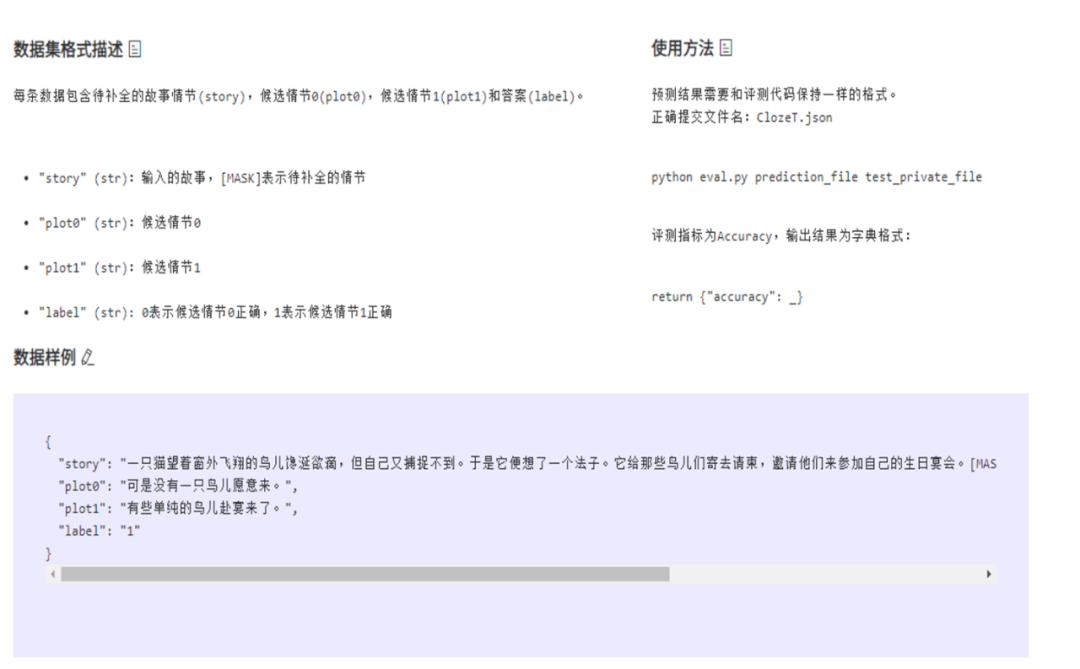
本文介绍了最新发布的中文自然语言评估指数—智源指数。
作为深度学习研究的重要组成部分,评测 benchmark 扮演着评估模型性能、指导研究方向的重要角色。在自然语言处理中,针对英文任务的评测 benchmark 有 GLUE,SuperGLUE,针对中文任务的有 CLUE,这些都为自然语言处理的迅速发展奠定了基础,但随着预训练模型,尤其是大模型的不断涌现,这些评测benchmark的指引作用越来越小,在很多榜单上模型的性能已超越所谓的“人类水平”,但模型的语言理解与应用能力相比人类的认知水平仍有较大差距。那么,如何来准确标定这种差距,并在未来的发展中继续发挥评测 benchmark 的指导作用,成为了一个亟需解决的核心问题。
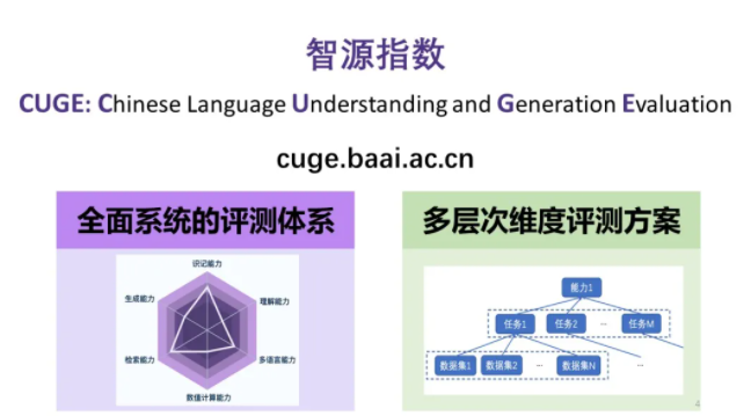
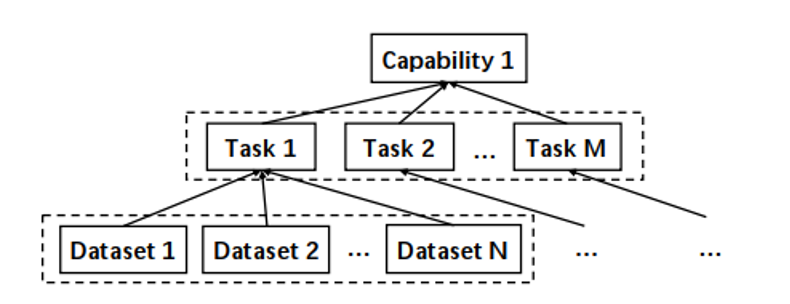
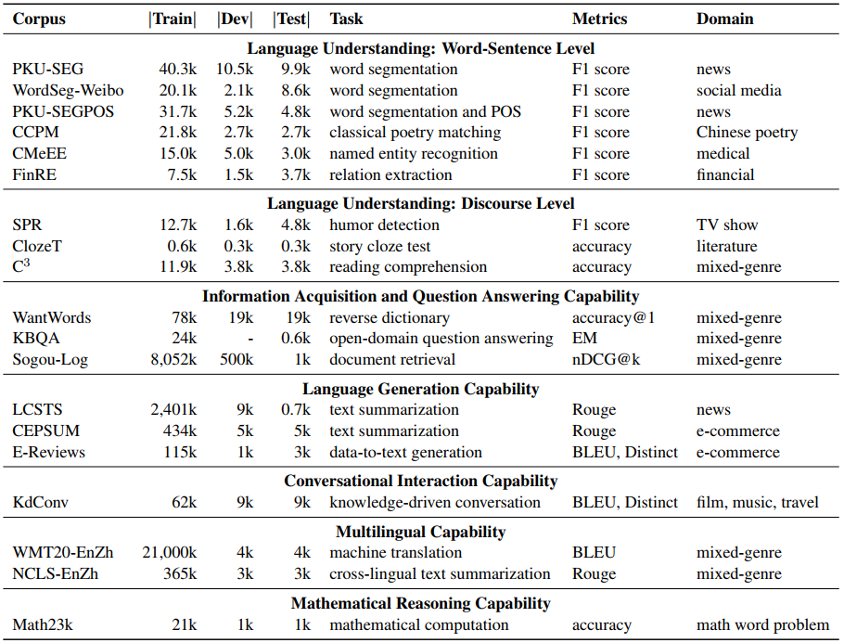
为解决这一问题,智源研究院发布了中文自然语言评估指数—智源指数 CUGE(Chinese language Understanding and Generation Evaluation),这是一个多层次、多维度、全面系统的中文评测体系。和现有的评测 benchmark 相比,CUGE 在任务(数据)选择,评估标准,评测方式三大方面进行了改进,实现了更加科学、规范、高质量的模型效果评估。现有的评测 benchmark 大多是数据驱动的,通过选择常用的数据集构成评测数据集集合,而且更多关注于语言理解及表示能力,对其他语言能力(例如生成,数学推理,多语言等)并没有给予太多的关注,而且 benchmark 中的数据集组成非常松散,对模型的语言能力评估比较粗糙。与之相对的,如上图所示,CUGE 通过能力-任务-数据这样自顶向下的层次化结构选择更具代表性的任务以及数据集,从而实现模型语言能力更全面的评估。具体而言,CUGE 借助中国高考评价体系中的评估标准和自然语言处理研究现状,筛选出评估模型的7种重要语言能力,然后针对这些语言能力,选择了 17 个主流的评估任务以及对应的 19 个代表性数据集作为最终的评测 benchmark 组成,具体可以总结为如下形式:- 词句级语言理解能力:中文分词、词性标注、古诗匹配、命名实体识别、实体关系抽取;
- 篇章级语言理解能力:幽默检测、故事完形填空、阅读理解;
- 信息获取及问答能力:反向词典、开放域问答、文档检索;
现有的 benchmark 基本上都是选择比较单一的评估标准(准确率,F1 等),针对模型在所有的数据集上性能取平均作为模型的最终评估效果。而 CUGE 有两方面的改进:
1. 单数据集评估:CUGE 不再是直接使用模型的性能作为评估结果,而是为所有的评估模型选择一个基线模型(mT5-Small),利用该基线模型在数据集上的效果,对需要评估模型的结果进行归一化,从而使得实验结果更合理,同时在不同的数据集之间更具可比性。 2. 多层次的评估标准:借助 “能力-任务-数据”层次化结构,CUGE 能够实现模型的多维度评估,防止对某个评估标准进行“刷榜”,从而能够更好的指导针对模型语言能力的研究。具体可分为三个层次:- 任务级别性能评估:对指定任务下的数据集模型结果做归一化平均;
- 能力指标性能评估:对指定能力,不同任务下的模型结果进行平均;
- 全局指标性能评估:对所有能力下的模型结果进行平均。
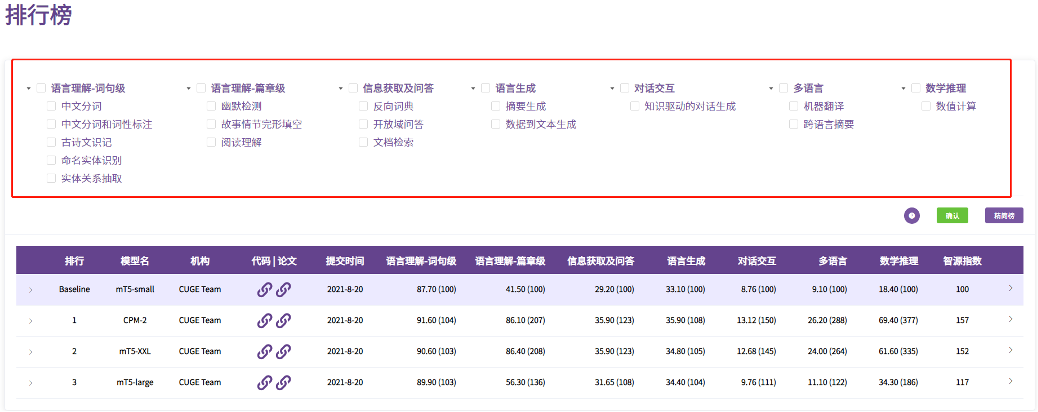
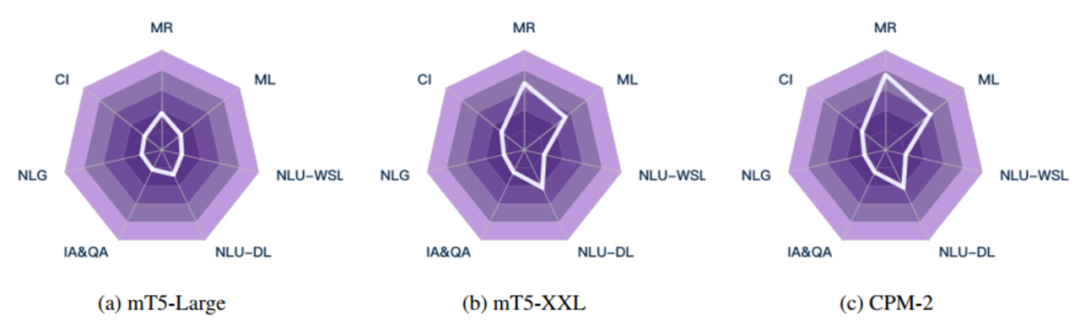
CUGE 的评测方式更加方便、直观和人性化。具体表现在:1. 支持根据具体需求定制对应的评测能力、任务和数据集,通过勾选,实现显示所关心能力和任务的评测。2. 提供丰富的数据样例使用教程,让用户更容易上手使用。3. 提供更加直观的模型效果展示图,利用雷达图呈现模型在7种重要语言能力的性能分布以及提升效果,可辅助研究者进行针对性地分析和改进。相关展示如下图所示:4. 确保数据集的更新和动态维护,CUGE 会不断吸收新的数据和任务,保证 CUGE 对机器语言能力研究的持续指导作用。当前自然语言处理领域的评测 benchmark 非常多,被大模型们反复“刷榜”。最近谷歌的一个工作指出,现有的 benchmark 并不能做到对模型的公平性评测,反映出评测本身是一个开放性的难题。而智源指数的提出,是希望通过持续不断地改进和更新 benchmark,让更多的研究工作回归提升机器语言能力本身上,准确鉴别出真正的好技术。同时,基于每年的评测情况,来向大家展示机器语言能力的发展现状,共同推进自然语言处理领域的发展。
参考资料
[1] CUGE: A Chinese Language Understanding and Generation Evaluation Benchmark. https://arxiv.org/pdf/2112.13610.pdf
[2] 智源指数: http://cuge.baai.ac.cn/#/
[3] GLUE: https://gluebenchmark.com/
[4] SuperGLUE: https://super.gluebenchmark.com/
[5] CLUE: https://chineseglue.github.io/index.html
[6] AI and the Everything in the Whole Wide World Benchmark
编辑:王菁
校对:林亦霖