
7道题,测测你的职场技能

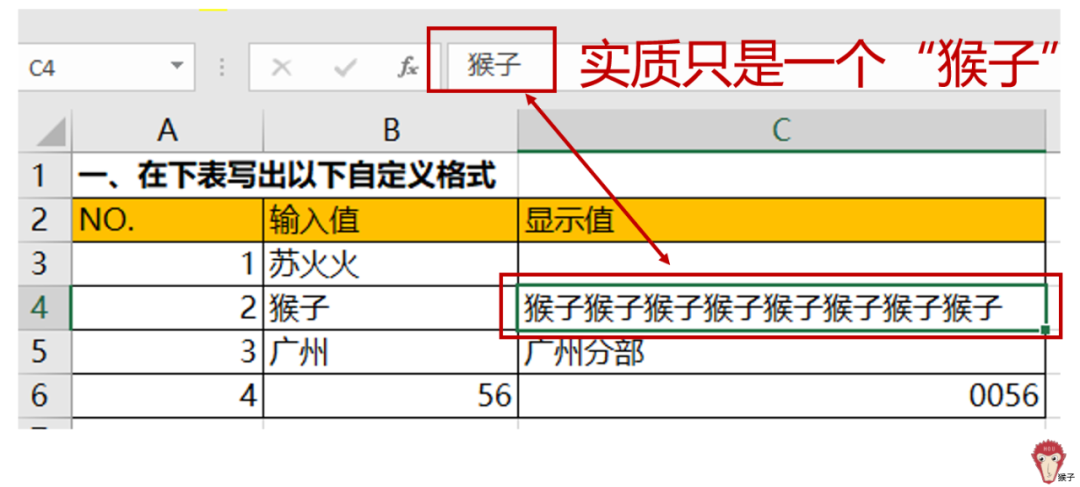
【题目1】在下表写出对应的自定义格式

如上图所示,输入值,为我们真正输入的值。显示值,是excel里显示出来的值。
为什么输入的值与显示的值看起来不一样呢?
当我们鼠标单击“显示值”列的任一单元格,在编辑栏里,我们可以看到其“内核”其实是和输入值一致的。
例如,点击单元格C4,在编辑栏里会看到其实质和输入值“猴子”是一致的。也就是说,虽然我们看到它显示的是N个猴子,但实质上,它仍只是一个猴子。
那使得excel这样“表里不一“的原因是什么呢?
其实,就是“自定义数字格式”在起作用。回到本题中,我们逐一来破解。
(1)输入“苏火火”后,显示出来的却是空白值,也就是说内容被隐藏了。在日常工作中,对于敏感的数据需要进行临时隐藏,有人可能会将字体设置为白色,其实这是非常不专业的,一旦excel被填充了其他颜色,白色字体就立马暴露无遗。在这里我们可以通过自定义数据格式来实现。
选中需要隐藏的单元格区域,单击鼠标右键,在弹出的快捷菜单中选择“设置单元格格式”。
打开“设置单元格格式”对话框,选择“自定义”格式,在自定义“类型”输入3个分号(英文状态下输入),确定即可。然后内容就被隐藏了。

3个分号是单元格自定义格式的分隔符。自定义格式代码的完整结构为:正数;负数;零值;文本。
以3个分号划分4个区段,每个区段的代码对不同类型的内容产生作用。3个分隔符包括了所有的字符格式,所以,当在3个分号前没有任何的设置,自然就使得无论输入任何类型的值,都会被隐藏。
(2)输入一个“猴子”,显示出来的,却是N个“猴子”。在“设置单元格格式”对话框中,我们可以看到文本的数字格式代码为@。
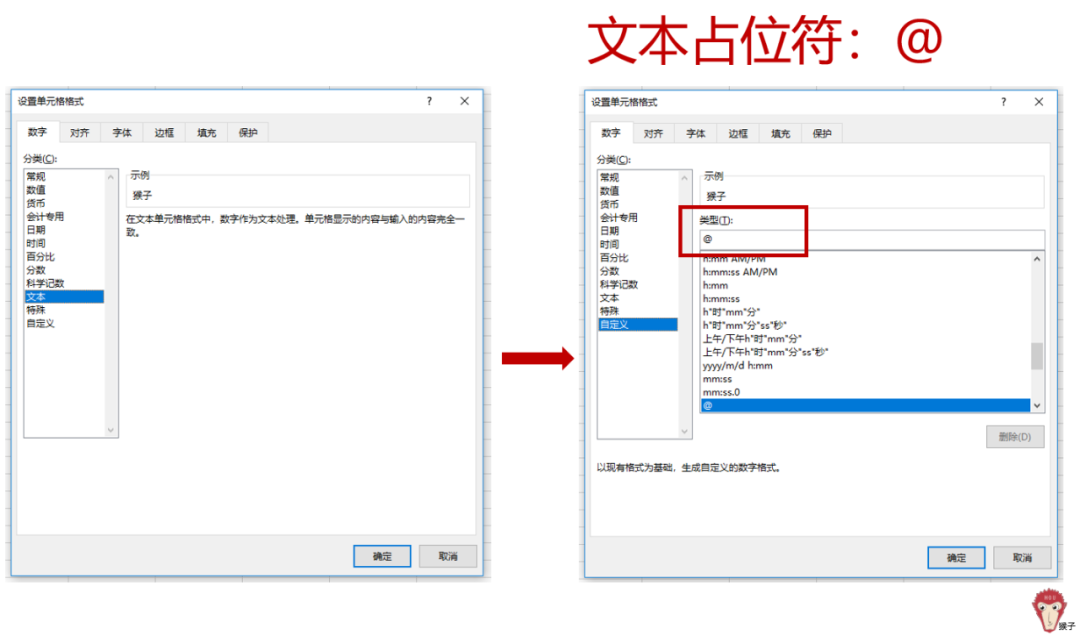
既然@代表一个文本占位符,那么,如果想文本重复显示,是不是重复@就能实现呢?我们手动把“猴子”的数字格式代码@改为@@@@@@(想重复显示多少次就多少个@),然后,就看到,虽然只输入了一个“猴子”但却显示出了N个“猴子”。

(3)同样地,在上面我们已经知道@代表的就是文本占位符,当我们想给文本统一添加固定的前缀或后缀时,是不是直接可以在@的前面或后面添加即可实现呢?如我们想输入“广州”时,显示的是“广州分部”;输入“上海”,显示的是“上海分部”等等。

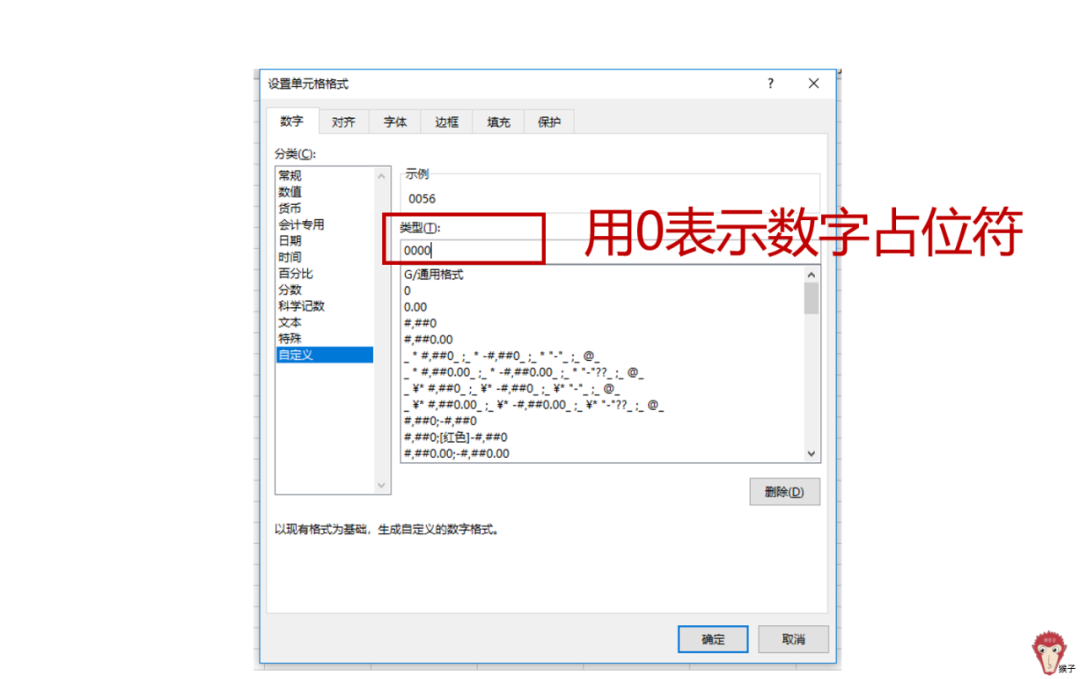
(4)@代表的是文本占位符,而数字占位符,是用0来表示的。所以,当输入类似“56”,却想显示为“0056”的时候,可以在“设置单元格格式”对话框中,把数字格式代码修改为“0000”即可。当输入的数字比代码的数量少时,会显示为无意义的零值。所以,输入56,就会显示为“0056”;如输入123,就会显示为“0123”。
【题目2】使用定位条件功能进行批量填充
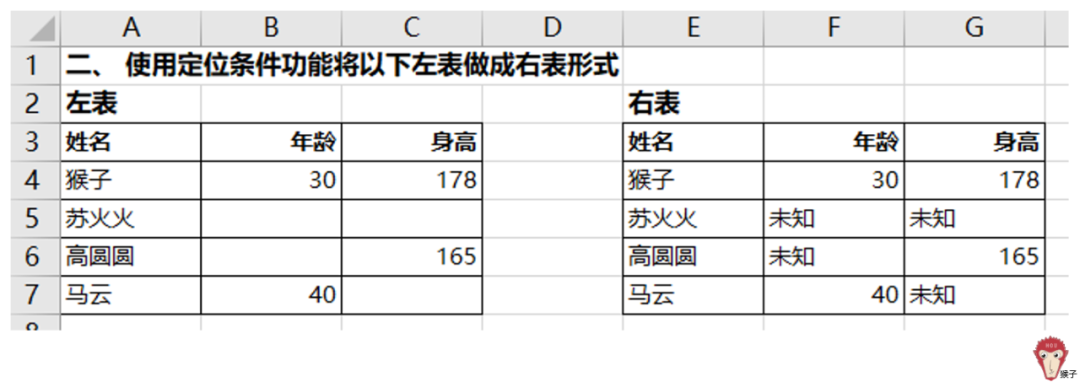
如何使得左边的表变成右边的表呢?也就是说,如何使得多个不连续的空白单元格同时输入数据?
有人说,我输入其中一个单元格,然后复制到其他空白单元格不就可以了吗。
这是一个笨拙的方法,在实际工作中,要处理的工作表并不可能像案例演示这样只有几行几列,而是有几百几千甚至几万行,而其中的多个不连续空白单元格更是毫无规律可言,不可能一个一个单元格地去填写。
那么,如何同时选中多个不连续的空白单元格呢?
这里可用到“定位”功能。单击左表任意一单元格,Ctrl+A,全选整个单元格区域;然后,按快捷键F5,弹出【定位】对话框;
点击左下角的“定位条件”按钮,在弹出的【定位条件】窗格中,可以对自己要进行定位的条件进行选择。
如本次案例中,我们是要定位出空单元格,也就是“空值”,因此选择“空值”作为定位的条件。

“确定”之后,如下图,就批量选中了表里不连续的空单元格。输入所需要的数据,如案例中输入的是“未知”;在输入结束时,按Ctrl+Enter组合键确认输入,此时,就会在选定的所有空白单元格里批量输入了相同的内容。

【题目3】使用辅助列将以下左表变为右表形式
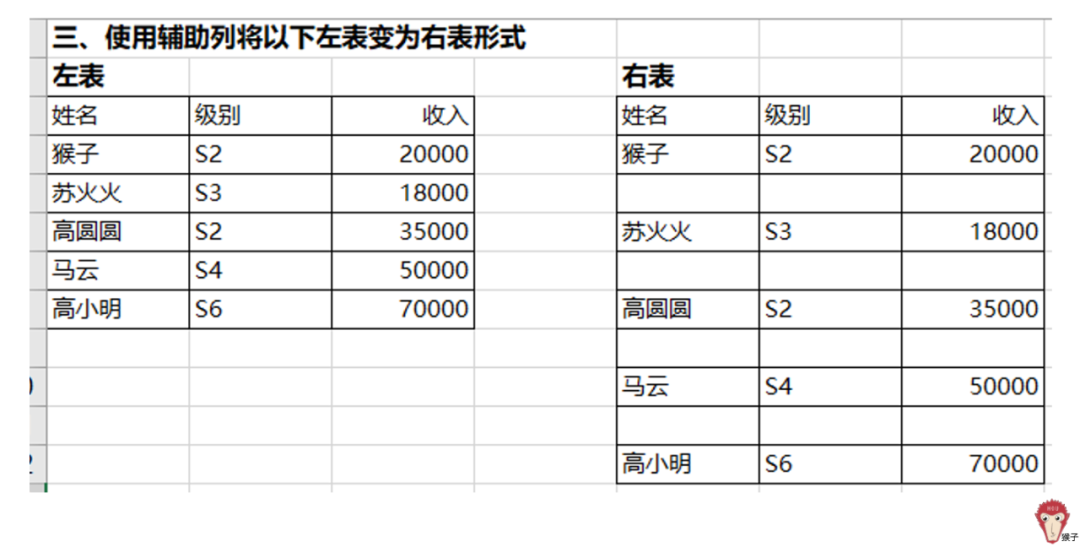
如图,要将左表变为右表的形式,其实就是将表里的姓名列,每隔一行插入空白行。如何实现呢?我们可以通过添加辅助列的方法来实现。首先,在姓名列的左侧增加一列“辅助列”,输入1,然后填充序列,如案例中填充到5。

然后在5下面,再输入1.5(注:这里不一定就是输入1.5,也可以输入1.1,1.2等,只要比1大比2小的数就行),然后填充序列,下拉到4.5。

最后,对辅助列进行升序排序,如下图,即实现了需求。
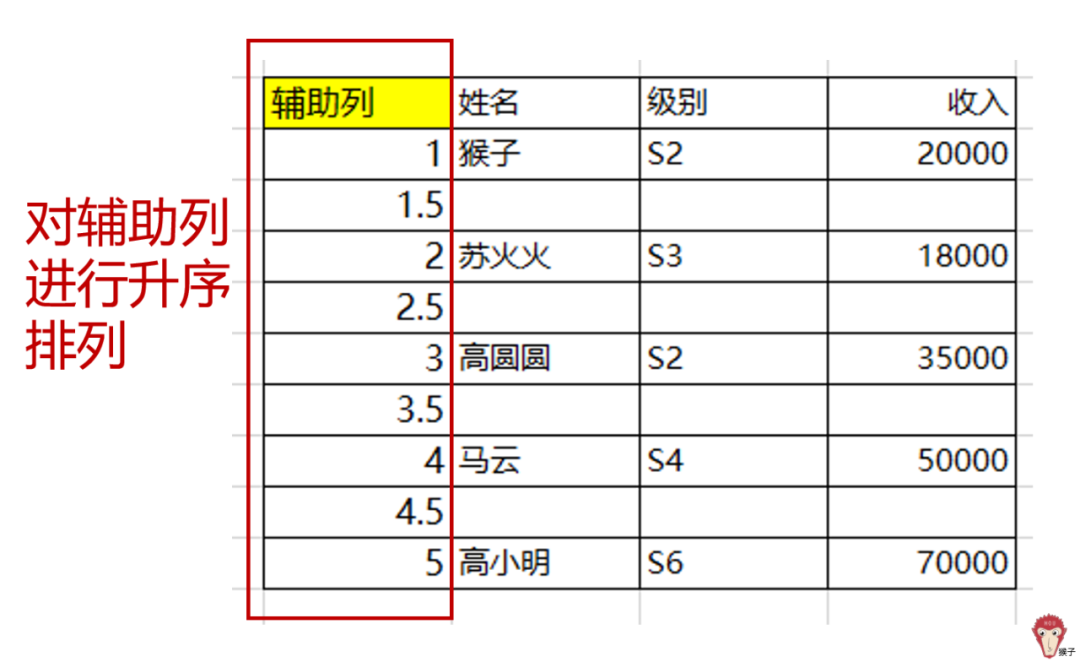
最后,把辅助列删除即可。
【题目4】将下表中籍贯列含有“北”字的单元格内容置换为“练习”

需求是,只要籍贯列里的内容含有“北”字的,就统一替换为“练习”。如“北京朝阳区”,含有“北”字,所以,转换为“练习”。有人说,我直接用【查找和选择】里的替换功能,把“北”字替换为“练习”不就行了吗?看清楚题意,在案例里,是把含有“北”字的单元格内容进行替换,而不是对一个“北”字进行替换。
通过观察籍贯列,可以发现,“北”字在不同的籍贯里,可能是位于第1位,也可能是位于第2位,或第5位等,总之,“北”字字符位置是不确定的。
在excel里,可以使用通配符来进行模糊查找。Excel所支持的通配符包含有两个:星号“*”和问号“?”
*:可代替任意多个字符,可以是单个字符、多个字符或者没有字符。
?:可代替任意单个字符。
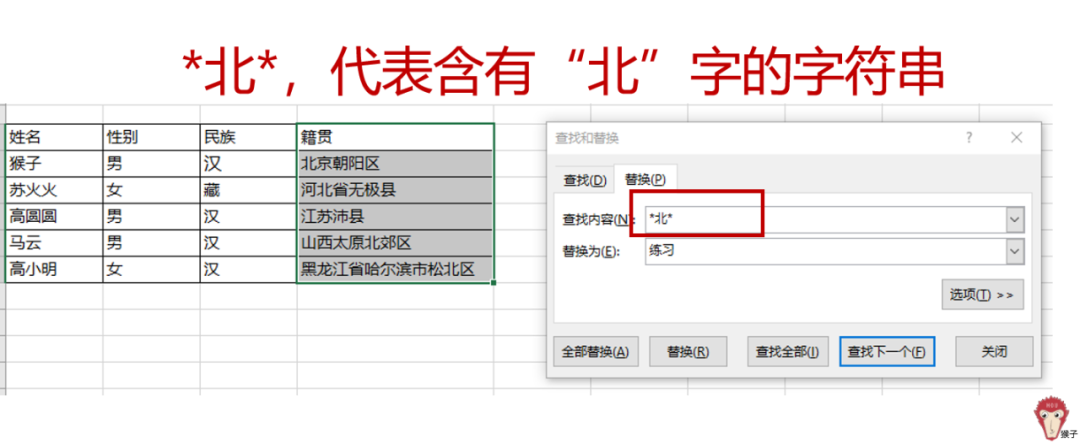
例如,要在表格中查找含有“北”字的,“北”字前面还有多少个字符,后面有多少个字符,这些都是不确定的,所以,我们可以以“*北*”来指代含有“北”字的任意字符串。
选中籍贯列,Ctrl+F 快捷键打开【查找和替换】对话框,在“查找内容”框里输入“*北*”,在“替换为”对话框里输入“练习”,再点击【全部替换】。
最终结果如下:

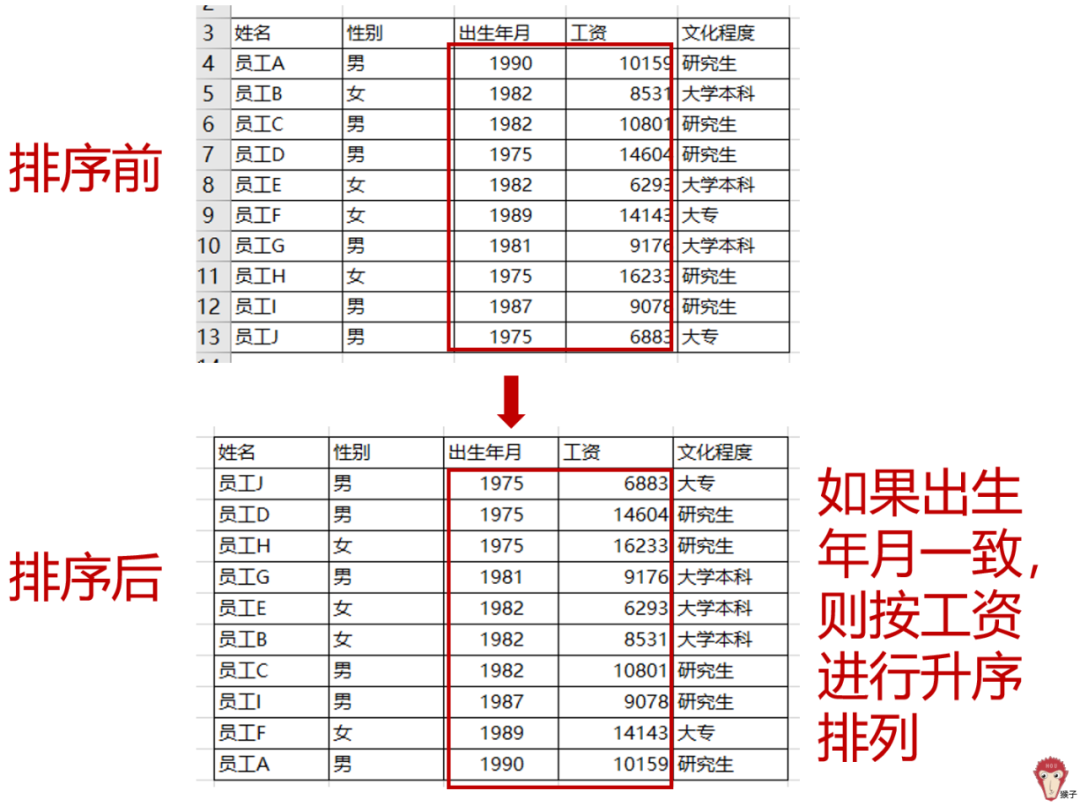
【题目5】将下表按照出生年月及工资顺序进行升序排序后筛选本科及以上的男性
需求是对“出生年月”及“工资”双条件排序后再作筛选。单击表格内任意一单元格,然后点击【开始】-【排序与筛选】-【自定义排序】
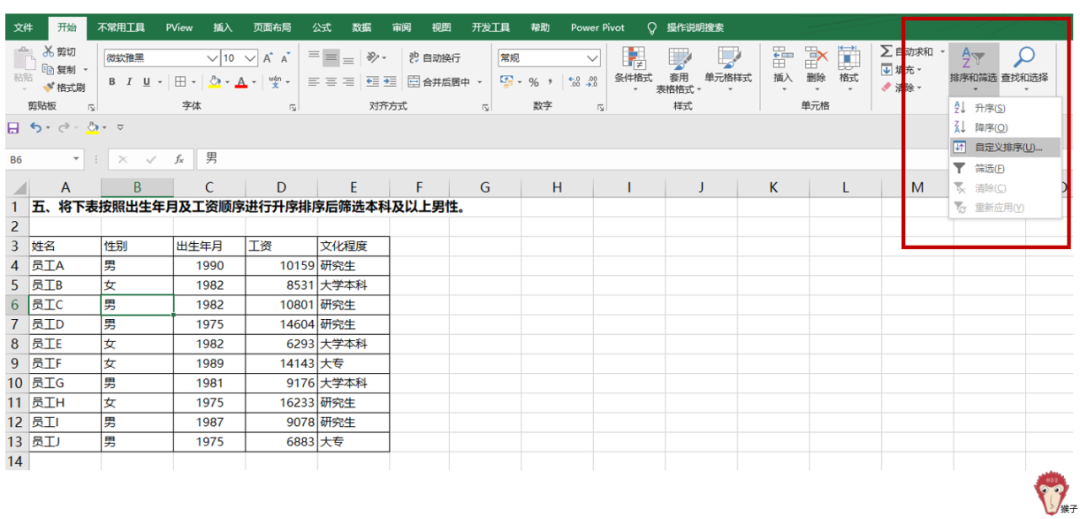
在弹出的【排序】对话框里,在“主要关键字”里,选择“出生年月”,“升序”
然后再“添加条件”,增加“次要关键字”,选择“工资”,“升序”

双条件下排序,结果如下图所示。先按出生年月进行升序排列,如果出生年月是一样的,则按“工资”进行升序排列。
对排序后的结果 再筛选出本科及以上的男性。鼠标单击表区域内任意一单元格,然后【数据】-【筛选】,就可以看到每个列表头,右侧都多了一个下拉箭头。

单击下拉箭头,就可以对该列的内容进行筛选:如单击“文化程度”的下拉箭头,就会在下拉菜单里看到有“大学本科”“大专”“研究生”。按照案例要求,要筛选出本科及以上,所以,把“大专”的勾选开。
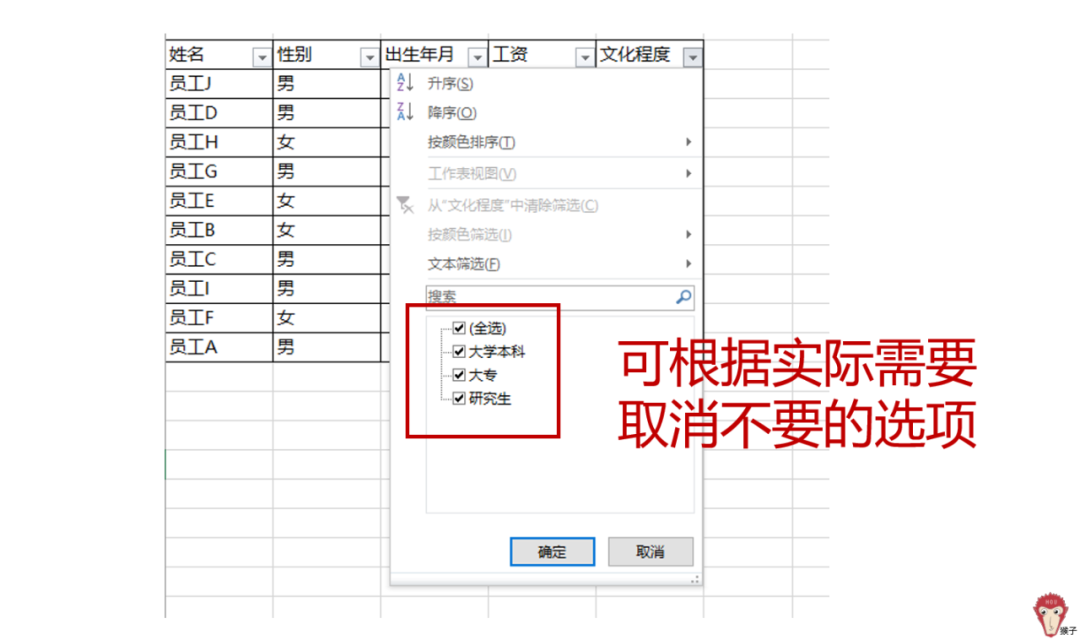
同样地,对“性别”列进行筛选操作,筛选出男性。
最终结果如下:

【题目6】计算A3:A9中含有“车间”的单元格个数

条件计数函数countif的应用。countif函数,对指定区域内满足条件的值进行计数,其语法是:
=countif(区域,条件)如在案例中,要对单元格区域A3:A9满足条件的单元格进行计数,所以,公式的第一个参数为A3:A9;
第二个参数,条件,条件是判断区域内的单元格是否含有“车间”二字,如果包含有,则进行计数,如果没有,则不进行计数。
从上面案例中我们知道,在excel里,*可以代替任意多个字符,所以,包含“车间”二字的字符串可以写为“*车间*”。
因此,最终的公式:
=countif(A3:A9,"*车间*")返回的结果为4。也就是说区域A3:A9里,有4个单元格的内容是包含有“车间”二字的。
【题目7】将每个部门中高于部门平均值标为绿色

首先,我们要把各部门的平均值算出来。
(1)把部门列复制出来,删除重复项,取得各部门名称

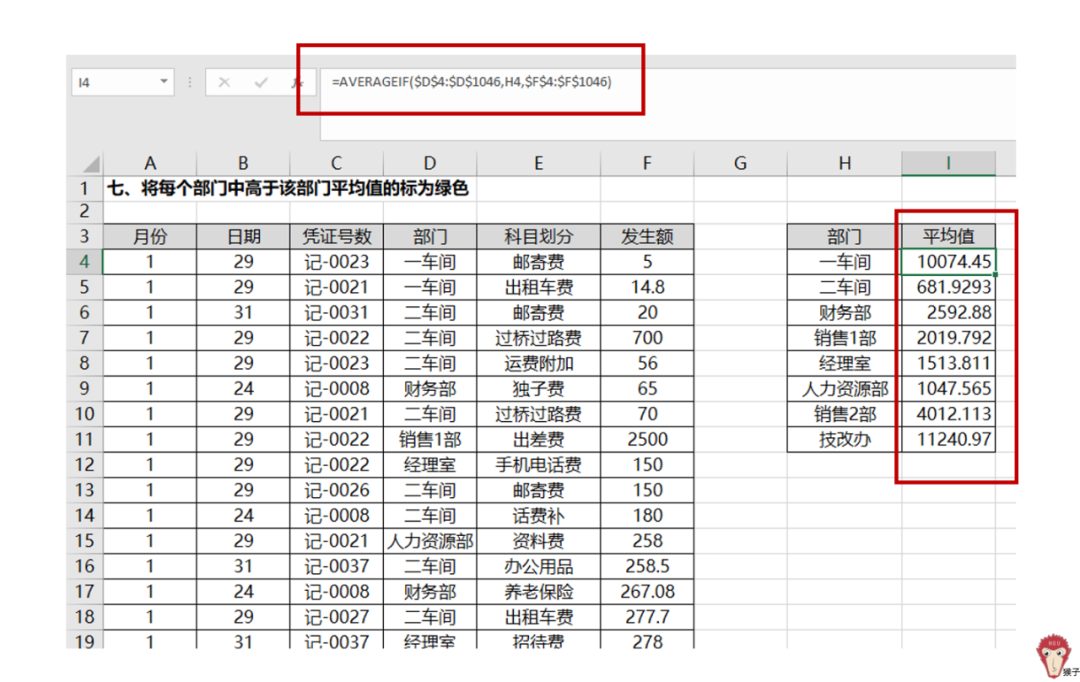
(2)用条件平均函数averageif,计算各部门的平均值。averageif,对指定区域内满足条件的值进行求平均。其语法为:
=averageif(条件区域, 条件,计算平均值的实际区域)所以,求各部门的平均值,其公式如下:
=averageif($D$4:$D$1046,H4,$F$4:$F$1046)求得各部门的平均值。
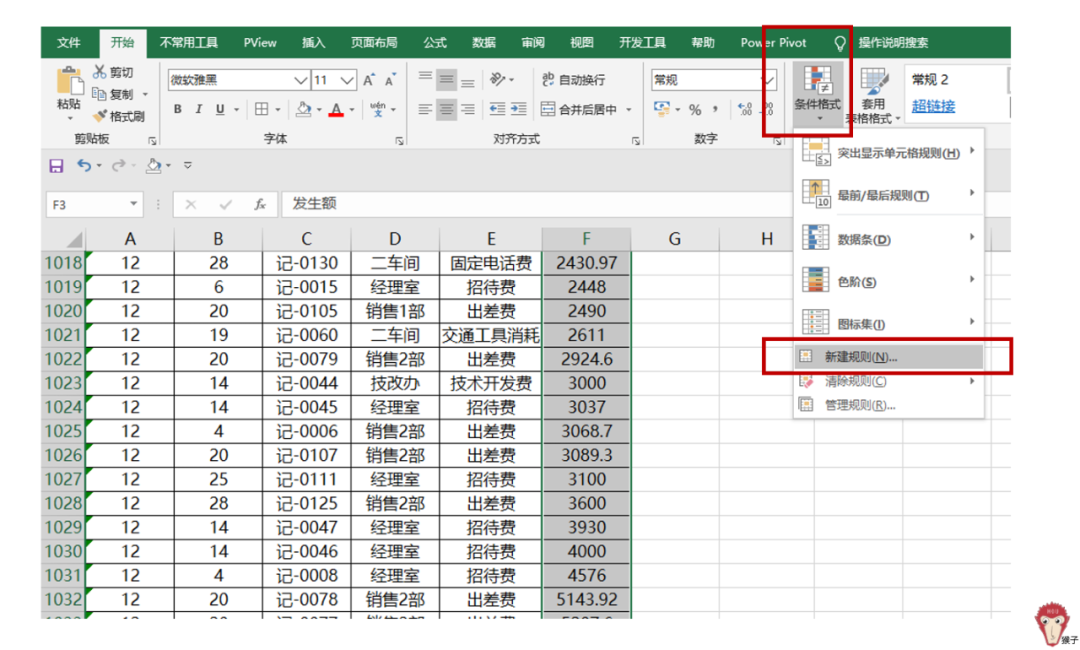
(3)进行条件格式设置:
选中要进行条件格式设置的区域,如“发生额”列,【开始】-【条件格式】-【新建规则】。
在弹出的【新建规则】对话框中,选择“使用公式确定要设置格式的单元格”,然后输入对应的公式:
=and($D4=$H$4,$F4>$I$4)
用and函数,即两个条件同时成立,才进行格式设置。如对“部门”列进行判断,是否等于一车间(即H4);对“发生额”列进行判断,是否大于一车间平均值(即I4); 如果两件条件同时满足,则对其进行绿色填充。
继续增加条件格式,重复上一步操作,我们还要对“部门”列是否是二车间,其“发生额”列是否大于二车间的平均值进行判断,如两条件同时满足,则填充绿色。
我们还要对“部门”列是否是财务部,其“发生额”列是否大于财务部的平均值进行判断,如两条件同时满足,则填充绿色。
……
最终结果如下:

如上图,部门为二车间的,其发生额值为700的,被标为了绿色,因为其值大于该部门的平均值681.9293。
总结
以上知识点包括有自定义数字格式、定位条件、批量填充、通配符实现模糊查找、自定义排序等,希望小伙伴能真正上手实操,熟练掌握。

python爬虫人工智能大数据公众号
