
一篇文章教会你理解Scrapy网络爬虫框架的工作原理和数据采集过程
点击上方“i 小码哥”,进行关注
回复“自学”即可获赠 Python从入门到进阶 共5本电子书

今天小编给大家详细的讲解一下Scrapy爬虫框架,希望对大家的学习有帮助。
/ 01 / Scrapy爬虫框架
Scrapy是一个使用Python编程语言编写的爬虫框架,任何人都可以根据自己的需求进行修改,并且使用起来非常的方便。它可以应用在数据采集、数据挖掘、网络异常用户检测、存储数据等方面。
Scrapy使用了Twisted异步网络库来处理网络通讯。整体架构大致如下图所示。
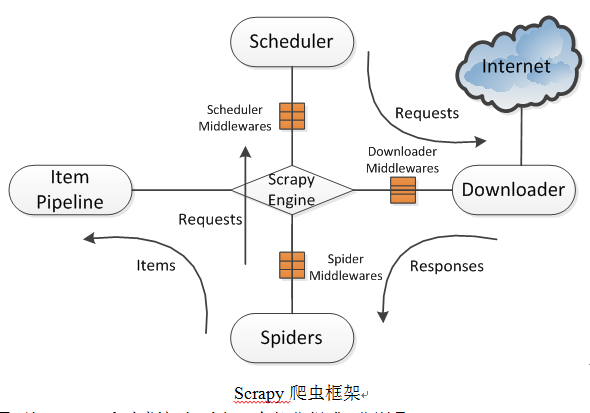
/ 02 / Scrapy爬虫框架组成
由上图可知Scrapy爬虫框架主要由5个部分组成,分别是:Scrapy Engine(Scrapy引擎),Scheduler(调度器),Downloader(下载器),Spiders(蜘蛛),Item Pipeline(项目管道)。爬取过程是Scrapy引擎发送请求,之后调度器把初始URL交给下载器,然后下载器向服务器发送服务请求,得到响应后将下载的网页内容交与蜘蛛来处理,尔后蜘蛛会对网页进行详细的解析。蜘蛛分析的结果有两种:一种是得到新的URL,之后再次请求调度器,开始进行新一轮的爬取,不断的重复上述过程;另一种是得到所需的数据,之后会转交给项目管道继续处理。项目管道负责数据的清洗、验证、过滤、去重和存储等后期处理,最后由Pipeline输出到文件中,或者存入数据库等。
/ 03 / 五大组件及其中间件的功能
这五大组件及其中间件的功能如下:
1) Scrapy引擎:控制整个系统的数据处理流程,触发事务处理流程,负责串联各个模块
2) Scheduler(调度器):维护待爬取的URL队列,当接受引擎发送的请求时,会从待爬取的URL队列中取出下一个URL返回给调度器。
3) Downloader(下载器):向该网络服务器发送下载页面的请求,用于下载网页内容,并将网页内容交与蜘蛛去处理。
4) Spiders(蜘蛛):制定要爬取的网站地址,选择所需数据内容,定义域名过滤规则和网页的解析规则等。
5) Item Pipeline(项目管道):处理由蜘蛛从网页中抽取的数据,主要任务是清洗、验证、过滤、去重和存储数据等。
6) 中间件(Middlewares):中间件是处于Scrapy引擎和Scheduler,Downloader,Spiders之间的构件,主要是处理它们之间的请求及响应。
Scrapy爬虫框架可以很方便的完成网上数据的采集工作,简单轻巧,使用起来非常方便。
/ 04 / 基于Scrapy的网络爬虫设计与实现
在了解Scrapy爬虫原理及框架的基础上,本节简要介绍Scrapy爬虫框架的数据采集过程。
4.1 建立爬虫项目文件
基于scrapy爬虫框架,只需在命令行中输入“scrapy startproject article”命令,之后一个名为article的爬虫项目将自动创建。首先进入到article文件夹下,输入命令“cd article”,之后通过“dir”查看目录,也可以通过“tree /f”生成文件目录的树形结构,如下图所示,可以很清晰的看到Scrapy创建命令生成的文件。
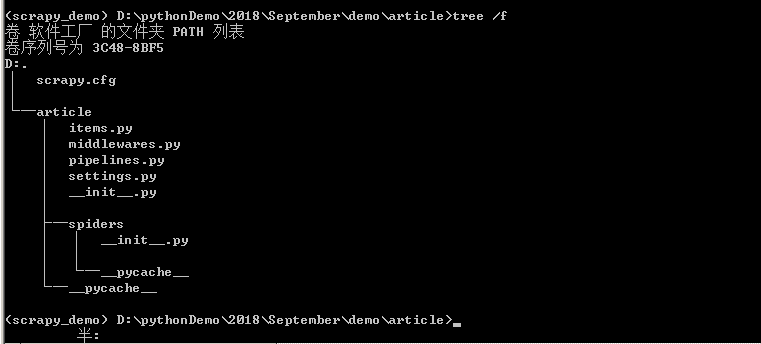
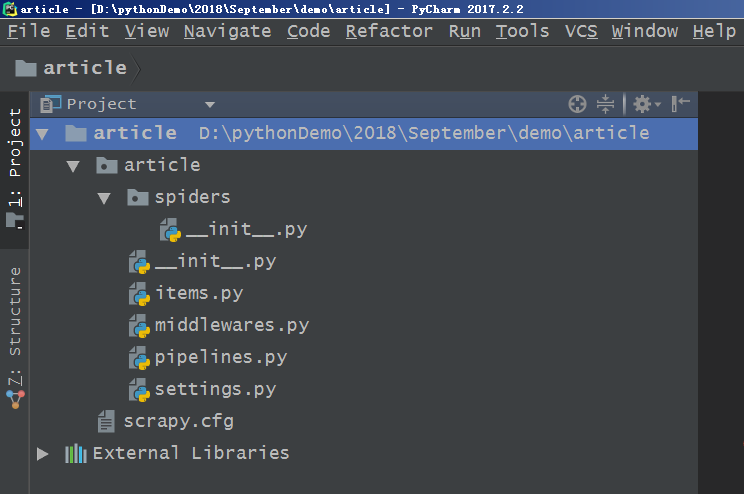
顶层的article文件夹是项目名,第二层中包含的是一个与项目名同名的文件夹article和一个文件scrapy.cfg,这个与项目同名的文件夹article是一个模块,所有的项目代码都在这个模块内添加,而scrapy.cfg文件是整个Scrapy项目的配置文件。第三层中有5个文件和一个文件夹,其中__init__.py是个空文件,作用是将其上级目录变成一个模块;items.py是定义储对象的文件,决定爬取哪些项目;middlewares.py文件是中间件,一般不用进行修改,主要负责相关组件之间的请求与响应;pipelines.py是管道文件,决定爬取后的数据如何进行处理和存储;settings.py是项目的设置文件,设置项目管道数据的处理方法、爬虫频率、表名等;spiders文件夹中放置的是爬虫主体文件(用于实现爬虫逻辑)和一个__init__.py空文件。
4.2 之后开始进行网页结构与数据分析、修改Items.py文件、编写hangyunSpider.py文件、修改pipelines.py文件、修改settings.py文件,这些步骤的具体操作后期会文章专门展开,在此不再赘述。
4.3 执行爬虫程序
修改上述四个文件之后,在Windows命令符窗口中输入cmd 命令进入到爬虫所在的路径,并执行“scrapy crawl article”命令,这样就可以运行爬虫程序了,最后保存数据到本地磁盘上。
/ 05 / 结束语
随着互联网信息的与日俱增,利用网络爬虫工具来获取所需信息必有用武之地。使用开源的Scrapy爬虫框架,不仅可以实现对web上信息的高效、准确、自动的获取,还利于研究人员对采集到的数据进行后续的挖掘分析。

--------------------- End ---------------------
后台回复关键字:自学,获取一份精心整理的 5本 Python 经典用书 后台回复关键字:国庆,获取50本电子书。 推荐阅读

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持。
做知识的传播者,随手转发,Python进阶者与您同行。