了安全起见,24 小时后会重置访问 Token,因此,这种方式不适合长期分享。
下一节,介绍如何部署 Datapane 团队版的脚本与 Jupyter Notebook。
脚本与 Jupyter 部署
简介
Datapane 团队版支持脚本运行器,可在云端通过参数运行部署的 Python 脚本或 Jupyter Notebook。即,除在本机生成报告之外,还支持部署后自动生成报告。
脚本或 Notebook 部署后,可用以下三种方式运行:
网页表单
通过界面友好的网页表单输入参数即可运行脚本,为相关方创建的交互、自助式报告工具。
参数与表单(详见下文)
计划定时
使用脚本按计划定时生成、更新报告,创建“实时”仪表盘与自动报告。
按计划运行报告(详见下文)
调用 API
通过 API 生成报告,利用 Slack、Teams 或您自己产品中触发事件生成报告。
部署脚本
通过 CLI 把调用 Report.publish 方法(参阅创建报告小节)创建报告的 Python 脚本或 Notebook 部署到 Datapane。下面以上文中的新冠脚本为例,用 Datapane 的 CLI 部署该脚本。通过 Datapane 网页界面运行脚本时,用该代码发布的报告将返回给用户。
建议:一个脚本只创建一个报告。虽然一个脚本里可以创建多个报告,但网页界面只能追踪每个脚本里最后的报告。
# simple_script.py
import pandas as pd
import altair as alt
import datapane as dp
dataset = pd.read_csv('https://covid.ourworldindata.org/data/owid-covid-data.csv')
df = dataset.groupby(['continent', 'date'])['new_cases_smoothed_per_million'].mean().reset_index()
plot = alt.Chart(df).mark_area(opacity=0.4, stroke='black').encode(
x='date:T',
y=alt.Y('new_cases_smoothed_per_million:Q', stack=None),
color=alt.Color('continent:N', scale=alt.Scale(scheme='set1')),
tooltip='continent:N'
).interactive().properties(width='container')
dp.Report(
dp.Plot(plot),
dp.Table(df)
).publish(name='covid_report', open=True)
部署报告时,使用 Datapane 的 CLI。
datapane script deploy --script=simple_script.py --name=covid_script
Uploaded simple_script.py to https://acme.datapane.net/leo/scripts/covid_script/
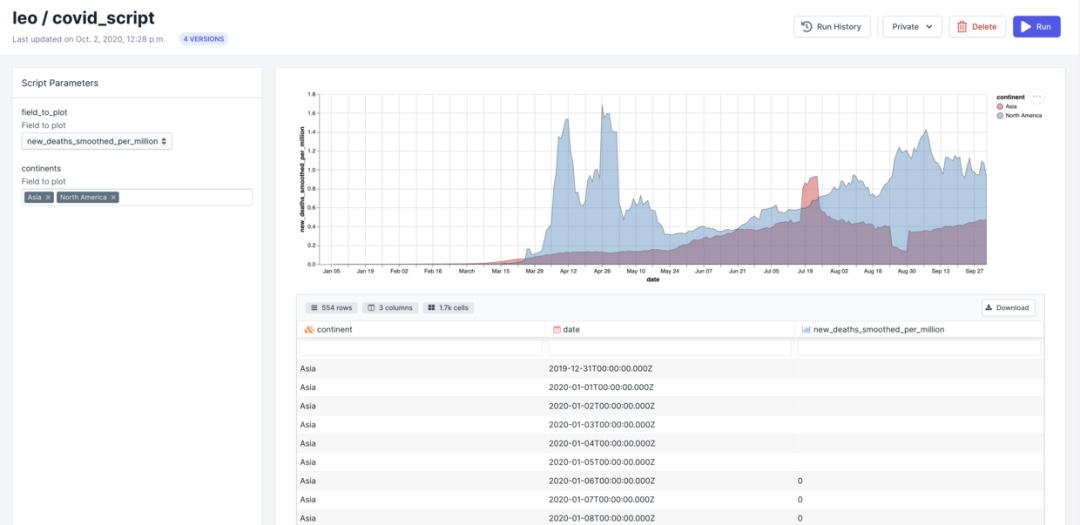
该操作把脚本部署至私有虚拟机,您可以把它分享给别人。分享脚本后,点击 Run 按钮,就可以用上面的示例代码动态生成报告。
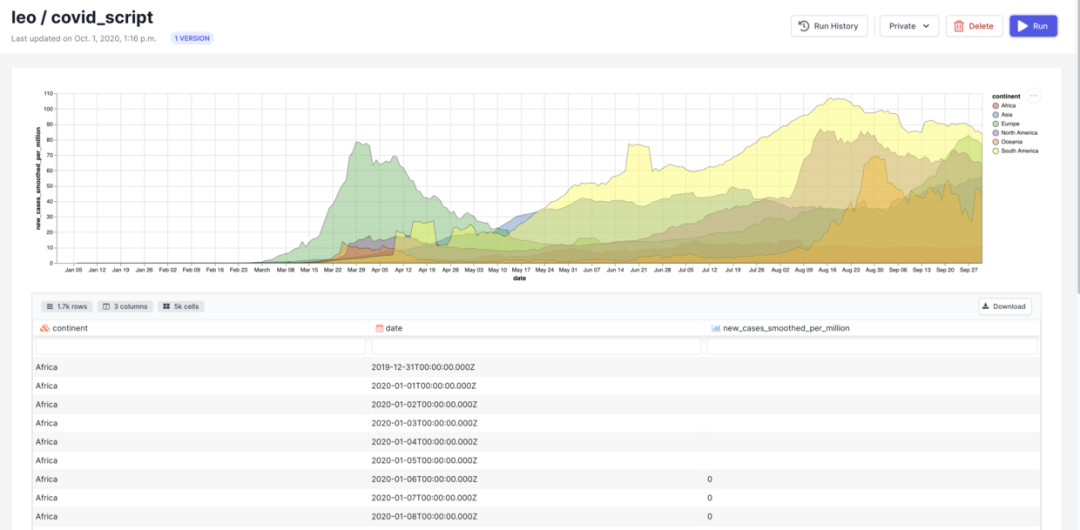
每次运行脚本,都会重新提取新冠数据,并生成全新的报告,继而可以用于分享或嵌入到其它平台。
配置
上例部署了单一脚本,并通过命令行参数设置了脚本名称与文件位置。对于单一脚本,这种操作没有问题,但很多时候,还需要配置脚本的其它选项,比如参数定义、设置部署文件与文件夹、Python、系统需求等。
Datapane 的配置文件是 datapane.yaml。运行 deploy 命令时,Datapane 自动查找这个文件。继续下一步操作前, 先用 script init 命令创建项目架构,该命令将生成 datapane.yaml 示例文件及示例脚本文件。
~/C/d/d/my-new-proj> datapane script init
Created script 'my-new-proj', edit as needed and upload
~/C/d/d/my-new-proj> ls
datapane.yaml dp-script.py
下一步操作要使用的是上例中的脚本文件,所以请删除该命令生成的 dp-script.py 示例脚本文件。这里替换了默认脚本,因此,要在 datapane.yaml 的 script 项里指定脚本的文件名。在这个文件里,还可以指定报告名称。
# datapane.yaml
name: covid_script
script: simple_script.py # this could also be ipynb if it was a notebook
在这个文件夹里运行 datapane script deploy 命令,Datapane 使用 datapane.yaml 里的设置部署代码。因为该文件里设置的脚本名称与上例中的名称一样,该操作将生成 covid_script 脚本的第 2 个版本。
与报告类似,脚本也支持多版本,可以生成或迭代单一 Python 项目。
下一节,介绍向脚本添加参数,基于用户输入的内容动态生成报告。
脚本参数
脚本支持参数,通过网页表单或 API 可以动态生成报告。
概览
相关方通常需要配置脚本,以实现自助生成报告。Datapane 允许向脚本中传递参数,并以网页表单的形式展现给终端用户。这种方式让其他在虚拟机上有账户的用户不必操心代码、Notebook、设置 Python 环境,就能够生成报告。
运行与参数
在 datapane.yaml 配置文件里,写清楚输入内容的架构与配置即可定义可以输入哪些参数。在 Python 代码中,在本文件里定义的这些参数通过 Params 字典访问。用 Params.get([value_name], [default_value]),就能从字典里提取所需的项目。
这里继续沿用上节的例子,提取的数据集里还包含一些用户在可视化时需要的其它参数。下面将 new_case_smoothed_per_million、new_deaths_smoothed_per_million、median_age、gdp_per_capita 等内容添加到终端用户可选择的内容里。此外,终端用户还要能为可视图选择 continents 的子集。
基于以上内容,要向 datapane.yaml 的 parameters 项中添加两个参数:plot_field 与 continents。要配置终端用户的表单,需要选择 widget 类型。针对上例,选择 enum (下拉菜单,用户必须选择其中一个选项)、list(用户可以选择预定义列表中的一项或多项内容)。还可以为每项输入内容与描述设置默认参数。
参数配置与可用的字段请参与 API 参考手册(下期发布)
# datapane.yaml
name: covid_script
script: simple_script.py # this could also be ipynb if it was a notebook
parameters:
- name: field_to_plot
description: Field to plot
type: enum
choices:
- new_cases_smoothed_per_million
- new_deaths_smoothed_per_million
- median_age
- gdp_per_capita
- name: continents
description: Field to plot
type: list
choices:
- Africa
- Asia
- Europe
- Oceania
- North America
- South America
default:
- Asia
- North America
设置完成后,在 Datapane 虚拟机上运行时,就可以用 Params 对象,基于用户的输入自定义数据与可视图。
# simple_script.py
import pandas as pd
import altair as alt
import datapane as dp
dataset = pd.read_csv('https://covid.ourworldindata.org/data/owid-covid-data.csv')
# 获取输入的参数
continents = dp.Params.get('continents', ['Asia', 'North America'])
field_to_plot = dp.Params.get('field_to_plot', 'new_cases_smoothed_per_million')
df = dataset[dataset.continent.isin(continents)].groupby(['continent', 'date'])[plot_field].mean().reset_index()
plot = alt.Chart(df).mark_area(opacity=0.4, stroke='black').encode(
x='date:T',
y=alt.Y(field_to_plot, stack=None),
color=alt.Color('continent:N', scale=alt.Scale(scheme='set1')),
tooltip='continent:N'
).interactive().properties(width='container')
dp.Report(
dp.Plot(plot),
dp.Table(df)
).publish(name='covid_report', open=True)
运行 script deploy 命令,Datapane 会部署脚本的新版本,并用定义的参数生成下图所示的表单:
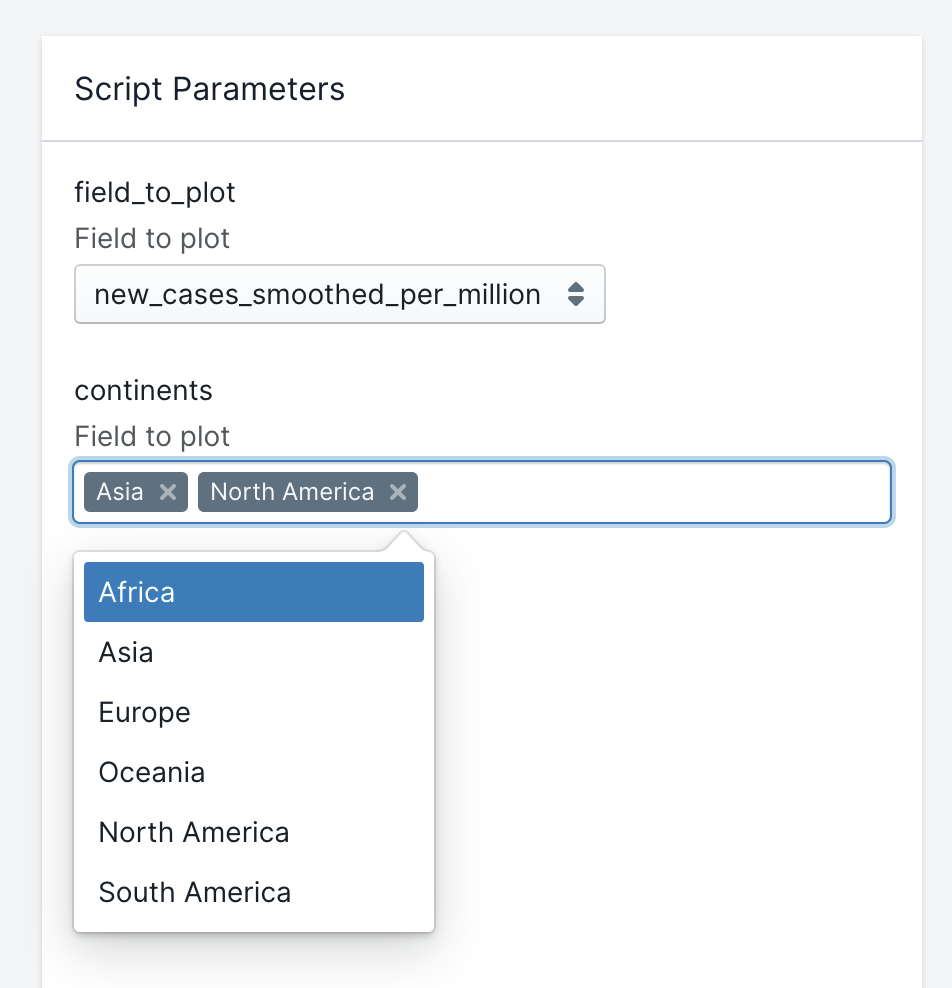
终端用户可以输入参数,并基于这些字段自助生成自定义报告。
定时运行报告
按计划安排的节奏生成报告,并创建实时仪表盘。
有时,需要按计划让部署到 Datapane 的脚本或 Jupyter Notebook 自动生成报告 -- 比如,每天从数据仓库中更新数据,或定期查询内部 API 的变化。
新建计划使用 create 命令:
$ datapane schedule create [-p ]
create 命令接受三个参数:
script:运行的脚本文件名cron:crontab 显示计划的间隔时间parameters(可选):针对支持参数的脚本,按计划运行脚本时,需要提供参数的键值对列表
生成 crontab 时遇到任何问题,请参阅 http://corntab.com/。
假设每天上午 9 点要运行新冠脚本,请用下列命令:
$ datapane schedule [your-username]/covid_script "0 9 * * MON"
Created schedule: 3 (https://acme.datapane.net/api/schedules/3/)
使用 -p 选项,可以加入任意输入的参数。
$ datapane schedule [your-username]/covid_script "0 9 * * MON" -p '{"continents": ["Europe"], "field_to_plot": "gdp_per_capita"}'
Created schedule: 4 (https://acme.datapane.net/api/schedules/4/)
查看有效的计划,请用 list 命令:
$ datapane schedule list
Available Schedules:
id script cron parameter_vals
---- ---------------------------------------------- ----------- -------------------------------------------------------------
3 https://acme.datapane.net/api/scripts/X0AEQAd/ 0 9 * * MON {}
4 https://acme.datapane.net/api/scripts/X0AEQAd/ 0 9 * * MON {"continents": ["Europe"], "field_to_plot": "gdp_per_capita"}
删除已有的计划,请用 delete 命令:
$ datapane schedule delete 3
Deleted schedule 3
使用定时报告
报告支持多个版本,因此,可以实现定期自动更新,创建实时报告。浏览脚本发布的报告时,将自动更新,并显示最新版本的报告。同样,报告(或报告里的某个元素)内嵌在 Confluence、Salesforce 等第三方平台时,嵌入的内容也会自动更新。
依赖项与需求项
Python 脚本或 Notebook 有时会调用外部支持库。Datapane 支持在部署脚本时,添加本机文件与文件夹;还支持设置 pip 需求项,用以实现在 Datapane 上运行脚本时调用各种支持库;还支持指定脚本运行的 Docker 容器。所有这些功能都可以在 datapane.yaml 文件里配置。
Python 依赖项
假设我们要创建一个提取金融数据的报告工具,可能会调用 Python 的 yfinance 支持库。为实现这一功能,要在 datapane.yaml 文件的 requirements 项下添加该支持库。
# datapane.yaml
...
requirements:
- yfinance
附加文件与文件夹
此外,还可以添加本机的 Python 文件或文件夹。假设要在脚本里调用一个独立的 Python 文件,stock_sacler.py,该文件用于评估股票价值,或要在 Python 中调用某个文件夹里的 SQL 脚本。
~/C/d/d/my-new-proj> ls
dp-script.py datapane.yaml stock_scaler.py
将这个文件添加到 include 项下,就可以把它部署到服务器。
# datapane.yaml
...
include:
- stock_scaler.py
Docker 依赖项
默认条件下,Datapane 上的脚本在我们提供的标准 Docker 容器里运行。该容易包含了下列支持库:
seaborn == 0.10.*
altair-recipes ~= 0.8.0
git+https://github.com/altair-viz/altair_pandas@master#egg=altair-pandas
git+https://github.com/altair-viz/pdvega@master#egg=pdvega
scipy == 1.4.*
scikit-learn == 0.22.*
patsy ~= 0.5.1
lightgbm ~= 2.2.3
lifetimes == 0.11.*
lifelines == 0.23.*
./wheels/fbprophet-0.5-py3-none-any.whl
adtk ~= 0.6.2
# data access
sqlalchemy ~= 1.3
psycopg2-binary ~= 2.8
PyMySQL ~= 0.9.3
google-cloud-bigquery[pandas, pyarrow] ~= 1.17
boto3 ~= 1.12.6
requests ~= 2.23.0
ftpretty ~= 0.3.2
pymongo ~= 3.10.1
# misc
dnspython ~= 1.16.0 # requirement for pymongo to connect to certain instances
sh ~= 1.13.0
要让脚本在您自己的 Docker 容器中运行,请自行指定。
目前,我们仅支持 公开 Docker 镜像,今后,我们将添加对私有库的支持。因此,如果不希望公开脚本或报告,建议用常规的
include机制上传私有文件夹,并在 Dockerfile 中添加系统需求或 pip 的requirements.txt文件。
虽然,基于任何 base 镜像都可以生成 Docker 镜像,但还是建议使用我们提供的 Base 镜像(nstack/datapane-python-runner)生成 Docker 镜像,您可以在这个镜像文件里添加自己所需的支持项。
from nstack/datapane-python-runner:latest
COPY requirements.txt .
RUN pip3 install --user -r requirements.txt
创建镜像后,可以推送到 Dockerhub,然后用如下方式在 datapane.yaml 文件中指定该镜像名称。
container_image_name: your-image-name
脚本将在该 Docker 容器里运行。注意,首次运行时,因为要从 Dockerhub 提取镜像文件,因此,所需时间较长。镜像提取完毕后会存在缓存里,以备今后使用之需。
数据库与 API 集成
与传统 BI 平台不同,Datapane 不提供指定的连接器提取数据。反之,您可以随意使用 Python 支持库连接数据仓库或内部 API 等数据源。并且,这些支持库还支持提取并连接来自不同数据源的数据。
在 Datapane 上运行脚本时,需要网络访问权限才可以连接其他平台。
如需连接内部数据库或使用 Datapane 团队版 的云托管服务,请联系支持人员获取虚拟机的 IP 地址。
管理密钥
连接第三方数据商店时,可能会需要验证。为了让这个工作流更简单,Datapane 提供了用户变量 API。可以安全地存储、分享、提取敏感信息。
管理 SQL 脚本
如需连接数据库或数据仓库,或需要调用 SQL 文件,需要在部署脚本时打包上传这些文件,将所需文件复制到脚本文件夹里,并在 datapane.yaml 文件里配置。
将 Python 与 SQL 联合在一起,为我们提供了用 Python 基于输入参数,生成
SQL 模板,实现数据库动态查询的机会。
数据、模型、资源存储
生成报告经常要调用数据集、模型、文件等非代码类资源。很多情况下,和脚本一起部署这些资源并不是什么好主意。
部署节奏与脚本不同。例如,每日都要训练模型,但脚本代码却是静态不变的。
部署环境与脚本不同。例如,脚本里使用的模型是在 Segemaker 上训练的。
Blob 对象一般很大,每次部署时重新上传都很麻烦。
对于这些用例,Datapane 提供了 Blob API,通过任何 Python 或 CLI 环境都可以上传文件,并可在脚本内或通过 CLI 访问。
API 文档中的 Blob 功能,请参阅下列文档:
Blob 对象(下期发布)