公司配备多卡的GPU服务器,当我们在上面跑程序的时候,当迭代次数或者epoch足够大的时候,我们通常会使用nn.DataParallel函数来用多个GPU来加速训练。一般我们会在代码中加入以下这句:device_ids = [0, 1]net = torch.nn.DataParallel(net, device_ids=device_ids)
似乎只要加上这一行代码,你在ternimal下执行watch -n 1 nvidia-smi后会发现确实会使用多个GPU来并行训练。但是细心点会发现其实第一块卡的显存会占用的更多一些,那么这是什么原因导致的?查阅pytorch官网的nn.DataParrallel相关资料,首先我们来看下其定义如下:CLASS torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0)
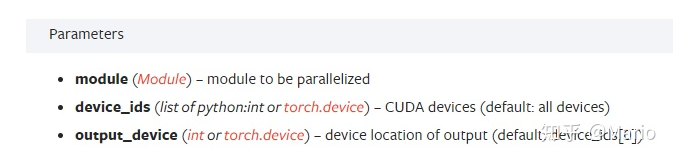
其中包含三个主要的参数:module,device_ids和output_device。官方的解释如下:module即表示你定义的模型,device_ids表示你训练的device,output_device这个参数表示输出结果的device,而这最后一个参数output_device一般情况下是省略不写的,那么默认就是在device_ids[0],也就是第一块卡上,也就解释了为什么第一块卡的显存会占用的比其他卡要更多一些。进一步说也就是当你调用nn.DataParallel的时候,只是在你的input数据是并行的,但是你的output loss却不是这样的,每次都会在第一块GPU相加计算,这就造成了第一块GPU的负载远远大于剩余其他的显卡。
下面来具体讲讲nn.DataParallel中是怎么做的。首先在前向过程中,你的输入数据会被划分成多个子部分(以下称为副本)送到不同的device中进行计算,而你的模型module是在每个device上进行复制一份,也就是说,输入的batch是会被平均分到每个device中去,但是你的模型module是要拷贝到每个devide中去的,每个模型module只需要处理每个副本即可,当然你要保证你的batch size大于你的gpu个数。然后在反向传播过程中,每个副本的梯度被累加到原始模块中。概括来说就是:DataParallel 会自动帮我们将数据切分 load 到相应 GPU,将模型复制到相应 GPU,进行正向传播计算梯度并汇总。The parallelized module must have its parameters and buffers on device_ids[0] before running this [DataParallel](https://link.zhihu.com/?target=https%3A//pytorch.org/docs/stable/nn.html%3Fhighlight%3Dtorch%2520nn%2520datapa%23torch.nn.DataParallel) module.意思就是:在运行此DataParallel模块之前,并行化模块必须在device_ids [0]上具有其参数和缓冲区。在执行DataParallel之前,会首先把其模型的参数放在device_ids[0]上,一看好像也没有什么毛病,其实有个小坑。我举个例子,服务器是八卡的服务器,刚好前面序号是0的卡被别人占用着,于是你只能用其他的卡来,比如你用2和3号卡,如果你直接指定device_ids=[2, 3]的话会出现模型初始化错误,类似于module没有复制到在device_ids[0]上去。那么你需要在运行train之前需要添加如下两句话指定程序可见的devices,如下:os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"os.environ["CUDA_VISIBLE_DEVICES"] = "2, 3"
当你添加这两行代码后,那么device_ids[0]默认的就是第2号卡,你的模型也会初始化在第2号卡上了,而不会占用第0号卡了。这里简单说一下设置上面两行代码后,那么对这个程序而言可见的只有2和3号卡,和其他的卡没有关系,这是物理上的号卡,逻辑上来说其实是对应0和1号卡,即device_ids[0]对应的就是第2号卡,device_ids[1]对应的就是第3号卡。device_ids = [0, 1]net = torch.nn.DataParallel(net, device_ids=device_ids)
这两行代码之前,一般放在train.py中import一些package之后。那么在训练过程中,你的优化器同样可以使用nn.DataParallel,如下两行代码:optimizer = torch.optim.SGD(net.parameters(), lr=lr)optimizer = nn.DataParallel(optimizer, device_ids=device_ids)
那么使用nn.DataParallel后,事实上DataParallel也是一个Pytorch的nn.Module,那么你的模型和优化器都需要使用.module来得到实际的模型和优化器,如下:保存模型:torch.save(net.module.state_dict(), path)加载模型:net=nn.DataParallel(Resnet18())net.load_state_dict(torch.load(path))net=net.module优化器使用:optimizer.step() --> optimizer.module.step()
还有一个问题就是,如果直接使用nn.DataParallel的时候,训练采用多卡训练,会出现一个warning:UserWarning: Was asked to gather along dimension 0, but all input tensors were scalars; will instead unsqueeze and return a vector.
首先说明一下:每张卡上的loss都是要汇总到第0张卡上求梯度,更新好以后把权重分发到其余卡。但是为什么会出现这个warning,这其实和nn.DataParallel中最后一个参数dim有关,其表示tensors被分散的维度,默认是0,nn.DataParallel将在dim0(批处理维度)中对数据进行分块,并将每个分块发送到相应的设备。单卡的没有这个warning,多卡的时候采用nn.DataParallel训练会出现这个warning,由于计算loss的时候是分别在多卡计算的,那么返回的也就是多个loss,你使用了多少个gpu,就会返回多少个loss。(有人建议DataParallel类应该有reduce和size_average参数,比如用于聚合输出的不同loss函数,最终返回一个向量,有多少个gpu,返回的向量就有几维。)关于这个问题在pytorch官网的issues上有过讨论,下面简单摘出一些。链接:https://github.com/pytorch/pytorch/issues/9811前期探讨中,有人提出求loss平均的方式会在不同数量的gpu上训练会以微妙的方式影响结果。模块返回该batch中所有损失的平均值,如果在4个gpu上运行,将返回4个平均值的向量。然后取这个向量的平均值。但是,如果在3个GPU或单个GPU上运行,这将不是同一个数字,因为每个GPU处理的batch size不同!举个简单的例子(就直接摘原文出来):A batch of 3 would be calculated on a single GPU and results would be [0.3, 0.2, 0.8] and model that returns the loss would return 0.43.If cast to DataParallel, and calculated on 2 GPUs, [GPU1 - batch 0,1], [GPU2 - batch 2] - return values would be [0.25, 0.8] (0.25 is average between 0.2 and 0.3)- taking the average loss of [0.25, 0.8] is now 0.525!Calculating on 3 GPUs, one gets [0.3, 0.2, 0.8] as results and average is back to 0.43!似乎一看,这么求平均loss确实有不合理的地方。那么有什么好的解决办法呢,可以使用size_average=False,reduce=True作为参数。每个GPU上的损失将相加,但不除以GPU上的批大小。然后将所有平行损耗相加,除以整批的大小,那么不管几块GPU最终得到的平均loss都是一样的。那pytorch贡献者也实现了这个loss求平均的功能,即通过gather的方式来求loss平均:https://github.com/pytorch/pytorch/pull/7973/commits/c285b3626a7a4dcbbddfba1a6b217a64a3f3f3be如果它们在一个有2个GPU的系统上运行,DP将采用多GPU路径,调用gather并返回一个向量。如果运行时有1个GPU可见,DP将采用顺序路径,完全忽略gather,因为这是不必要的,并返回一个标量。其实关于多卡训练还有DistributedDataParallel等其他方式,就等实验后继续补充啦。