
字节跳动2月中旬算法实习生面试题分享

问题1:LSTM原理
LSTM是循环神经网络RNN的变种,包含三个门,分别是输入门,遗忘门和输出门。
LSTM 与 GRU区别
(1)LSTM和GRU的性能在很多任务上不分伯仲;
(2)GRU参数更少,因此更容易收敛,但是在大数据集的情况下,LSTM性能表现更好;
(3)GRU 只有两个门(update和reset),LSTM 有三个门(forget,input,output),GRU 直接将hidden state 传给下一个单元,而 LSTM 用memory cell 把hidden state 包装起来。

问题2:Transformer的原理
Transformer本身是一个典型的encoder-decoder模型,Encoder端和Decoder端均有6个Block,Encoder端的Block包括两个模块,多头self-attention模块以及一个前馈神经网络模块;
Decoder端的Block包括三个模块,多头self-attention模块,多头Encoder-Decoder attention交互模块,以及一个前馈神经网络模块;
需要注意:Encoder端和Decoder端中的每个模块都有残差层和Layer Normalization层。
问题3:Transformer的计算公式,K,Q,V怎么算
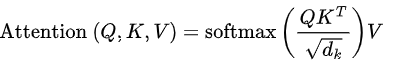
Q、K、V分别是输入X线性变换得到的。
问题4:Transformer为什么要用多头
多次attention综合的结果至少能够起到增强模型的作用,也可以类比CNN中同时使用多个卷积核的作用,直观上讲,多头的注意力有助于网络捕捉到更丰富的特征/信息。
问题5:transformer里的残差连接在CV哪里用到了(resnet),resnet的思想
在transformer的encoder和decoder中,各用到了6层的attention模块,每一个attention模块又和一个FeedForward层(简称FFN)相接。
对每一层的attention和FFN,都采用了一次残差连接,即把每一个位置的输入数据和输出数据相加,使得Transformer能够有效训练更深的网络。在残差连接过后,再采取Layer Nomalization的方式。
resnet的思想:残差模块能让训练变得更加简单,如果输入值和输出值的差值过小,那么可能梯度会过小,导致出现梯度小时的情况,残差网络的好处在于当残差为0时,改成神经元只是对前层进行一次线性堆叠,使得网络梯度不容易消失,性能不会下降。
问题6:relu的公式,relu在0的位置可导吗,不可导怎么处理
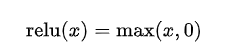
针对这种类型的激活函数,可以使用次梯度来解决。
次梯度方法(subgradient method)是传统的梯度下降方法的拓展,用来处理不可导的凸函数。它的优势是比传统方法处理问题范围大,劣势是算法收敛速度慢。但是,由于它对不可导函数有很好的处理方法,所以学习它还是很有必要的。
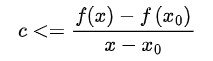
对于relu函数,当x>0时,导数为1,当x<0时导数为0。因此relu函数在x=0的次梯度c ∈ [ 0 , 1 ],c可以取[0,1]之间的任意值。
问题7:神经网络都有哪些正则化操作?BN和LN分别用在哪?
最常用的正则化技术是dropout,随机的丢掉一些神经元。还有数据增强,早停,L1正则化,L2正则化等。
Batch Normalization 是对这批样本的同一维度特征做归一化, Layer Normalization 是对这单个样本的所有维度特征做归一化。
BN用在图像较多,LN用在文本较多。
问题8:Attention和全连接的区别是啥?
Attention的最终输出可以看成是一个“在关注部分权重更大的全连接层”。但是它与全连接层的区别在于,注意力机制可以利用输入的特征信息来确定哪些部分更重要。
全连接的作用的是对一个实体进行从一个特征空间到另一个特征空间的映射,而注意力机制是要对来自同一个特征空间的多个实体进行整合。
全连接的权重对应的是一个实体上的每个特征的重要性,而注意力机制的输出结果是各个实体的重要性。比如说,一个单词“love”在从200维的特征空间转换到100维的特征空间时,使用的是全连接,不需要注意力机制,因为特征空间每一维的意义是固定的。
而如果我们面对的是词组“I love you”,需要对三个200维的实体特征进行整合,整合为一个200维的实体,此时就要考虑到实体间的位置可能发生变化,我们下次收到的句子可能是“love you I”,从而需要一个与位置无关的方案。
问题9:Leetcode11. 盛水最多的容器
思路:
从两端往中间走,谁小谁动,一样的情况下谁动都行;
记录每一步 min(X, Y) * distance;
在头尾相遇时结束,也就是 O(n) 时间复杂度与 O(1) 空间复杂度。
注意:两端往中间走,移动高度小的数,每走一步计算一下。
参考代码:

问题10、Leetcode1884.鸡蛋掉落-两枚鸡蛋
思路很简单,从n开始往下递推
比如题解中给的n=100,从100,99,97,94..楼分别往下丢,可以发现这些楼层的间隔是从1,2,3,4不断增加的,直到34,22,9,间隔为12,13,9(最后的间隔是因为不够了,可以看成是14,也就是需要输出的答案)
所以直接开始推,设置cur为间隔,total为总楼层,每次total += cur + 1(+1是因为要算上自己本身所在的楼层)
最后的间隔就是我们需要的答案了


— 推荐阅读 —
最新大厂面试题
学员最新面经分享
七月内推岗位
AI开源项目论文
NLP ( 自然语言处理 )
CV(计算机视觉)
推荐