
PDF文件信息不会提取怎么办??别急!Python帮你解决
点击上方“数据管道”,选择“置顶星标”公众号
干货福利,第一时间送达

01. 引言
02. pdfplumber简介及安装
pip install pdfplumber03. pdf文件主要信息(表格+文本)提取
具体的属性及基本使用方法大家都可以去官网自己查看,这里仅介绍常用信息(表格+文本)的提取方法,文件也是使用官网提供的。
(1)表格信息提取
表格提取方法主要包括find_tables()、extract_tables()、extract_table()以及debug_tablefinder()。我们提取表格信息主要使用extract_tables()、extract_table() 方法,而debug_tablefinder() 则是查看表格信息提取的依据。官网解释如下:
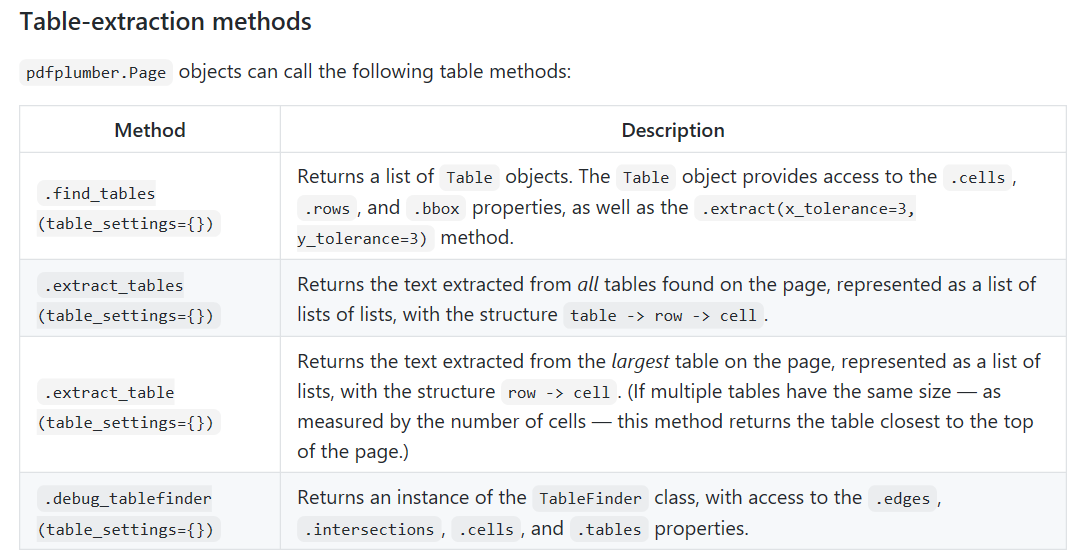
接下来,我们使用extract_table()结合具体的pdf文件进行介绍说明。Pdf文件信息如下(部分):
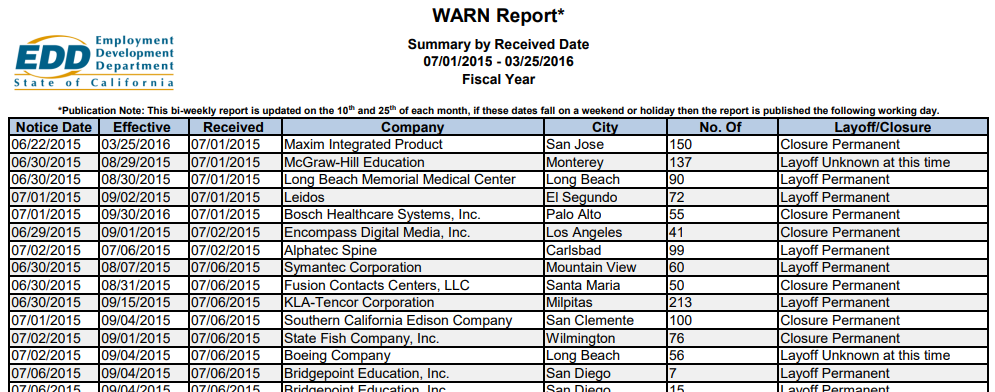
提取数据:
import pandas as pdimport pdfplumberpdf = r"pdfplumber-stable\examples\pdfs\ca-warn-report.pdf"ta_pdf = pdfplumber.open(pdf)ta_pdf_info = ta_pdf.pages[0] #获取pdf文件第一页信息tables = ta_pdf_info.extract_table() #获取表格信息tabes[:3]
结果显示如下:
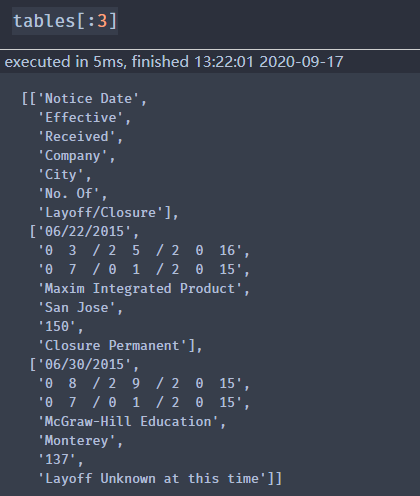
使用.extract_table从页面上最大的表中获取数据:.extract_table返回一个镶嵌列表,每个内部列表为表中的一行,对比pdf文件可以发现,主要的信息我们已经提取出来,接下来我们对信息进行保存。
信息保存:
table_df = pd.DataFrame(tables[1:],columns=tables[0])table_df.head()
结果如下:

这样我们就完美的提取pdf第一页表格信息了,可以发现,Effective和Received列由于是直接提取,导致文本之间存在空格,接下来整理下即可,代码如下:
for column in ["Effective", "Received"]:table_df[column] = table_df[column].str.replace(" ", "")table_df.head()
结果如下:

通过pandas的to_excel等文件保存方法即可实现文件另存。到此,我们就实现了pdf第一页表格信息的提取、整理和另存。若想对多页进行批量处理,进行简单的循环处理即可。
此外,我们还可以直接通过 within_bbox()方法直接定位我们需要提取信息的位置进行特定位置信息的提取。within_bbox() 介绍如下:
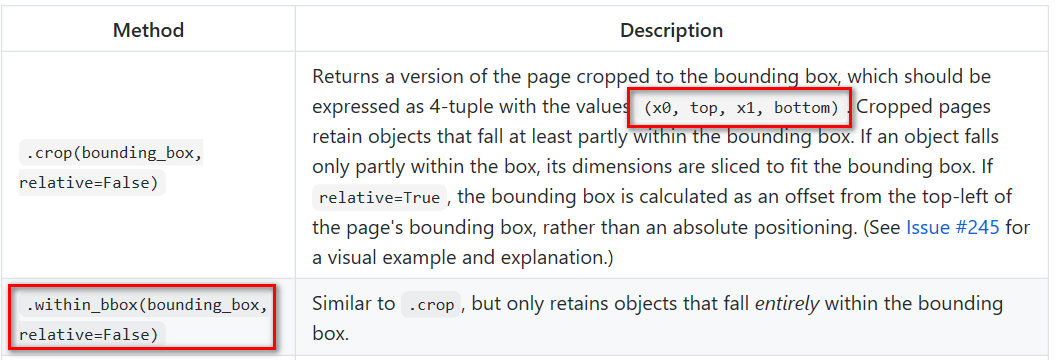
(2)文本信息提取
文本信息的提取主要使用extract_text()方法,这里使用的pdf文件预览如下(部分):
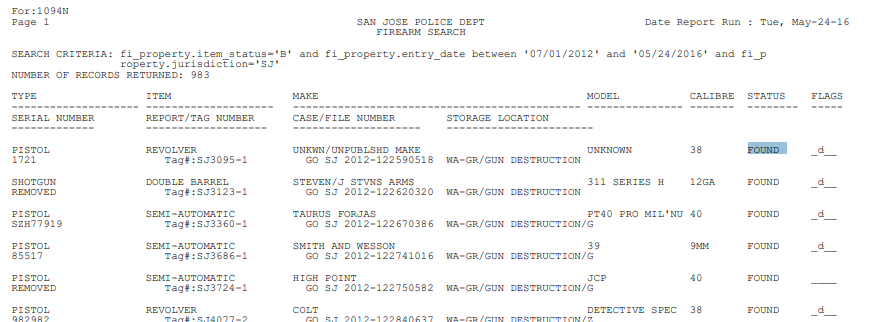
提取文本信息代码如下:
file = r"pdfplumber-stable\examples\pdfs\san-jose-pd-firearm-sample.pdf"text_pdf = pdfplumber.open(file)text_info = text_pdf.pages[0]text = text_info.extract_text()print(text)
结果为:
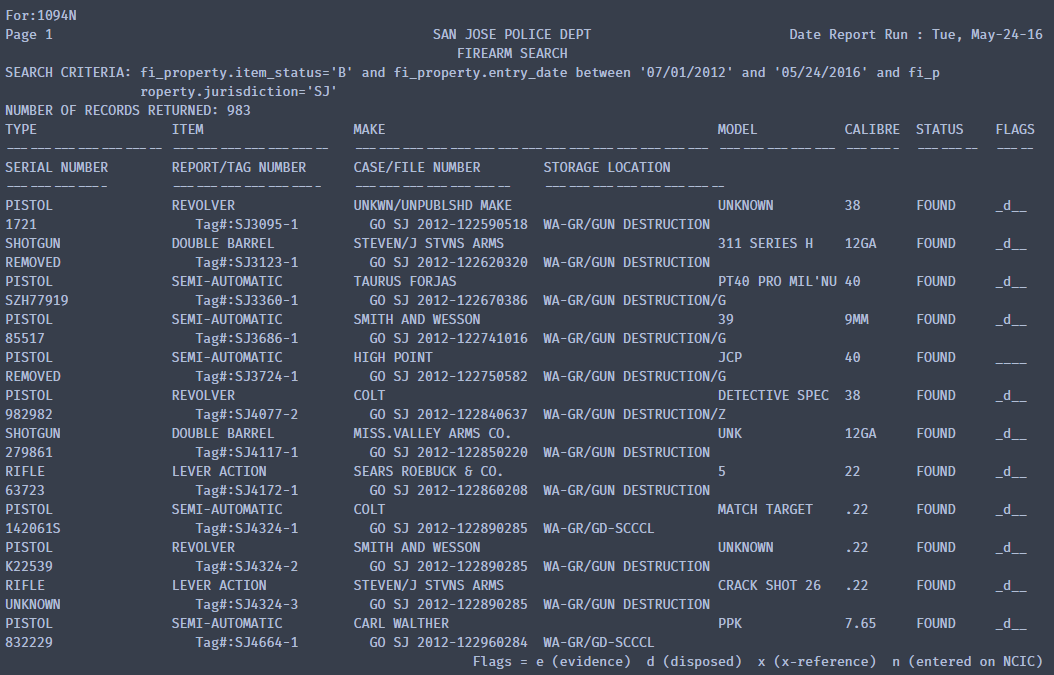
对比pdf可知,文本信息已全部提出。这里我们就可以使用正则表达式对提取信息进行筛选。代码如下:
core_part = re.compile(r"LOCATION[\-\s]+(.*)\n\s+Flags = e", re.DOTALL)core = re.search(core_part, text).group(1)print(core)
这里解释下:LOCATION[\-\s]+(.*)\n\s+Flags = e 就是匹配 LOCATION 和 Flags = e 字符串 之间的所有元素,无论换行还是空格等。结果如下:
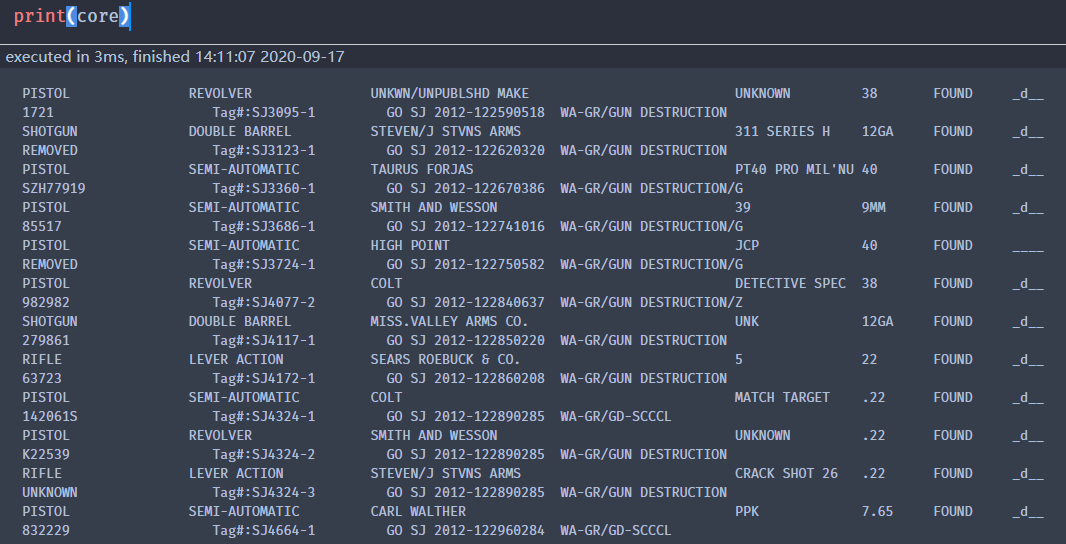
由于使用print()方法进行输出,结果较为规范,但实际情况如下:
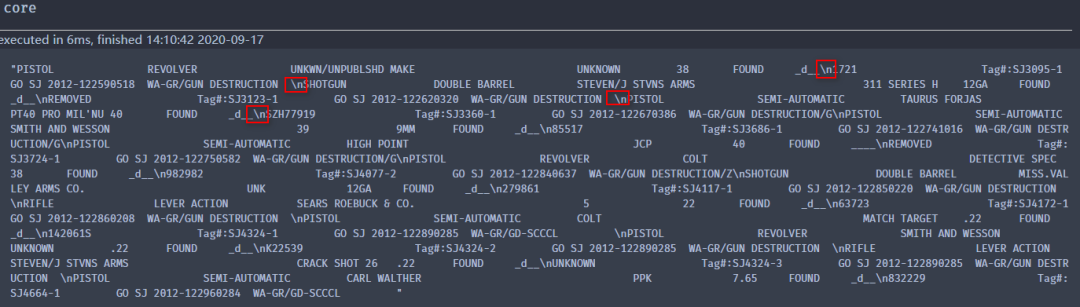
含有多个换行符号(\n),接下来以此为依据进行拆分(split),如下:
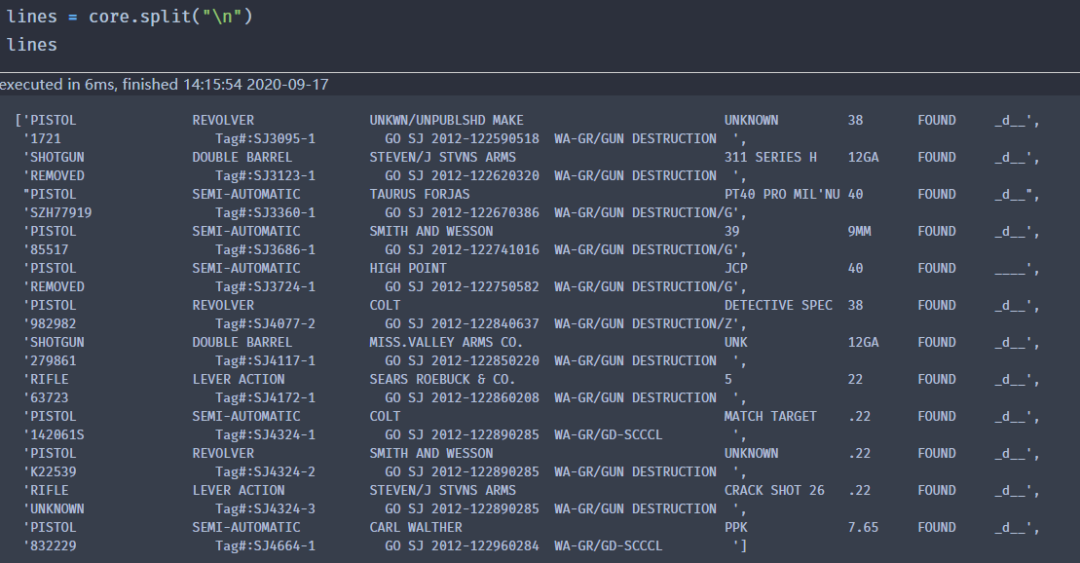
再对结果进行提取,代码如下:
line_groups = list(zip(lines[::2], lines[1::2]))line_groups
结果如下:
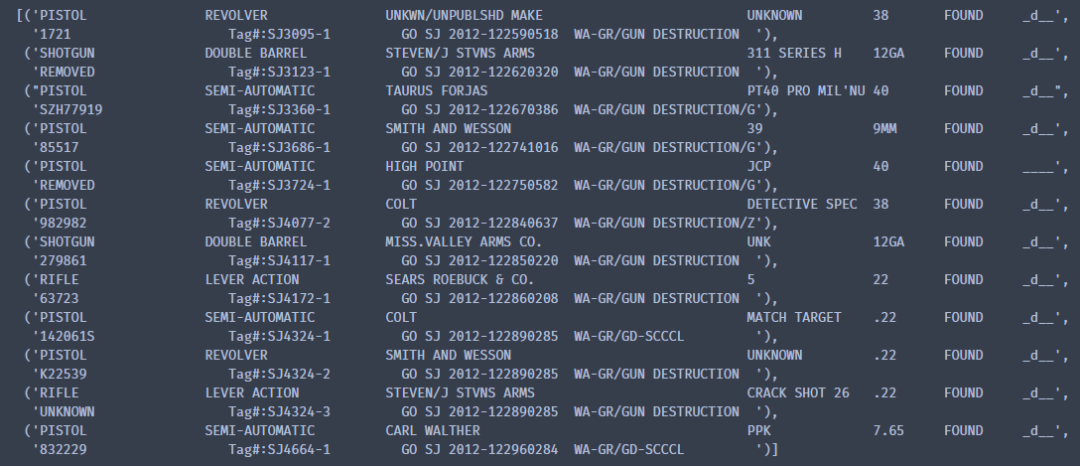
最后使用collections模块中的OrderedDict类 进行字典有序排列,构建pandas所需数据,具体代码如下:
from collections import OrderedDictline_groups = list(zip(lines[::2], lines[1::2]))def parse_row(first_line, second_line):return OrderedDict([("type", first_line[:20].strip()),("item", first_line[21:41].strip()),("make", first_line[44:89].strip()),("model", first_line[90:105].strip()),("calibre", first_line[106:111].strip()),("status", first_line[112:120].strip()),("flags", first_line[124:129].strip()),("serial_number", second_line[0:13].strip()),("report_tag_number", second_line[21:41].strip()),("case_file_number", second_line[44:64].strip()),("storage_location", second_line[68:91].strip())])parsed = [ parse_row(first_line, second_line)for first_line, second_line in line_groups ]parsed[:2]
结果如下:
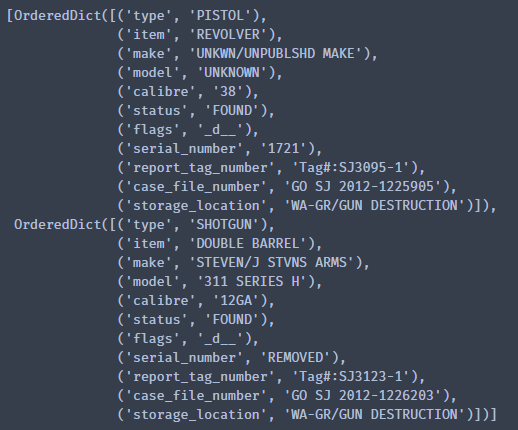
可以看出,数据已经过整合并符合pandas 构建数据DataFrame形式。如下:
text_df = pd.DataFrame(parsed)text_df
结果如下(部分):
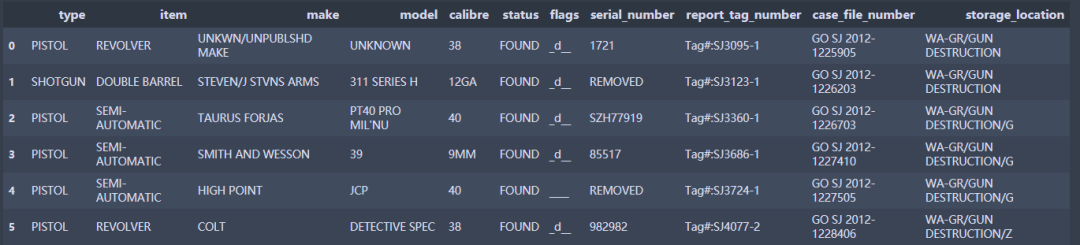
通过to_excel等方法即可实现另存。
04. 总结
本期推文简单介绍了如何使用Python第三方库pdfplumber 实现对pdf文件解析及基本信息提取。其目的是为大家提供一个数据解决思路,这里只是简单介绍表格信息和文本信息的提取,其他的方法,大家可以查看官网获取啊。