
大促压测,遇到的那些问题
大促,对于电商公司来说就像家常便饭。那么如何保证大促时线上系统的稳定性呢?答案就是:全链路压测。
全链路压测就是对业务功能的整条链路进行压测,并且使用真实的线上环境,这样才能保证压测结果跟大促时的流量应对不会差太多。但是压测的时候需要对底层存储进行影子库的配置,所谓影子库就是复制一份一样的业务数据库,当压测的流量来临时数据操作都是走影子库,这样才能保证真实的业务数据不被污染。
今天分享下压测过程中遇到的一些问题,也是一些经验,能够帮助我们在后续的工作中对设计方案,编码的重视。当你写一个接口,面临调用量 100 的QPS和 1000的QPS,所需要考虑的点不止多一星半点。
Redis大Key问题
问题描述
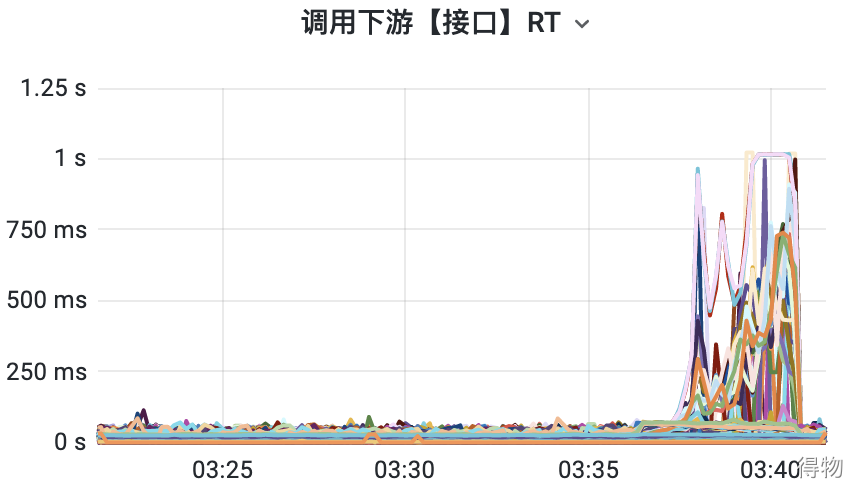
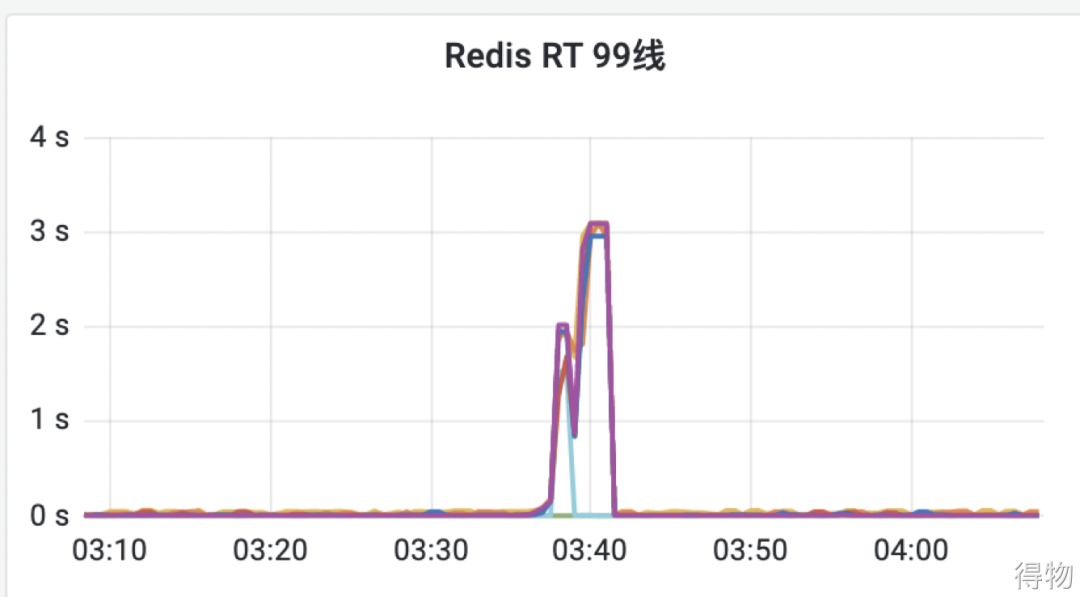
在对确认订单页进行压测的时候,QPS 一直上不去,RT 反而越来越高,慢的 RT 高达1秒多钟的时间。于是马上查看了下游接口的RT大盘,发现部分接口的耗时很高,如下图:
排查过程
然后马上通过调用链,抽了几个耗时比较长的Trace进行问题排查。
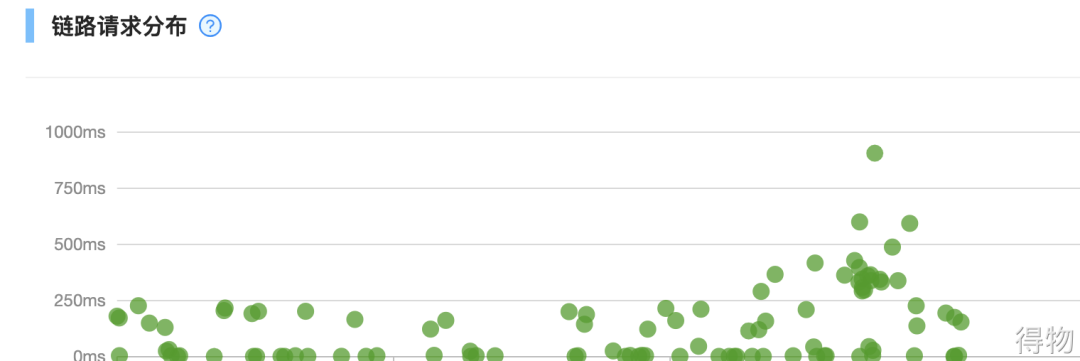
其实通过下游RT大盘就知道了哪个接口耗时较长,不过通过链路更方便,也能快速发现这个接口内部是由于什么逻辑导致响应特别慢。
通过链路的分析,在这个接口内部有一个读取Redis的操作耗时较长,情况很明了,就是Redis响应慢导致整个接口RT上升。
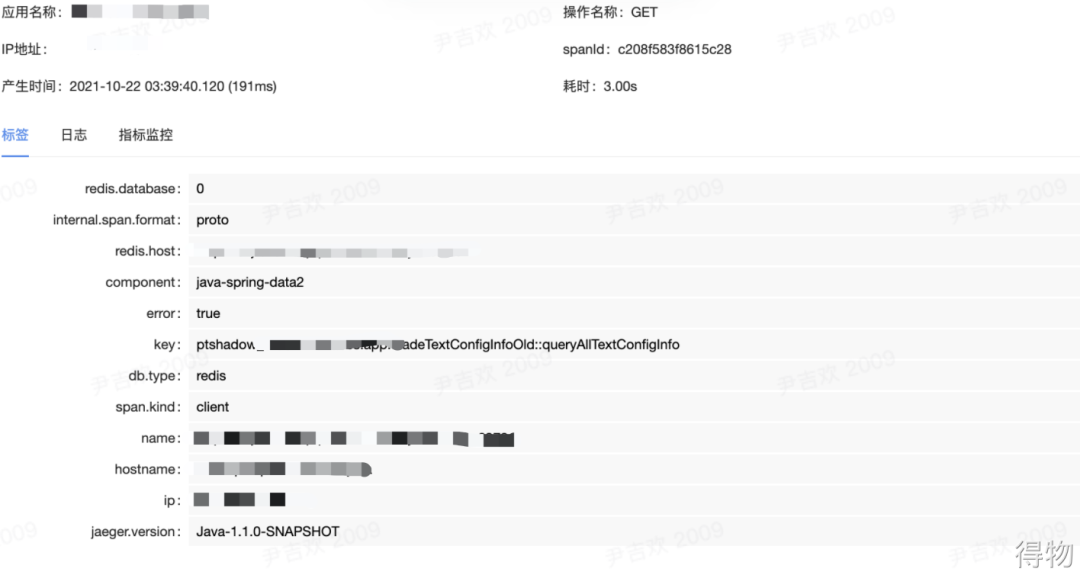
定位到了问题,接下来就是去Redis的管理后台查看对应的性能指标,发现Redis的CPU很低,也没有对应慢查询的记录。
接着看其他指标,发现某个Redis节点的带宽特别高,其他节点都不高。然后看了这个Redis集群的配置,直接就发现了问题的根源所在,带宽不够。
为什么这个节点带宽不够呢?因为程序里读取的是固定的一个Key的缓存,这个缓存的容量又比较大,达到了M级别,所以并发一上来,带宽就被打满了。
解决方案
方案一:Key拆分
在这个业务场景下,一个全量的配置信息,全部获取后再从里面提取业务需要的内容。也就是可以将这个配置信息拆成多份,按需求获取业务需要的内容。这样就能避免缓存内容太大,将带宽打满的问题。
方案二:本地缓存
如果要通过改造业务逻辑来解决问题,耗时有点长,毕竟解决当前问题是首要的,所以采用本地缓存的方式快速解决。
将此配置信息缓存一份到本地服务中,这样就能避免大量请求去Redis获取,也就能避免带宽的问题。但是这种多级缓存的方式,带来的问题就是数据一致性。如果不能保证数据一致性,那么业务就有可能出问题。
好在我们内部之前有过一套完整的多级缓存方案,只是复用即可。会采用消息通知+定时更新的方式来保证一致性。
内存泄漏问题
问题描述
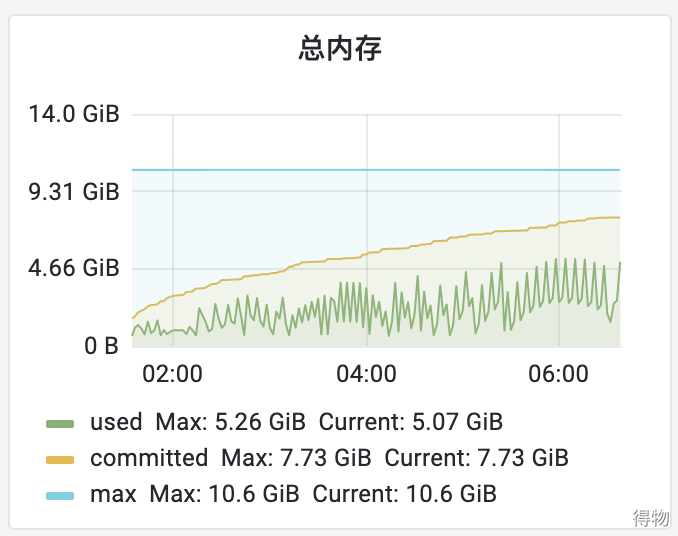
经过几轮压测后,服务内存一直居高不下,从监控看趋势,是慢慢往上升的。在垃圾回收后,内存也没有降下来,初步判断是内存泄漏了。
排查过程
解决现有问题排第一,首先将机器都重启了一遍,留了一台用于分析问题。然后将流量从Nacos上下掉,这样就不会影响用户的请求(非常重要)。
下掉之后让运维大佬帮忙dump下这台机器的内存,然后再本地用Mat进行分析。最开始本地还没按照Mat我就用了一个线上工具分析了下,如下图:
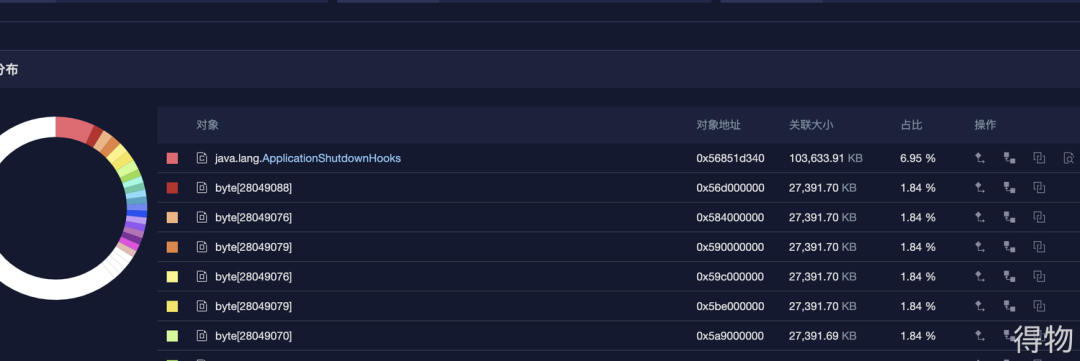
ApplicationShutdownHooks这对象占比最大,问题就很清晰明了。通过检查代码发下在某个获取线程的方法中每次都会去addShutdownHook,这个起初是只想加一次就行了的,由于写法问题导致每访问一次就加一次,随着调用量的增长,这个对象也越来越多。
解决方案
只添加一次Hook即可,改造前代码如下:
public static ExecutorService getCartsListExecutor() {shutdownHandle(cartsListForkJoin, "cartsListForkJoin");return cartsListForkJoin;}
改造后代码如下:
static {shutdownHandle(cartsListForkJoin, "cartsListForkJoin");shutdownHandle(cartsCacheInitForkJoin, "cartsCacheInitForkJoin");}
机器内存占用过高问题
问题描述
前面2.2章节中介绍了内存泄漏的问题,本以为解决后就正常了。没想到第二轮压测后,内存还是居高不下,占机器内存的70%多,触发了告警配置的阀值。
排查过程
通过JVM的监控发现堆内存会正常回收,但是回收后机器的内存还是降不下来。但是总的使用内存其实不多,多的是黄色线条标识的committed,一直在一条平均线上面,无任何波动。
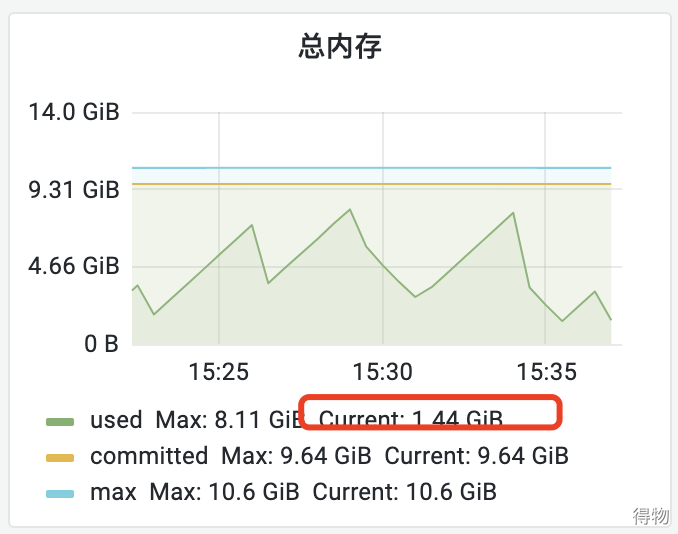
新生代的committed降低后,老年代的又上来了,而总量一直保持在9G多的样子。由于JVM会预先申请内存,预先申请的最大值为Xmx的9600M,一直保持在此值水平线并不会释放,所以机器内存占用水位线也一直保持在70%左右,对应用无影响。即使GC后,堆内存使用减少,预先申请的commited内存也不会释放。
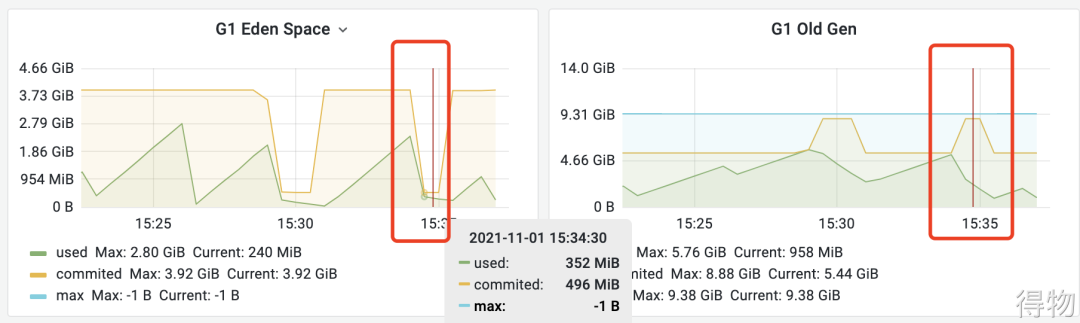
关于commited内存释放相关的可以查看下面这些文章:
https://stackoverflow.com/questions/50965967/profiling-jvm-committed-vs-used-vs-free-memory
https://openjdk.java.net/jeps/346
http://www.hilalum.com/2020/12/jvmabout-jvms-committed-memory.html?m=1
https://stackoverflow.com/questions/41468670/difference-in-used-committed-and-max-heap-memory
解决方案
扩容机器内存,由16G扩到32G,不过目前堆内存也够用,只是触发了告警的阀值而已。
限制最大堆内存,目前为9600M, 也就是committed最大申请值为9600M,可以调小点,这样就不会预先申请那么多,也不会触发告警。
调整监控阀值比例为80%,目前是70%,经过验证内存水位一致保持在80%以下,并且堆内存也能正常垃圾回收。

后台回复 学习资料 领取学习视频