
字节跳动的算法面试题是什么难度?(第二弹)
点击蓝色“力扣加加”关注我哟
加个“星标”,带你揭开算法的神秘面纱!
❝这是力扣加加第「19」篇原创文章
❞
字节跳动的算法面试题是什么难度?(第二弹)
第一弹地址:字节跳动的算法面试题是什么难度?
由于 lucifer 我是一个小前端, 最近也在准备写一个《前端如何搞定算法面试》的专栏,因此最近没少看各大公司的面试题。都说字节跳动算法题比较难,我就先拿 ta 下手,做了几套 。这次我们就拿一套 字节跳动2017秋招编程题汇总来看下字节的算法笔试题的难度几何。地址:https://www.nowcoder.com/test/6035789/summary
这套题一共 11 道题, 三道编程题, 八道问答题。本次给大家带来的就是这三道编程题。更多精彩内容,请期待我的搞定算法面试专栏。
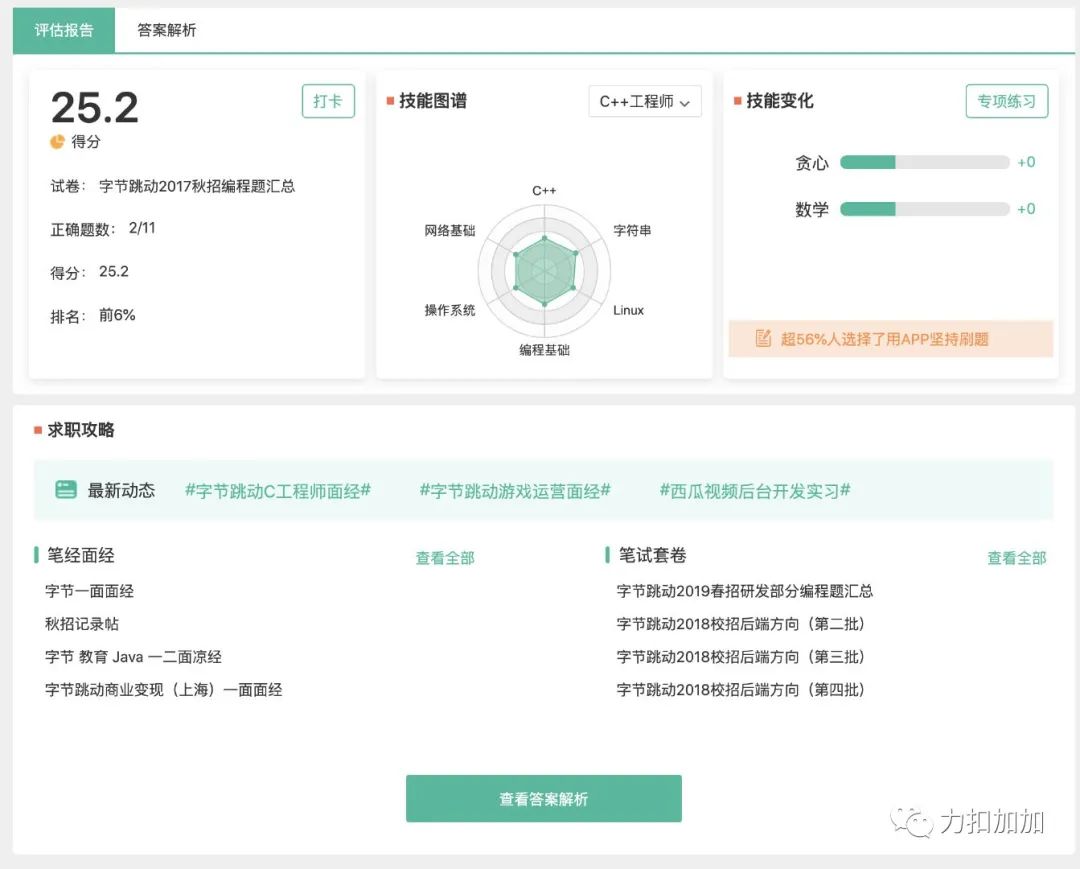
其中有一道题《异或》我没有通过所有的测试用例, 小伙伴可以找找茬,第一个找到并在公众号力扣加加留言的小伙伴奖励现金红包 10 元。
1. 头条校招
题目描述
头条的 2017 校招开始了!为了这次校招,我们组织了一个规模宏大的出题团队,每个出题人都出了一些有趣的题目,而我们现在想把这些题目组合成若干场考试出来,在选题之前,我们对题目进行了盲审,并定出了每道题的难度系统。一场考试包含 3 道开放性题目,假设他们的难度从小到大分别为 a,b,c,我们希望这 3 道题能满足下列条件:
a<=b<=c
b-a<=10
c-b<=10
所有出题人一共出了 n 道开放性题目。现在我们想把这 n 道题分布到若干场考试中(1 场或多场,每道题都必须使用且只能用一次),然而由于上述条件的限制,可能有一些考试没法凑够 3 道题,因此出题人就需要多出一些适当难度的题目来让每场考试都达到要求,然而我们出题已经出得很累了,你能计算出我们最少还需要再出几道题吗?
输入描述:
输入的第一行包含一个整数 n,表示目前已经出好的题目数量。
第二行给出每道题目的难度系数 d1,d2,...,dn。
数据范围
对于 30%的数据,1 ≤ n,di ≤ 5;
对于 100%的数据,1 ≤ n ≤ 10^5,1 ≤ di ≤ 100。
在样例中,一种可行的方案是添加 2 个难度分别为 20 和 50 的题目,这样可以组合成两场考试:(20 20 23)和(35,40,50)。
输出描述:
输出只包括一行,即所求的答案。
示例 1
输入
4
20 35 23 40
输出
2
思路
这道题看起来很复杂, 你需要考虑很多的情况。,属于那种没有技术含量,但是考验编程能力的题目,需要思维足够严密。这种「模拟的题目」,就是题目让我干什么我干什么。类似之前写的囚徒房间问题,约瑟夫环也是模拟,只不过模拟之后需要你剪枝优化。
这道题的情况其实很多, 我们需要考虑每一套题中的难度情况, 而不需要考虑不同套题的难度情况。题目要求我们满足:a<=b<=c b-a<=10 c-b<=10,也就是题目难度从小到大排序之后,相邻的难度不能大于 10 。
因此我们的思路就是先排序,之后从小到大遍历,如果满足相邻的难度不大于 10 ,则继续。如果不满足, 我们就只能让字节的老师出一道题使得满足条件。
由于只需要比较同一套题目的难度,因此我的想法就是「比较同一套题目的第二个和第一个,以及第三个和第二个的 diff」。
如果 diff 小于 10,什么都不做,继续。 如果 diff 大于 10,我们必须补充题目。
这里有几个点需要注意。
对于第二题来说:
比如 1 「20」 30 这样的难度。我可以在 1,20 之间加一个 11,这样 1,11,20 就可以组成一一套。 比如 1 「30」 60 这样的难度。我可以在 1,30 之间加 11, 21 才可以组成一套,自身(30)是无论如何都没办法组到这套题中的。
不难看出, 第二道题的临界点是 diff = 20 。小于等于 20 都可以将自身组到套题,增加一道即可,否则需要增加两个,并且自身不能组到当前套题。
对于第三题来说:
比如 1 20 「40」。我可以在 20,40 之间加一个 30,这样 1,20,30 就可以组成一一套,自身(40)是无法组到这套题的。 比如 1 20 「60」。也是一样的,我可以在 20,60 之间加一个 30,自身(60)同样是没办法组到这套题中的。
不难看出, 第三道题的临界点是 diff = 10 。小于等于 10 都可以将自身组到套题,否则需要增加一个,并且自身不能组到当前套题。
这就是所有的情况了。
有的同学比较好奇,我是怎么思考的。我是怎么「保障不重不漏」的。
实际上,这道题就是一个决策树, 我画个决策树出来你就明白了。
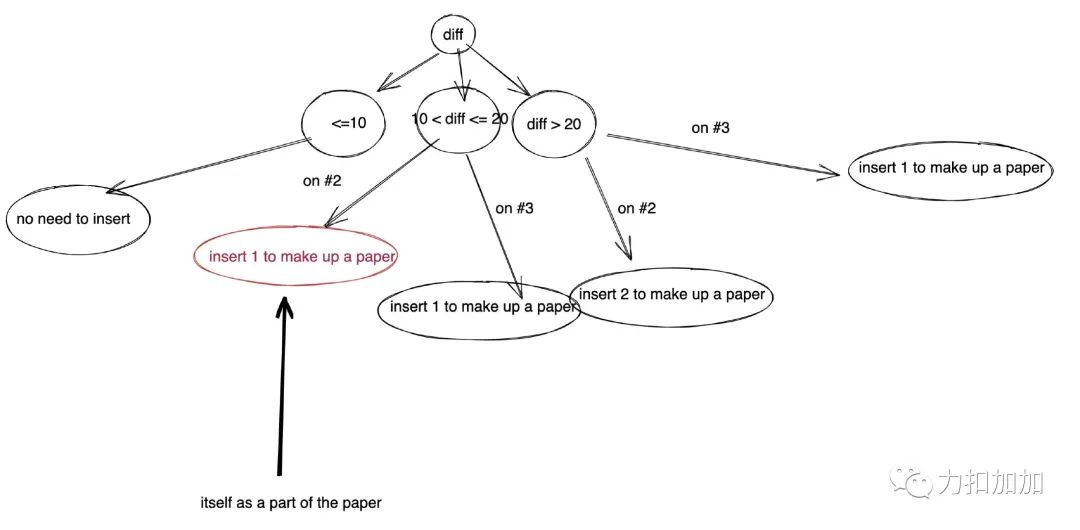
❝图中红色边框表示自身可以组成套题的一部分, 我也用文字进行了说明。#2 代表第二题, #3 代表第三题。
❞
从图中可以看出, 我已经考虑了所有情况。如果你能够像我一样画出这个决策图,我想你也不会漏的。当然我的解法并不一定是最优的,不过确实是一个非常好用,具有普适性的思维框架。
需要特别注意的是,由于需要凑整, 因此你需要使得题目的总数是 3 的倍数向上取整。
代码
n = int(input())
nums = list(map(int, input().split()))
cnt = 0
cur = 1
nums.sort()
for i in range(1, n):
if cur == 3:
cur = 1
continue
diff = nums[i] - nums[i - 1]
if diff <= 10:
cur += 1
if 10 < diff <= 20:
if cur == 1:
cur = 3
if cur == 2:
cur = 1
cnt += 1
if diff > 20:
if cur == 1:
cnt += 2
if cur == 2:
cnt += 1
cur = 1
print(cnt + 3 - cur)
「复杂度分析」
时间复杂度:由于使用了排序, 因此时间复杂度为 。(假设使用了基于比较的排序) 空间复杂度:
2. 异或
题目描述
给定整数 m 以及 n 各数字 A1,A2,..An,将数列 A 中所有元素两两异或,共能得到 n(n-1)/2 个结果,请求出这些结果中大于 m 的有多少个。
输入描述:
第一行包含两个整数 n,m.
第二行给出 n 个整数 A1,A2,...,An。
数据范围
对于 30%的数据,1 <= n, m <= 1000
对于 100%的数据,1 <= n, m, Ai <= 10^5
输出描述:
输出仅包括一行,即所求的答案
输入例子 1:
3 10
6 5 10
输出例子 1:
2
前置知识
异或运算的性质 如何高效比较两个数的大小(从高位到低位)
首先普及一下前置知识。第一个是异或运算:
异或的性质:两个数字异或的结果 a^b 是将 a 和 b 的二进制每一位进行运算,得出的数字。运算的逻辑是如果同一位的数字相同则为 0,不同则为 1
异或的规律:
任何数和本身异或则为 0
任何数和 0 异或是本身
异或运算满足交换律,即:a ^ b ^ c = a ^ c ^ b
同时建议大家去看下我总结的几道位运算的经典题目。 位运算系列[1]
其次要知道一个常识, 即比较两个数的大小, 我们是从高位到低位比较,这样才比较高效。
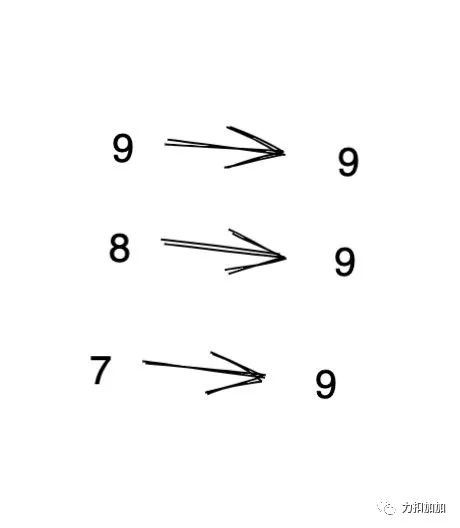
比如:
123
456
1234
这三个数比较大小, 为了方便我们先补 0 ,使得大家的位数保持一致。
0123
0456
1234
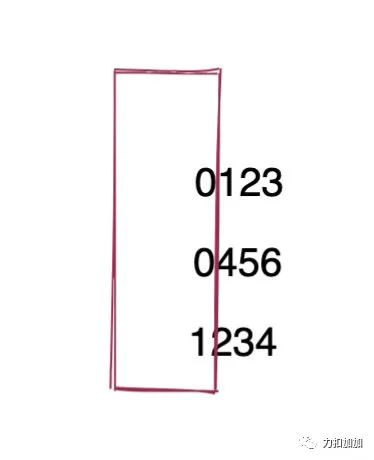
先比较第一位,1 比较 0 大, 因此 1234 最大。再比较第二位, 4 比 1 大, 因此 456 大于 123,后面位不需要比较了。这其实就是剪枝的思想。
有了这两个前提,我们来试下暴力法解决这道题。
思路
暴力法就是枚举 中组合, 让其两两按位异或,将得到的结果和 m 进行比较, 如果比 m 大, 则计数器 + 1, 最后返回计数器的值即可。
暴力的方法就如同题目描述的那样, 复杂度为 。一定过不了所有的测试用例, 不过大家实在没有好的解法的情况可以兜底。不管是牛客笔试还是实际的面试都是可行的。
接下来,让我们来「分析一下暴力为什么低效,以及如何选取数据结构和算法能够使得这个过程变得高效。」 记住这句话, 几乎所有的优化都是基于这种思维产生的,除非你开启了上帝模式,直接看了答案。只不过等你熟悉了之后,这个思维过程会非常短, 以至于变成条件反射, 你感觉不到有这个过程, 这就是「有了题感。」
其实我刚才说的第二个前置知识就是我们优化的关键之一。
我举个例子, 比如 3 和 5 按位异或。
3 的二进制是 011, 5 的二进制是 101,
011
101
按照我前面讲的异或知识, 不难得出其异或结构就是 110。
上面我进行了三次异或:
第一次是最高位的 0 和 1 的异或, 结果为 1。 第二次是次高位的 1 和 0 的异或, 结果为 1。 第三次是最低位的 1 和 1 的异或, 结果为 0。
那如何 m 是 1 呢?我们有必要进行三次异或么?实际上进行第一次异或的时候已经知道了一定比 m(m 是 1) 大。因为第一次异或的结构导致其最高位为 1,也就是说其最小也不过是 100,也就是 4,一定是大于 1 的。这就是「剪枝」, 这就是算法优化的关键。
❝看出我一步一步的思维过程了么?所有的算法优化都需要经过类似的过程。
❞
因此我的算法就是从高位开始两两异或,并且异或的结果和 m 对应的二进制位比较大小。
如果比 m 对应的二进制位大或者小,我们提前退出即可。 如果相等,我们继续往低位移动重复这个过程。
这虽然已经剪枝了,但是极端情况下,性能还是很差。比如:
m: 1111
a: 1010
b: 0101
a,b 表示两个数,我们比较到最后才发现,其异或的值和 m 相等。因此极端情况,算法效率没有得到改进。
这里我想到了一点,就是如果一个数 a 的前缀和另外一个数 b 的前缀是一样的,那么 c 和 a 或者 c 和 b 的异或的结构前缀部分一定也是一样的。比如:
a: 111000
b: 111101
c: 101011
a 和 b 有共同的前缀 111,c 和 a 异或过了,当再次和 b 异或的时候,实际上前三位是没有必要进行的,这也是重复的部分。这就是算法可以优化的部分, 这就是剪枝。
「分析算法,找到算法的瓶颈部分,然后选取合适的数据结构和算法来优化到。」 这句话很重要, 请务必记住。
在这里,我们用的就是剪枝技术,关于剪枝,91 天学算法也有详细的介绍。
回到前面讲到的算法瓶颈, 多个数是有共同前缀的, 前缀部分就是我们浪费的运算次数, 说到前缀大家应该可以想到前缀树。如果不熟悉前缀树的话,看下我的这个前缀树专题[2],里面的题全部手写一遍就差不多了。
因此一种想法就是建立一个前缀树, 「树的根就是最高的位」。由于题目要求异或, 我们知道异或是二进制的位运算, 因此这棵树要存二进制才比较好。
反手看了一眼数据范围:m, n<=10^5 。10^5 = 2 ^ x,我们的目标是求出 满足条件的 x 的 ceil(向上取整),因此 x 应该是 17。
树的每一个节点存储的是:「n 个数中,从根节点到当前节点形成的前缀有多少个是一样的」,即多少个数的前缀是一样的。这样可以剪枝,提前退出的时候,就直接取出来用了。比如异或的结果是 1, m 当前二进制位是 0 ,那么这个前缀有 10 个,我都不需要比较了, 计数器直接 + 10 。
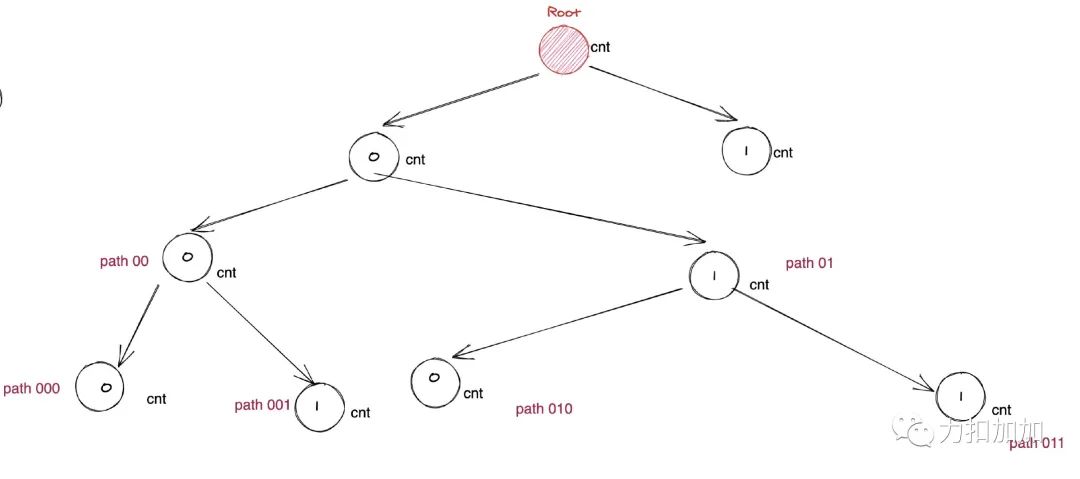
❝我用 17 直接复杂度过高,目前仅仅通过了 70 % - 80 % 测试用例, 希望大家可以帮我找找毛病,我猜测是语言的锅。
❞
代码
class TreeNode:
def __init__(self):
self.cnt = 1
self.children = [None] * 2
def solve(num, i, cur):
if cur == None or i == -1: return 0
bit = (num >> i) & 1
mbit = (m >> i) & 1
if bit == 0 and mbit == 0:
return (cur.children[1].cnt if cur.children[1] else 0) + solve(num, i - 1, cur.children[0])
if bit == 1 and mbit == 0:
return (cur.children[0].cnt if cur.children[0] else 0) + solve(num, i - 1, cur.children[1])
if bit == 0 and mbit == 1:
return solve(num, i - 1, cur.children[1])
if bit == 1 and mbit == 1:
return solve(num, i - 1, cur.children[0])
def preprocess(nums, root):
for num in nums:
cur = root
for i in range(16, -1, -1):
bit = (num >> i) & 1
if cur.children[bit]:
cur.children[bit].cnt += 1
else:
cur.children[bit] = TreeNode()
cur = cur.children[bit]
n, m = map(int, input().split())
nums = list(map(int, input().split()))
root = TreeNode()
preprocess(nums, root)
ans = 0
for num in nums:
ans += solve(num, 16, root)
print(ans // 2)
「复杂度分析」
时间复杂度: 空间复杂度:
3. 字典序
题目描述
给定整数 n 和 m, 将 1 到 n 的这 n 个整数按字典序排列之后, 求其中的第 m 个数。
对于 n=11, m=4, 按字典序排列依次为 1, 10, 11, 2, 3, 4, 5, 6, 7, 8, 9, 因此第 4 个数是 2.
对于 n=200, m=25, 按字典序排列依次为 1 10 100 101 102 103 104 105 106 107 108 109 11 110 111 112 113 114 115 116 117 118 119 12 120 121 122 123 124 125 126 127 128 129 13 130 131 132 133 134 135 136 137 138 139 14 140 141 142 143 144 145 146 147 148 149 15 150 151 152 153 154 155 156 157 158 159 16 160 161 162 163 164 165 166 167 168 169 17 170 171 172 173 174 175 176 177 178 179 18 180 181 182 183 184 185 186 187 188 189 19 190 191 192 193 194 195 196 197 198 199 2 20 200 21 22 23 24 25 26 27 28 29 3 30 31 32 33 34 35 36 37 38 39 4 40 41 42 43 44 45 46 47 48 49 5 50 51 52 53 54 55 56 57 58 59 6 60 61 62 63 64 65 66 67 68 69 7 70 71 72 73 74 75 76 77 78 79 8 80 81 82 83 84 85 86 87 88 89 9 90 91 92 93 94 95 96 97 98 99 因此第 25 个数是 120…
输入描述:
输入仅包含两个整数 n 和 m。
数据范围:
对于 20%的数据, 1 <= m <= n <= 5 ;
对于 80%的数据, 1 <= m <= n <= 10^7 ;
对于 100%的数据, 1 <= m <= n <= 10^18.
输出描述:
输出仅包括一行, 即所求排列中的第 m 个数字.
示例 1
输入
11 4
输出
2
前置知识
十叉树 完全十叉树 计算完全十叉树的节点个数 字典树
思路
和上面题目思路一样, 先从暴力解法开始,尝试打开思路。
暴力兜底的思路是直接生成一个长度为 n 的数组, 排序,选第 m 个即可。代码:
n, m = map(int, input().split())
nums = [str(i) for i in range(1, n + 1)]
print(sorted(nums)[m - 1])
「复杂度分析」
时间复杂度:取决于排序算法, 不妨认为是 空间复杂度:
这种算法可以 pass 50 % case。
上面算法低效的原因是开辟了 N 的空间,并对整 N 个 元素进行了排序。
一种简单的优化方法是将排序换成堆,利用堆的特性求第 k 大的数, 这样时间复杂度可以减低到 。
我们继续优化。实际上,你如果把字典序的排序结构画出来, 可以发现他本质就是一个十叉树,并且是一个完全十叉树。
接下来,我带你继续分析。
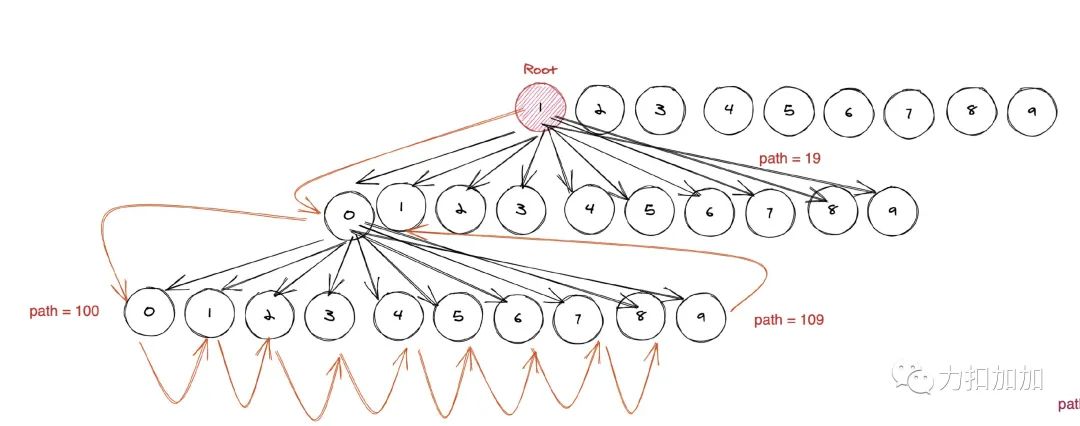
如图, 红色表示根节点。节点表示一个十进制数, 「树的路径存储真正的数字」,比如图上的 100,109 等。这不就是上面讲的前缀树么?
如图黄色部分, 表示字典序的顺序,注意箭头的方向。因此本质上,「求字典序第 m 个数, 就是求这棵树的前序遍历的第 m 个节点。」
因此一种优化思路就是构建一颗这样的树,然后去遍历。构建的复杂度是 ,遍历的复杂度是 。因此这种算法的复杂度可以达到 ,由于 n >= m,因此就是 。
实际上, 这样的优化算法依然是无法 AC 全部测试用例的,会超内存限制。因此我们的思路只能是不使用 N 的空间去构造树。想想也知道, 由于 N 最大可能为 10^18,一个数按照 4 字节来算, 那么这就有 400000000 字节,大约是 381 M,这是不能接受的。
上面提到这道题就是一个完全十叉树的前序遍历,问题转化为求完全十叉树的前序遍历的第 m 个数。
❝十叉树和二叉树没有本质不同, 我在二叉树专题部分, 也提到了 N 叉树都可以用二叉树来表示。
❞
对于一个节点来说,第 m 个节点:
要么就是它本身 要么其孩子节点中 要么在其兄弟节点 要么在兄弟节点的孩子节点中
究竟在上面的四个部分的哪,取决于其孩子节点的个数。
count > m ,m 在其孩子节点中,我们需要深入到子节点。 count <= m ,m 不在自身和孩子节点, 我们应该跳过所有孩子节点,直接到兄弟节点。
这本质就是一个递归的过程。
需要注意的是,我们并不会真正的在树上走,因此上面提到的「深入到子节点」, 以及 「跳过所有孩子节点,直接到兄弟节点」如何操作呢?
你仔细观察会发现:如果当前节点的前缀是 x ,那么其第一个子节点(就是最小的子节点)是 x * 10,第二个就是 x * 10 + 1,以此类推。因此:
深入到子节点就是 x * 10。 跳过所有孩子节点,直接到兄弟节点就是 x + 1。
ok,铺垫地差不多了。
接下来,我们的重点是「如何计算给定节点的孩子节点的个数」。
这个过程和完全二叉树计算节点个数并无二致,这个算法的时间复杂度应该是 。如果不会的同学,可以参考力扣原题: 222. 完全二叉树的节点个数[3] ,这是一个难度为中等的题目。
❝因此这道题本身被划分为 hard,一点都不为过。
❞
这里简单说下,计算给定节点的孩子节点的个数的思路, 我的 91 天学算法里出过这道题。
一种简单但非最优的思路是分别计算左右子树的深度。
如果当前节点的左右子树高度相同,那么左子树是一个满二叉树,右子树是一个完全二叉树。 否则(左边的高度大于右边),那么左子树是一个完全二叉树,右子树是一个满二叉树。
如果是满二叉树,当前节点数 是 2 ^ depth,而对于完全二叉树,我们继续递归即可。
class Solution:
def countNodes(self, root):
if not root:
return 0
ld = self.getDepth(root.left)
rd = self.getDepth(root.right)
if ld == rd:
return 2 ** ld + self.countNodes(root.right)
else:
return 2 ** rd + self.countNodes(root.left)
def getDepth(self, root):
if not root:
return 0
return 1 + self.getDepth(root.left)
「复杂度分析」
时间复杂度: 空间复杂度:
而这道题, 我们可以更简单和高效。
比如我们要计算 1 号节点的子节点个数。
它的孩子节点个数是 。。。 它的孙子节点个数是 。。。 。。。
全部加起来即可。
它的孩子节点个数是 20 - 10 = 10 。也就是它的「右边的兄弟节点的第一个子节点」 减去 它的「第一个子节点」。

由于是完全十叉树,而不是满十叉树 。因此你需要考虑边界情况,比如题目的 n 是 15。那么 1 的子节点个数就不是 20 - 10 = 10 了, 而是 15 - 10 + 1 = 16。
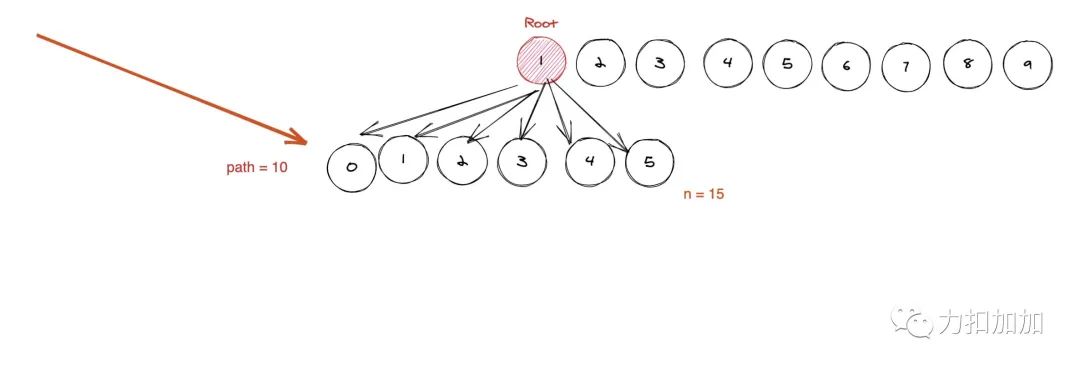
其他也是类似的过程, 我们只要:
Go deeper and do the same thing
或者:
Move to next neighbor and do the same thing
不断重复,直到 m 降低到 0 。
代码
def count(c1, c2, n):
steps = 0
while c1 <= n:
steps += min(n + 1, c2) - c1
c1 *= 10
c2 *= 10
return steps
def findKthNumber(n: int, k: int) -> int:
cur = 1
k = k - 1
while k > 0:
steps = count(cur, cur + 1, n)
if steps <= k:
cur += 1
k -= steps
else:
cur *= 10
k -= 1
return cur
n, m = map(int, input().split())
print(findKthNumber(n, m))
「复杂度分析」
时间复杂度: 空间复杂度:
总结
其中三道算法题从难度上来说,基本都是困难难度。从内容来看,基本都是力扣的换皮题,且都或多或少和树有关。如果大家一开始没有思路,建议大家先给出暴力的解法兜底,再画图或举简单例子打开思路。
我也刷了很多字节的题了,还有一些难度比较大的题。如果你第一次做,那么需要你思考比较久才能想出来。加上面试紧张,很可能做不出来。这个时候就更需要你冷静分析,先暴力打底,慢慢优化。有时候即使给不了最优解,让面试官看出你的思路也很重要。比如小兔的棋盘[4] 想出最优解难度就不低,不过你可以先暴力 DFS 解决,再 DP 优化会慢慢帮你打开思路。有时候面试官也会引导你,给你提示, 加上你刚才“发挥不错”,说不定一下子就做出最优解了,这个我深有体会。
另外要提醒大家的是, 刷题要适量,不要贪多。要完全理清一道题的来龙去脉。多问几个为什么。这道题暴力法怎么做?暴力法哪有问题?怎么优化?为什么选了这个算法就可以优化?为什么这种算法要用这种数据结构来实现?
更多题解可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。目前已经 36K+ star 啦。
Reference
位运算系列: https://leetcode-cn.com/problems/single-number/solution/zhi-chu-xian-yi-ci-de-shu-xi-lie-wei-yun-suan-by-3/
[2]前缀树专题: https://github.com/azl397985856/leetcode/blob/master/thinkings/trie.md
[3]22. 完全二叉树的节点个数]: https://leetcode-cn.com/problems/count-complete-tree-nodes/
[4]小兔的棋盘: https://github.com/azl397985856/leetcode/issues/429
推荐阅读
1、力扣刷题插件
如果觉得文章不错,帮忙点个在看呗