
docker制作深度学习镜像(以windows环境下为例)

向AI转型的程序员都关注了这个号👇👇👇
人工智能大数据与深度学习 公众号:datayx
用 Docker 安装深度学习环境,轻量、方便!整个系统大小仅需2~3G,用完还能带着走!一人装环境,全班都能用,还有 NVIDIA 官方提供的 GPU 镜像等着你哦~
深度学习环境的配置一直是一个令人头疼的问题,尤其是对使用 Windows 平台的用户来说,在安装一些开源深度学习框架的时候,经常会遇到一起奇奇怪怪的问题。
为了避免出现环境问题,有些同学选择使用 VMware、VirtualBox 运行 Linux 虚拟机的方式进行深度学习实验。但是像 VMware、VirtualBox 这类“重”虚拟机运行起来常会拖慢系统。
所以今天要分享给大家的是使用 Docker 配置安装深度学习环境。
使用Docker安装环境的优点如下:
无需自己配置环境,通过 Docker 镜像可以使用各种已配置好的深度学习环境。
轻量便捷。一个 Docker 客户端+一个镜像,总共大约3~4G即可组成一个深度学习系统环境。
便于分享。可以将自己的环境通过镜像库或直接以文件拷贝的方式传播。
官方支持。很多深度学习框架&项目提供官方 Docker 镜像。
英伟达专门提供的支持GPU虚拟化的Docker镜像:
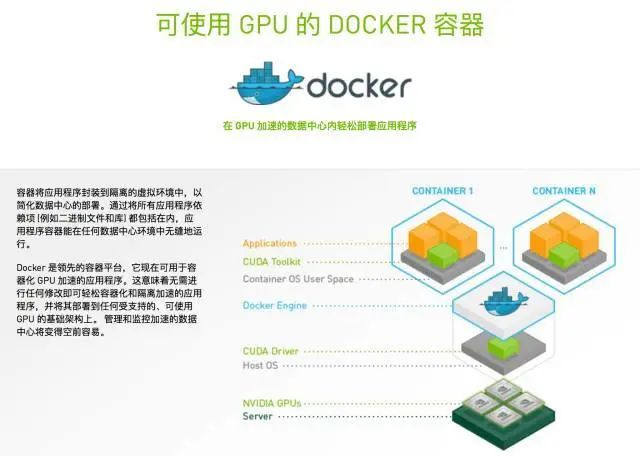
实战:9步创建深度学习环境
如何使用 Docker 创建并分享一个深度学习环境呢?需要9个步骤:
使用 阿里云 镜像站点加速服务
Docker-machine
从阿里云镜像获取一个与需求相似的镜像
把镜像从库里拖拽过来!
查看并运行镜像
将容器的修改提交到镜像中
将镜像上传到阿里云镜像仓库中
将镜像打包为独立文件
测试分享出的 Docker 镜像
docker在windows上的安装
1.使用 阿里云 镜像站点加速服务
在安装 Docker 后,理论上我们就可以去 Docker Hub 上寻找我们想用的镜像了。不过在国内访问国外的 Docker Hub 速度是非常慢的,所以我选择使用阿里云的镜像仓库。
访问:https://cr.console.aliyun.com/cn-hangzhou/instances/mirrors
注册阿里云账户并登录。

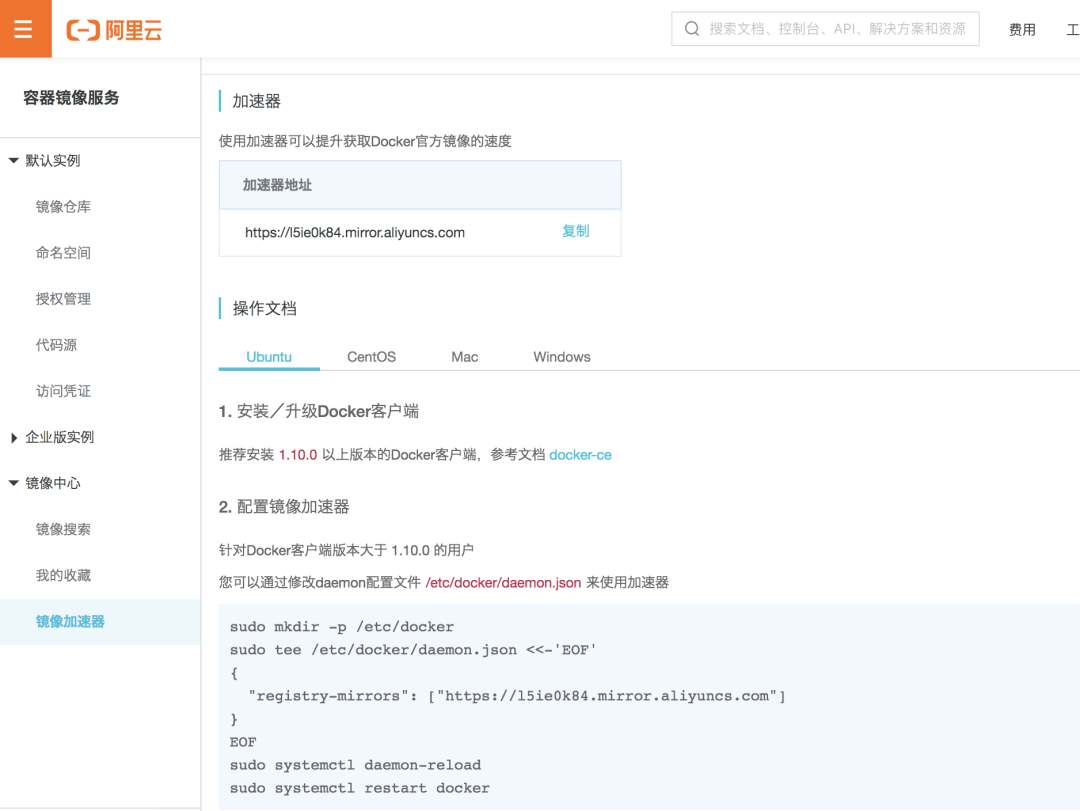
选择 Docker 镜像加速器。
在这个界面里我们可以看到属于自己的镜像加速器地址。我们要把这个加速地址配置到 Docker 里,从而让 Docker 默认从加速地址中寻找并下载镜像。

Linux 操作系统的配置都是通过修改 daemon 配置文件完成的,这个配置看起来比较简单。
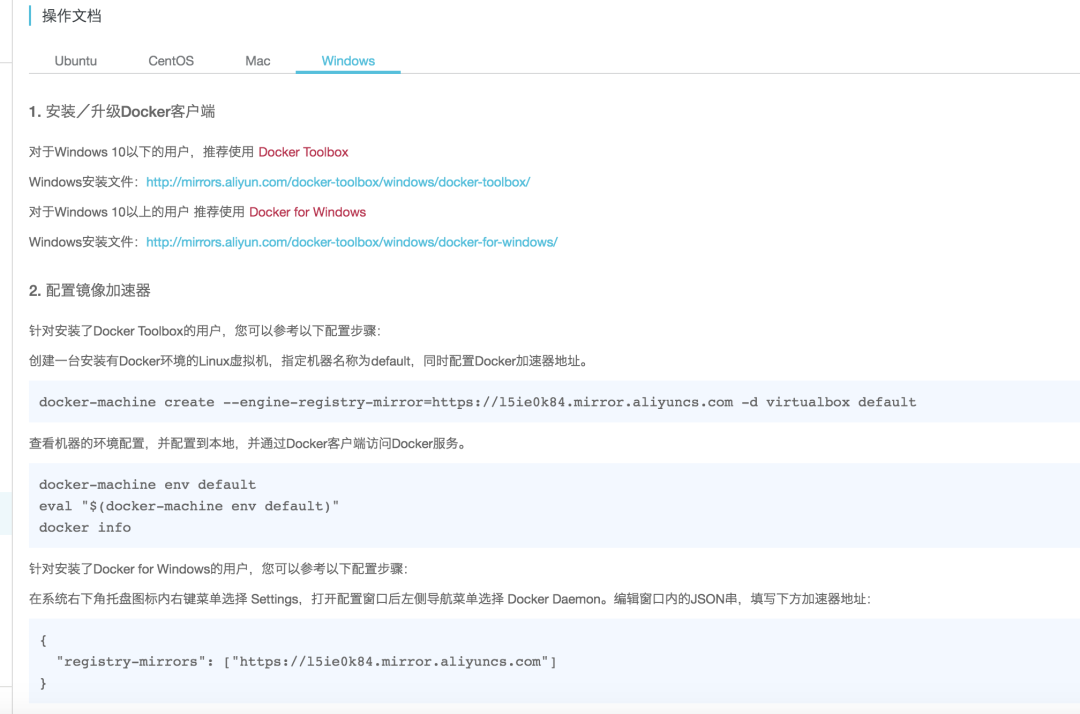
Mac 以及 Windows 操作系统由于系统限制,必须使用 docker-machine 来配置加速地址。
2.Docker-machine?
docker-machine 本质上是又是另一种虚拟机(怎么那么多虚拟机),我们暂且把它理解为一个自带 Docker 的 VirtualBox 虚拟机。
上图配置中第一条命令的意义是:使用阿里的加速地址创建一个 docker-machine 虚拟机并启动。
后三条命令的意义是:通过配置环境变量(只在本终端中有效)用 docker-machine 虚拟机中的 Docker 环境覆盖宿主机系统环境。
执行这三条命令后:
在 Docker-machine 运行期间,在当前的宿主机终端中执行的 Docker 命令,实际上都是由 docker-machine 虚拟机中的 Docker 环境执行的,因为只有 docker-machine 虚拟机配置了阿里的加速地址。
3.从阿里云镜像获取一个与需求相似的镜像
在镜像加速器地址配置完毕后,我们就可以去寻找需要的 Docker 镜像了。
我想找个已经安装好 Python3.6 的镜像,以便进一步安装最新的 PyTorch 以及其它相关的软件包,那么我搜索“python36”。
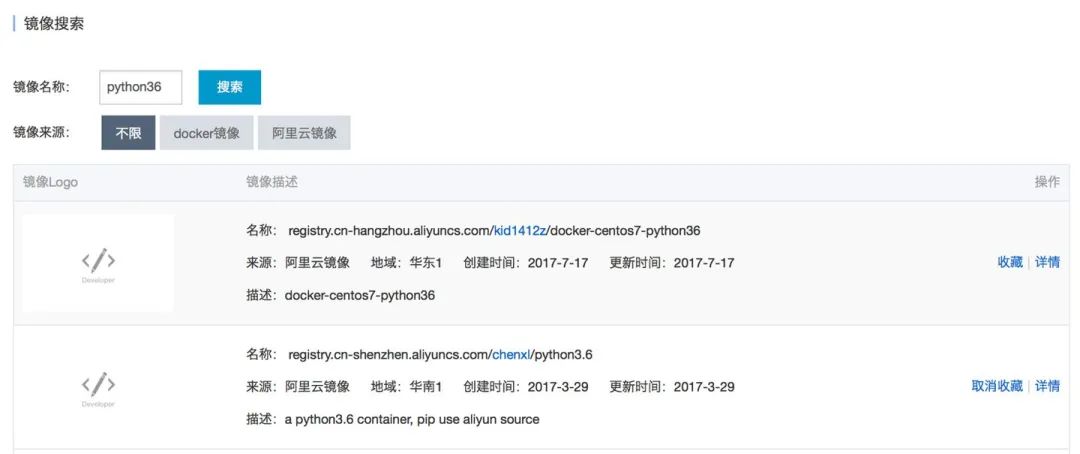
4.把镜像从库里拽过来!
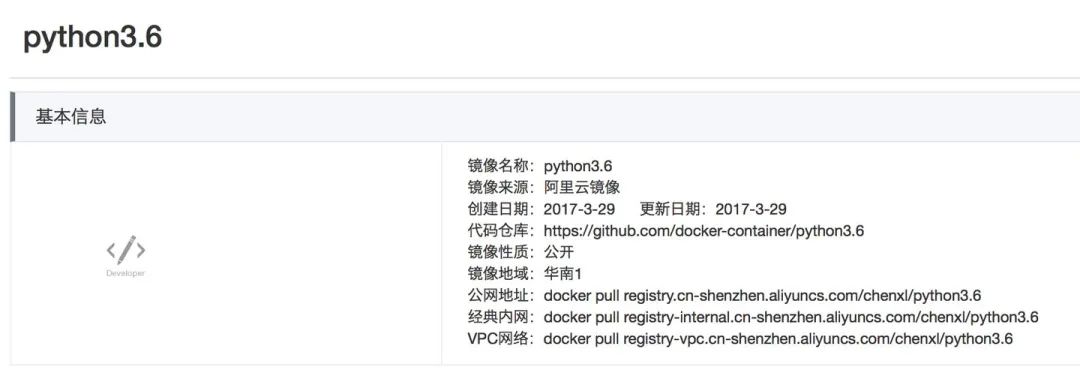
可以点击镜像详情,查看镜像的外网地址,然后把镜像拽到本地上来(之前必须已经配置好阿里加速器)。
docker pull registry.cn-shenzhen.aliyuncs.com
5.查看并运行镜像
我们可以使用命令 docker images 查看镜像信息:

使用 docker run 命令将镜像运行为可交互的 shell:

在命令中:
-t:在新容器内指定一个伪终端或终端。
-i:允许你对容器内的标准输入 (STDIN) 进行交互。
在命令运行后,我们可以观察到当前 shell 里的提示符已经从“Alex-MacBook-Pro”已经改成了“root@f8ad6eb17624”,这证明我们已经在 Docker 容器的系统环境中了。
我们按照常规的方式安装深度学习环境,比如用 pip 命令安装 PyTorch、torchvision 等软件包,并将项目源码拷贝到运行的容器中。
在宿主机与 Docker 容器间拷贝数据可使用 docker cp 命令。
在容器里进行一系列的操作后,我们的工作完成,可以运行 exit 命令退出当前 shell。
此时我们可以观察一下当前的容器(docker ps -al)与之前的镜像(docker images),可以看到容器与镜像同时独立存在,并且可以看到在容器中正在运行的项目(交互shell,即/bin/bash)。

6.将容器的修改提交到镜像中
假设我们在容器里安装了新的软件包并且跑通了自己的项目,现在打算把容器提交成镜像分享给其它小伙伴。
需要操作的流程如下:
首先查看容器的ID(docker ps -al):

将容器提交到镜像中,同时我们给它指定新的名字(docker commit [ID] [NEW_name]):

提交完成后我们再查看本机存在的镜像(docker images):

可以看到经我们修改后的新镜像“python36/pytorch”独立存在。
有句话叫“取之于民,用之于民”。
我们可以把这个包含最新版 PyTorch 环境的镜像上传到阿里云的镜像库中,让更多的人可以使用我们的镜像。
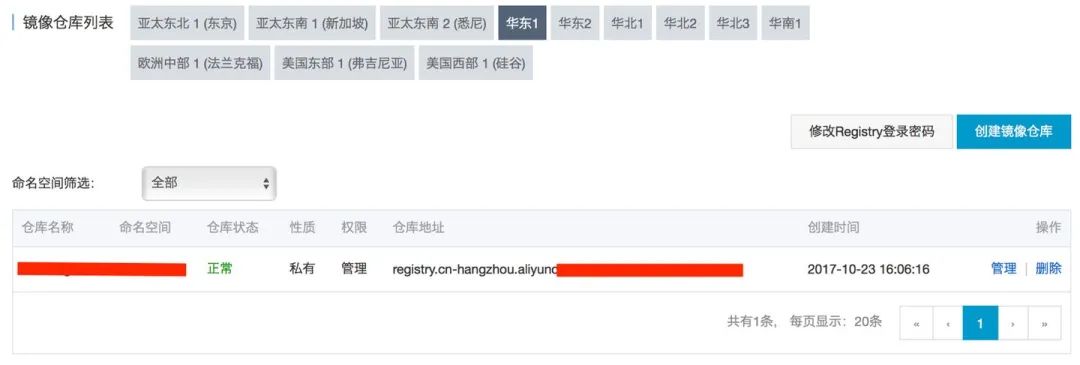
7.将镜像上传到阿里云镜像仓库中
我们首先在阿里云上创建一个镜像仓库:
然后我们需要在当前的终端中登录阿里云仓库(之前必须配置了阿里云加速器):
docker login --username=USER_NAME registry.cn-hangzhou.aliyuncs.com
要把镜像上传到指定的镜像库,需要先对镜像进行命名。整个名字由冒号“:”分成两部分,前部分是我们在上一步建立的镜像仓库的地址,后部分是对当前镜像打的标签(TAG)。TAG的存在是为了允许一个镜像库里存在多个版本的镜像。

好,这时候万事具备了,我们运行 push 命令将镜像推送到云镜像库中。
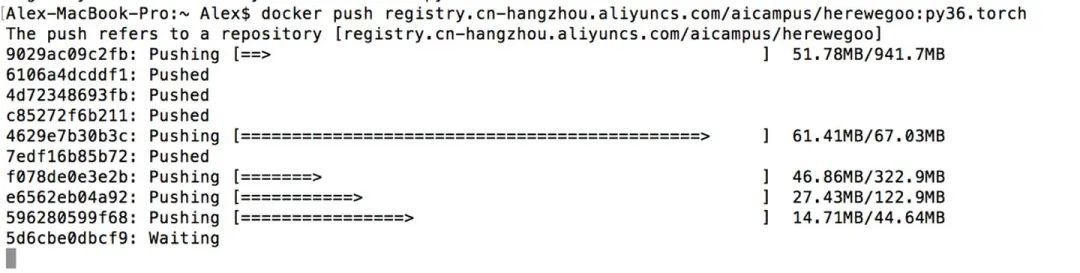
在上传结束后,我们就可以在云镜像库的web管理界面看到我们的镜像了。
8.将镜像打包为独立文件
除了上传云镜像库,我们也可以直接将镜像打包成一个独立文件,拷贝分享给别人使用。
同样,我们使用命令 docker images 查看镜像的名字,再使用 docker save -o 将目标镜像打包成文件。

9.测试分享出的 Docker 镜像
现在让我们测试下之前导出的镜像。
首先尝试导入刚刚在本地打包的镜像:
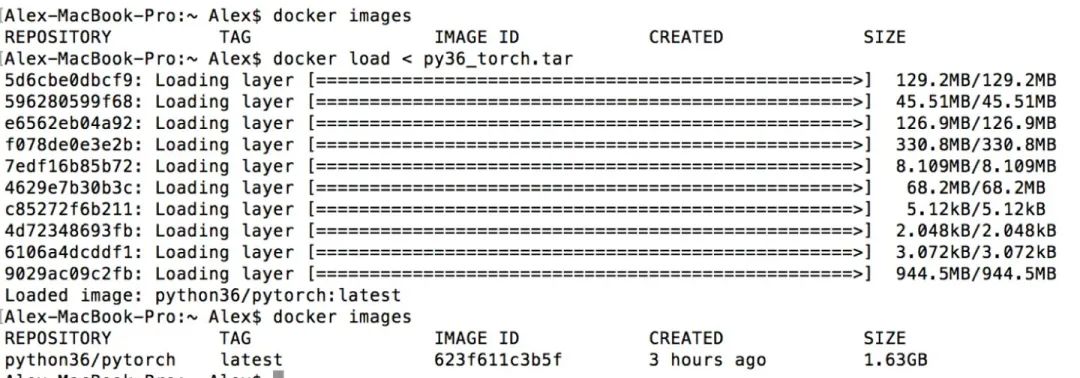
导入成功。
再试下从阿里云镜像库中把之前建立的镜像 pull 下来:
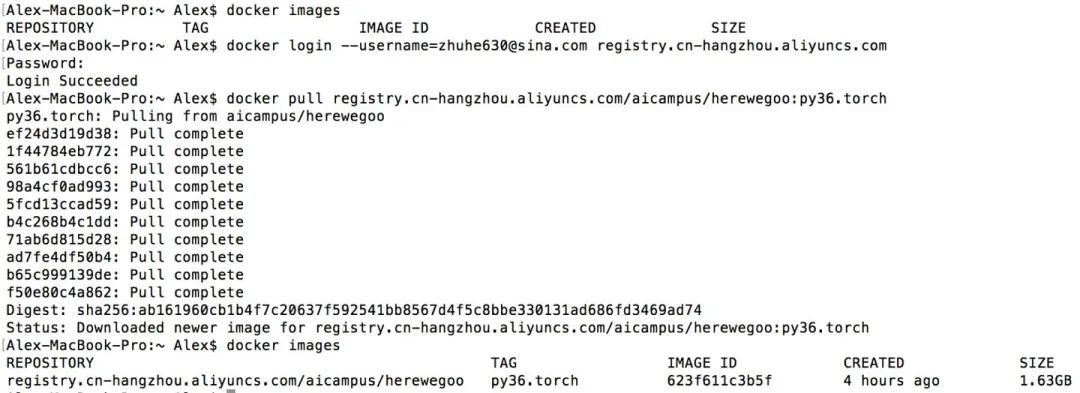
大功告成!还不快叫小伙伴一起来玩深度学习
docker 常用命令
1、安装docker,参考 https://www.runoob.com/docker/docker-tutorial.html
2、下载自己需要的镜像,可以在github上搜,比如pytorch的镜像 https://github.com/anibali/docker-pytorch
docker pull anibali/pytorch:cuda-10.03、通过docker images查看自己机器上有的镜像
4、创建容器并且进入(如果只是更新镜像内的软件包,可以不用挂载本地目录)
docker run -it -v D:/data:/app --name test anibali/pytorch:cuda-10.0 /bin/bash
1
红色是本机想要挂载在docker容器里面的文件夹,蓝色是docker容器内挂载本机红色路径对应的文件夹,紫色是镜像名字
5、进入容器后,下载一些自己需要的包,exit退出
6、docker ps -a查看本地容器
7、更新镜像
docker commit -m="update" -a="an" 79096af84806 an:pytorch
1
红色是描述信息,紫色是镜像作者名字,黄色是第6步中的container id,绿色是要创建的镜像名称
8、再通过docker images可以看到更新好的镜像
9、导出镜像
docker save an:pytorch > D:/an.tar
1
10、在另一台有gpu的机器上导入自己制作的镜像
docker load < /home/an.tar
1
11、创建容器并挂载gpu
docker run -it -v /home/data:/app -v /usr/local/docker-inspur/nvidia-volumes/volume:/usr/local/nvidia:ro --volume-driver=nvidia-docker --device=/dev/nvidiactl --device=/dev/nvidia-uvm --device=/dev/nvidia-uvm-tools --device=/dev/nvidia0 --device=/dev/nvidia1 --name ajp an:pytorch /bin/bash
1
蓝色是挂载gpu,不同机器情况不一样
卸载nvidia驱动
rmmod nvidia
1
卸载驱动如果出现nv_peer_mem进程在使用nvidia,下面命令stop nv_peer_mem
/etc/init.d/nv_peer_mem start/stop/status
1
卸载cuda相关,cd到cuda-x.x文件夹下,以10.0为例
cd /usr/local/cuda-10.0/bin
./uninstall_cuda_10.0.pl
1
2
查看nvidia相关进程
lsmod | grep nvidia
1
如果没有nvidia-uvm,需要去编译一下Samples,随便编译一个就可以
cd /usr/local/NVIDIA_CUDA-10.0_Samples/0_Simple/clock
make
./clock
1
2
3
docker启动
systemctl start docker
service docker start
1
2
重启docker服务
systemctl restart docker
sudo service docker restart
1
2
关闭docker
systemctl stop docker
service docker stop
1
2
如果/dev里面没有显卡,运行如下
for i in 0 1 2 3 4 5; do
node="/dev/nvidia$i"
rm -f $node
mknod $node c 195 $i || echo "mknod \"$node\""
chmod 0660 $node || echo "chmod \"$node\""
chown :video $node || echo "chown \"$node\""
done
node="/dev/nvidiactl"
rm -f $node
mknod $node c 195 255 || echo "mknod \"$node\""
chmod 0666 $node || echo "chmod \"$node\""
chown :video $node || echo "chown \"$node\""阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx
机大数据技术与机器学习工程
搜索公众号添加: datanlp
长按图片,识别二维码