
【NLP】Google T5速读
ALBERT凳子还没坐热,GLUE就又换了老大,Google T5 (Text-to-Text Transfer Transformer)大力出奇迹,威震天在角落默不作声。
简介
这次的T5模型虽然名字和BERT+系列不一样,但底子里还是差不多的。给我的感觉就是大型Seq2Seq的BERT+干净的数据+多任务+一些改动。论文的作者深入对比了不同的预训练目标、模型结构、无监督数据集、迁移方法、NLU任务,最终拼成了T5。文章除去reference一共34页,可以说很良心地剖析了transformer的效果,建议同学们根据自己的任务和时间慢慢读。
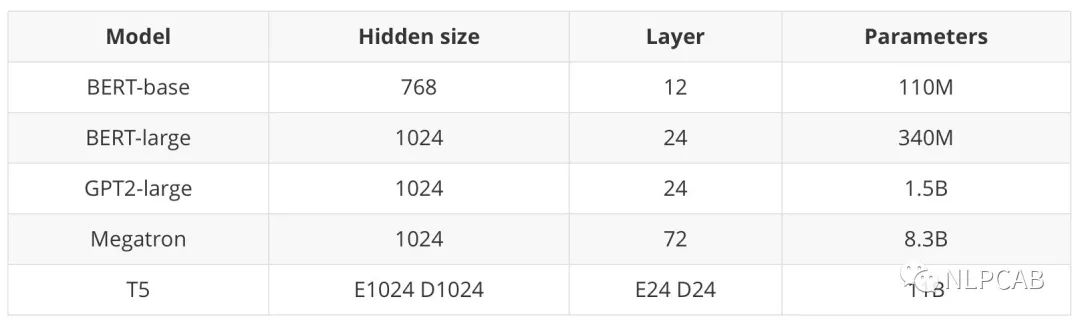
来感受一下T5的size:
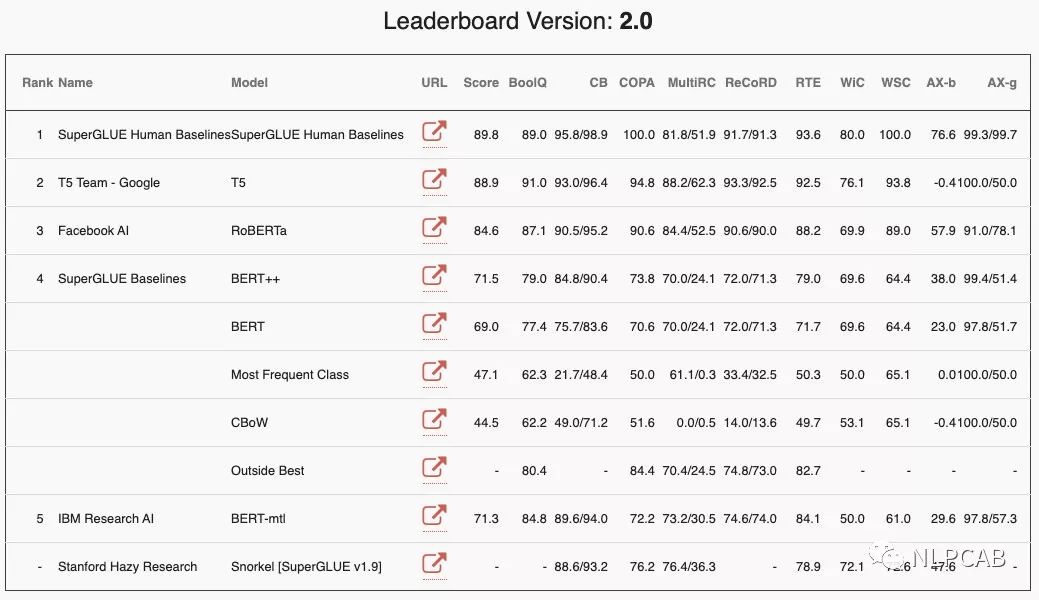
贴一下在GLUE和SUPERGLUE的登顶照:

1. 模型
输入和输出
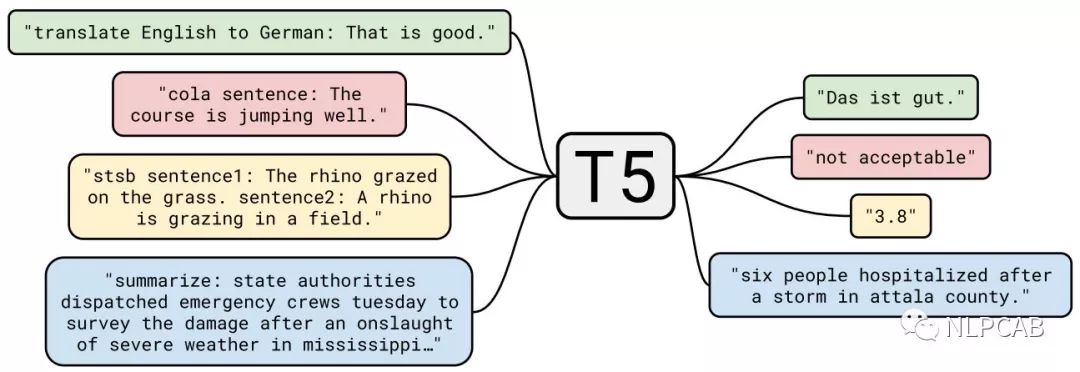
和GPT2一样,T5把所有的NLP问题归结为了“text-to-text”的任务,下图展示了T5在翻译、分类、相似度、摘要任务上的输入输出样例:
Relative position embeddings (PE)
T5使用了简化的相对位置embeding,即每个位置对应一个数值而不是向量,将(key和query)相对位置的数值加在attention softmax之前的logits上,每个head的有自己的PE,所有的层共享一套PE。个人认为这种方式更好一点,直接在计算attention weight的时候加入位置信息,而且每一层都加一次,让模型对位置更加敏感。
2. 数据
Colossal Clean Crawled Corpus (C4)
作者选取了Common Crawl数据集,这个数据集每周大约爬取20TB的WEB数据。虽然数据集已经抽取了文本,但实际上并不干净,里面还包含了很多非自然语言的东西,比如错误消息、菜单、重复文本,用过脏数据的同学一定深有体会。于是本文对数据进行了比较细致的处理:
只取结尾有标点的句子
去掉包含脏话的网页
有很多页面包含"enable Javascript"的提示,去掉包含Javascript的句子
"lorem ipsum"是一个测试网页排版的拉丁文,去掉包含这个占位符的网页
去掉包含代码片段的网页
以三句为一个片段进行去重
去掉非英文的网页
经过上述处理后最终生成了750GB的数据集C4,并且在TensorFlow Datasets开源了。
3. 任务及数据格式
任务
机器翻译、问答、生成式摘要、文本分类(单句&双句)
数据格式
输入:参考GPT2,直接把任务名称当作prefix和输入拼在一起
输出:分类任务(如推断),需要输出"entailment", "neutral", "contradiction"这三种文本,否则都算错;回归任务输出str类型的浮点数。还有其他任务,请需要的同学前往附录D参考~
4. 训练
预训练
参考SpanBERT,mask掉15%,平均长度为3的span
训练更长步数,1百万步*1024个样本
使用Multi-task预训练,即混入在无监督数据中混入一定比例的任务数据
精调
也是Multi-task,将所有GLUE/SuperGLUE的数据拼在一起变成精调一个task,减少过拟合,但同时也会牺牲一些精度
batch size减小到8
其实最后同时进行了多任务精调和单独精调,根据dev集选择最好的结果
解码
大部分使用Greedy decoding,对于输出句子较长的任务使用beam search
5. 结论
Architectures
原始的Transformer结构表现最好
encoder-decoder结构和BERT、GPT的计算量差不多
共享encoder和decoder的参数没有使效果差太多
Unsupervised objectives
自编码和自回归的效果差不多
作者推荐选择更短目标序列的目标函数,提高计算效率
Datasets
在领域内进行无监督训练可以提升一些任务的效果,但在一个小领域数据上重复训练会降低效果
Large、diverse的数据集最香了
Training strategies
精调时更新所有参数 > 更新部分参数
在多个任务上预训练之后精调 = 无监督预训练
Scaling
在小模型上训练更多数据 < 用少量步数训练更大的模型
从一个预训练模型上精调多个模型后集成 < 分开预训练+精调后集成
总体感觉T5除了position embedding之外没什么新的东西,在GLUE以及机器翻译上的提升都很有限,但作者本来的意图也是做一个全面的分析,砸百万美元替大家排忧解难,此处应有掌声。
从最近的研究来看,目前模型复杂度和性能真的是很难平衡,但今天也听到了量子计算的福音,科技永远向前,希望NLP越来越好。
往期精彩回顾
获取一折本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/y7uvZF6
本站qq群704220115。
加入微信群请扫码: