
数据集中存在错误标注怎么办? 置信学习帮你解决
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

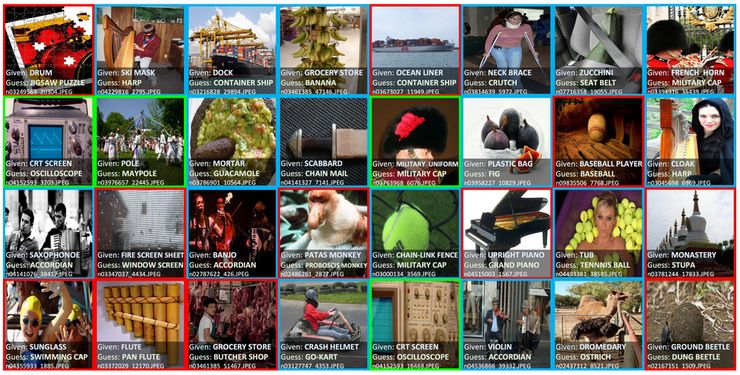
多标签图像(蓝色):在图像中有多个标签 本体论问题(绿色):包括“是”或 “有”两种关系,在这些情况下,数据集应该包含其中一类 标签错误(红色):数据集别的类的标签比给定的类标签更适合于某个示例

什么是置信学习?
描述标签噪声 查找标签错误 学习噪声标签 发现本体论问题
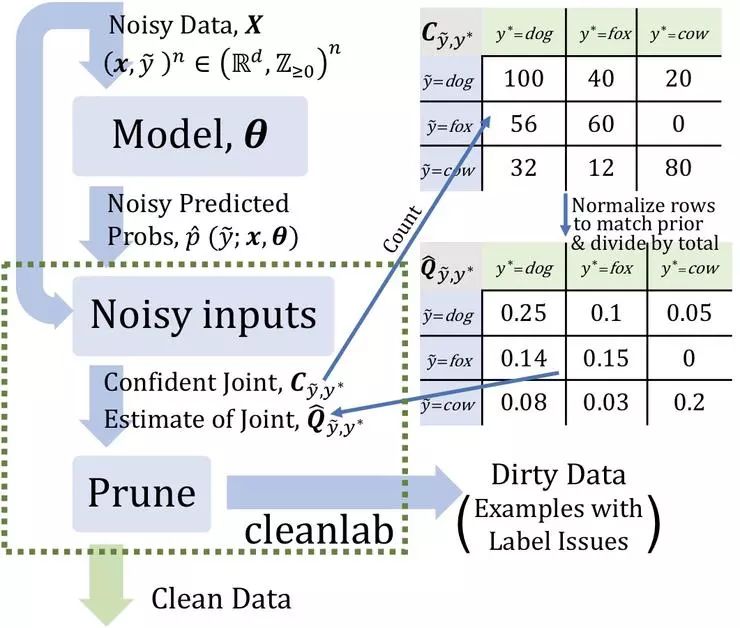
样本外预测概率(矩阵大小:类的样本数) 噪声标签(矢量长度:示例数)
估计给定噪声标签和潜在(未知)未损坏标签的联合分布,以充分描述类条件标签噪声 查找并删除带有标签问题的噪音示例 去除训练误差,通过估计潜在先验重新加权实例
置信学习的优点
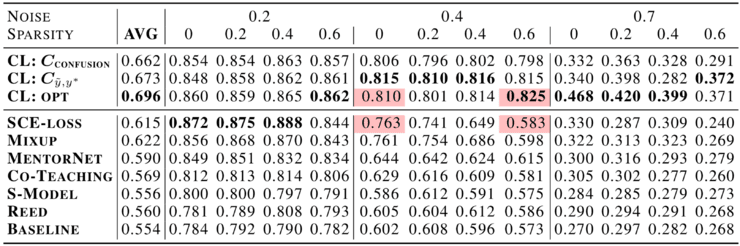
直接估计噪声和真标签的联合分布 适用于多类数据集 查找标签错误(错误按最有可能到最不可能的顺序排列) 是非迭代的(在 ImageNet 中查找训练标签错误需要 3 分钟) 在理论上是合理的(现实条件下准确地找到标签误差和联合分布的一致估计) 不假设标签噪声是随机均匀的(在实践中通常行不通) 只需要预测概率和噪声标签(可以使用任何模型) 不需要任何真实(保证不损坏)的标签 自然扩展到多标签数据集 作为 cleanlab Python 包,它是免费、开源的,用于描述、查找和学习标签错误
置信学习的原则
剪枝以搜索标签错误。例如,通过损失重加权使用软剪枝,以避免迭代重标记的收敛陷阱。 对干净数据进行统计训练,避免在不完全预测概率的情况下重新加权损失(Natarajan et al.,2017),从而避免学习模型权重中的错误传播。 对训练期间使用的示例进行排序,以允许使用不规范概率或 SVM 决策边界距离进行学习。
置信学习是如何工作的?
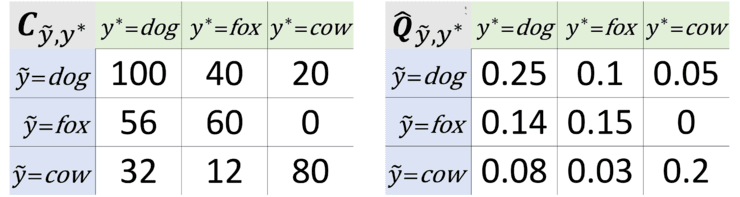
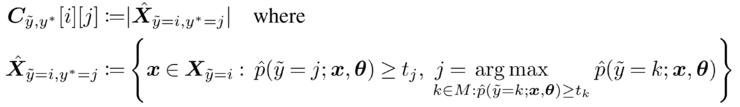
使用标签噪声的联合分布查找标签问题
将联合分布矩阵乘以示例数。让我们假设我们的数据集中有 100 个示例。所以,在上图中(右边的 Q 矩阵),有 10 个标记为 dog 的图像实际上是狐狸的图像。 将 10 张标记为 dog 的图片标记为标签问题,其中属于 fox 类的可能性最大。 对矩阵中的所有非对角项重复此操作。
置信学习的实际应用
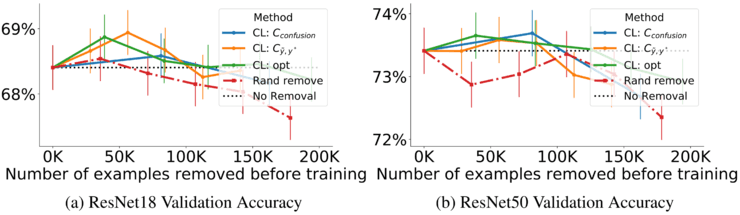


最后的想法
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
评论