
【60期】事务隔离级别中的可重复读能防幻读吗?(MySQL面试第三弹)

阅读本文大概需要 9 分钟。
来自:cnblogs.com/CoderAyu/p/11525408.html
前言

什么是幻读?
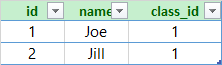
脏读
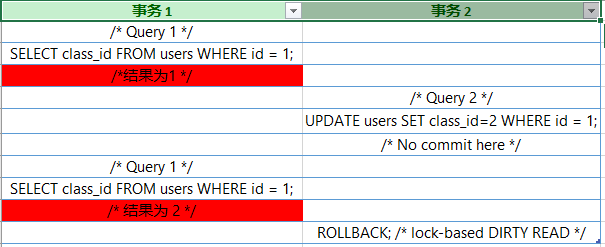
不可重复读
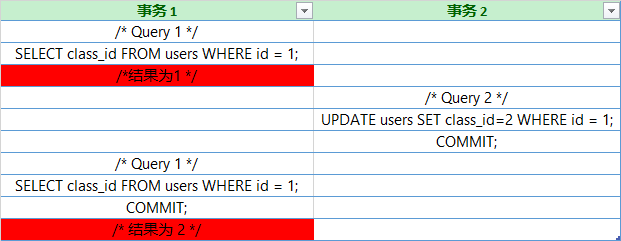
幻读
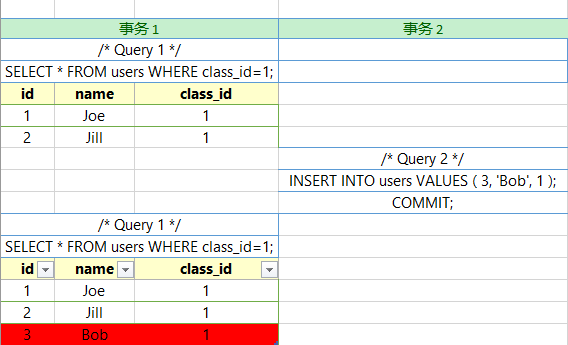
三者到底什么区别
MySQL中的四种事务隔离级别
未提交读
已提交读
SET session transaction isolation level read committed;SET SESSION binlog_format = 'ROW';(或者是MIXED)
可重复读
可串行化

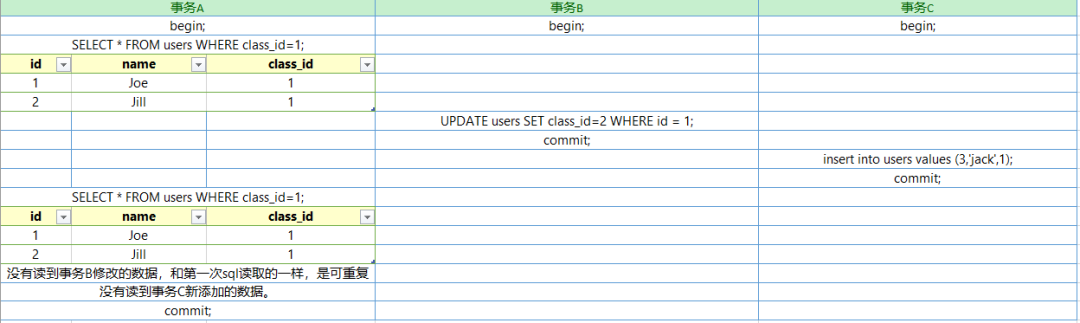
可重复读
悲观锁与乐观锁
悲观锁
乐观锁
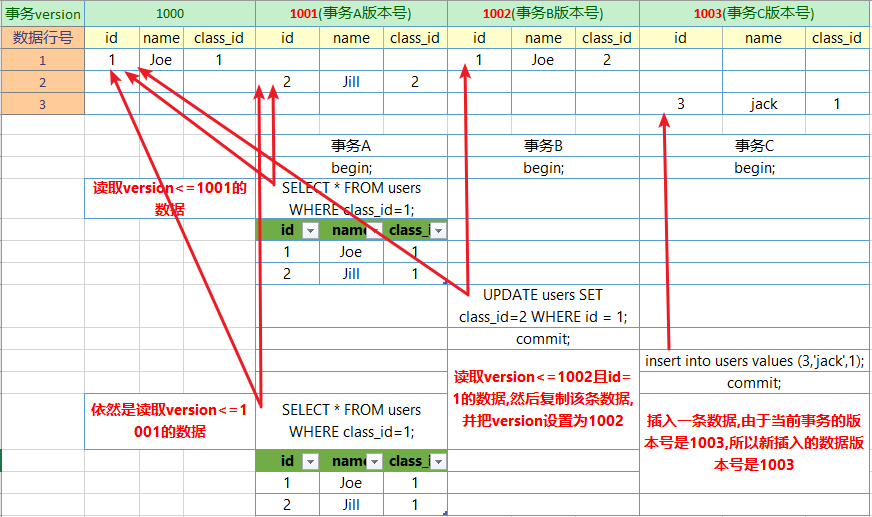
MVCC(多版本并发控制)
SELECT时,读取创建版本号<=当前事务版本号,删除版本号为空或>当前事务版本号。 INSERT时,保存当前事务版本号为行的创建版本号 DELETE时,保存当前事务版本号为行的删除版本号 UPDATE时,插入一条新纪录,保存当前事务版本号为行创建版本号,同时保存当前事务版本号到原来删除的行
快照读
select * from table ....
当前读
select * from table where ? lock in share mode;select * from table where ? for update;insert;update;delete;

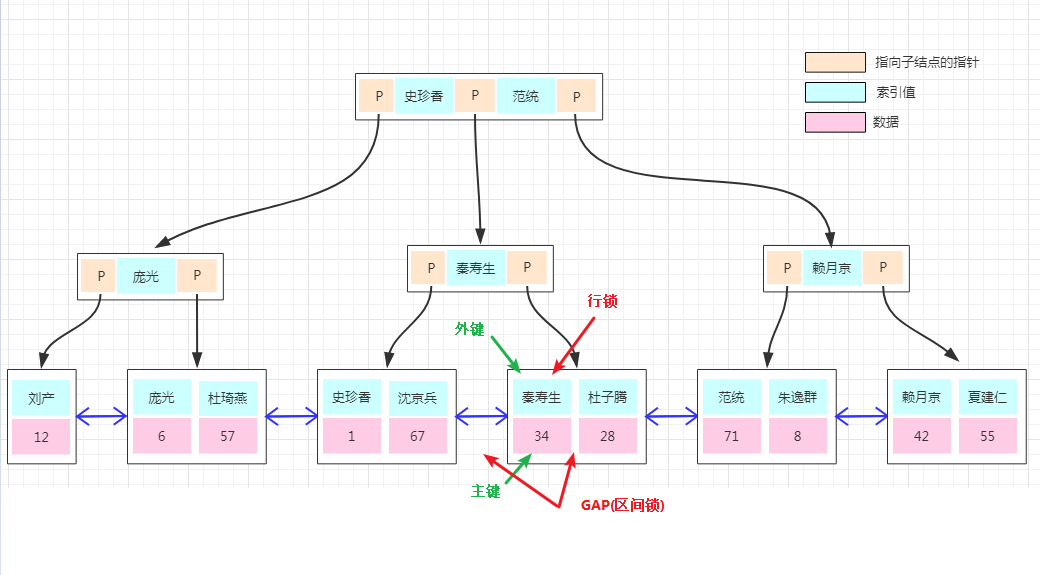
Next-Key锁
前往学习: https://www.cnblogs.com/sujing/p/11110292.html
马失前蹄

MySQL 5.6 Reference Manual
understanding InnoDB transaction isolation levels
MySQL · 源码分析 · InnoDB Repeatable Read隔离级别之大不同
不懂数据库索引的底层原理?那是因为你心里没点b树
Innodb中的事务隔离级别和锁的关系
MySQL InnoDB中的行锁 Next-Key Lock消除幻读
推荐阅读:
【59期】MySQL索引是如何提高查询效率的呢?(MySQL面试第二弹)
微信扫描二维码,关注我的公众号
朕已阅 
评论