
ECCV22 最新54篇论文分方向整理|包含Transformer、图像处理、人脸等(附下载)
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
导读
最近一周,ECCV2022陆续放出了更多和GAN,Transformers相关的论文,为了让大家及时获取和学习到计算机视觉前沿技术,极市对最新一批论文进行整理(新增54篇),包括分研究方向的论文及代码汇总。
ECCV 2022 论文分方向整理目前在极市社区持续更新中,已累计更新了108篇,项目地址:https://github.com/extreme-assistant/ECCV2022-Paper-Code-Interpretation
以下是本周更新的 ECCV 2022 论文,包含图像处理,Transformers,人脸,弱监督学习,模型训练泛化等方向。
点击 阅读原文 即可打包下载。
检测
2D目标检测
code:https://github.com/Jamie725/RGBT-detection
3D目标检测
code:https://github.com/bravegroup/dcd
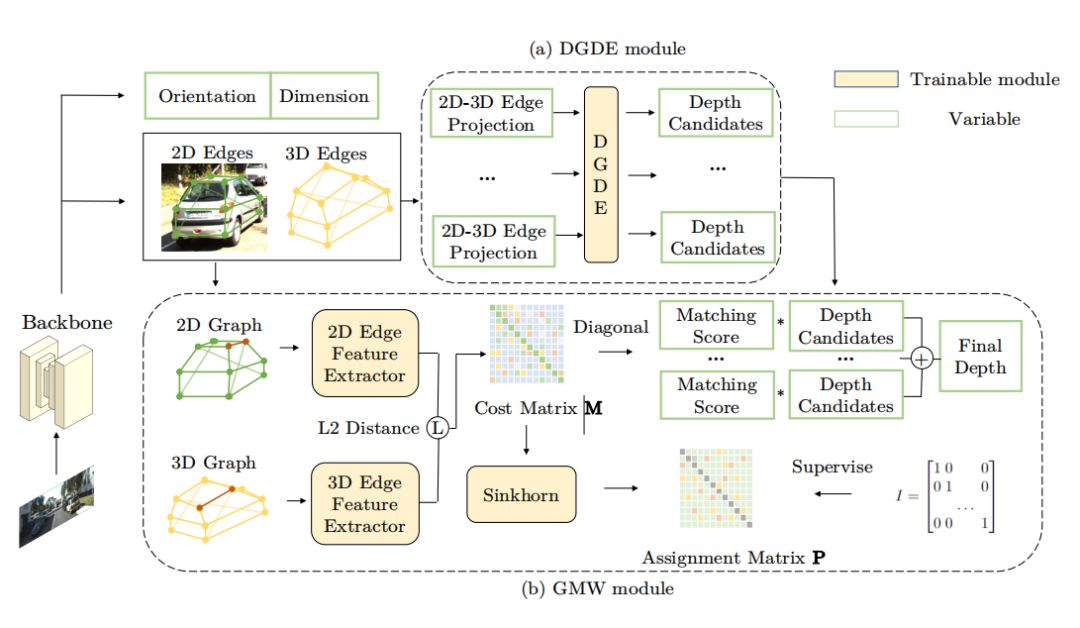
人物交互检测
code:https://github.com/zhihou7/scl; https://github.com/zhihou7/HOI-CL
分割
实例分割
code:https://github.com/wjf5203/vnext
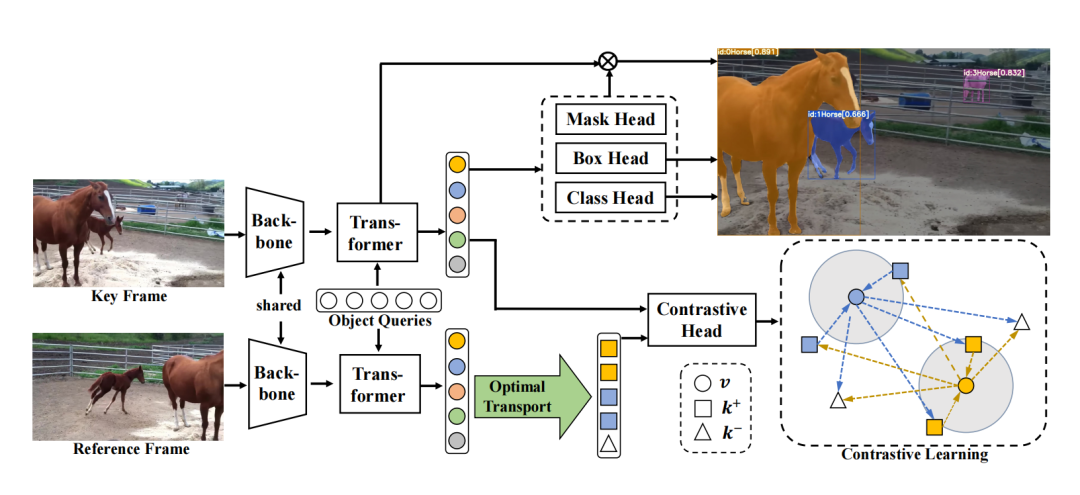
图像处理
超分辨率
code:https://github.com/zhjy2016/splut
code:https://github.com/neural-video-delivery/emt-pytorch-eccv2022
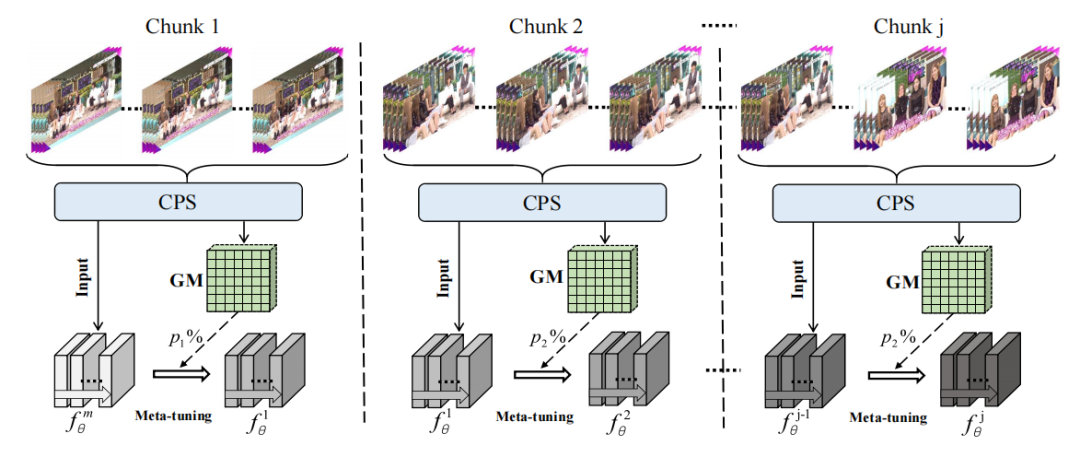
图像复原/图像增强/图像重建
code:https://github.com/jinyeying/night-enhancement
code:https://github.com/zzh-tech/dual-reversed-rs
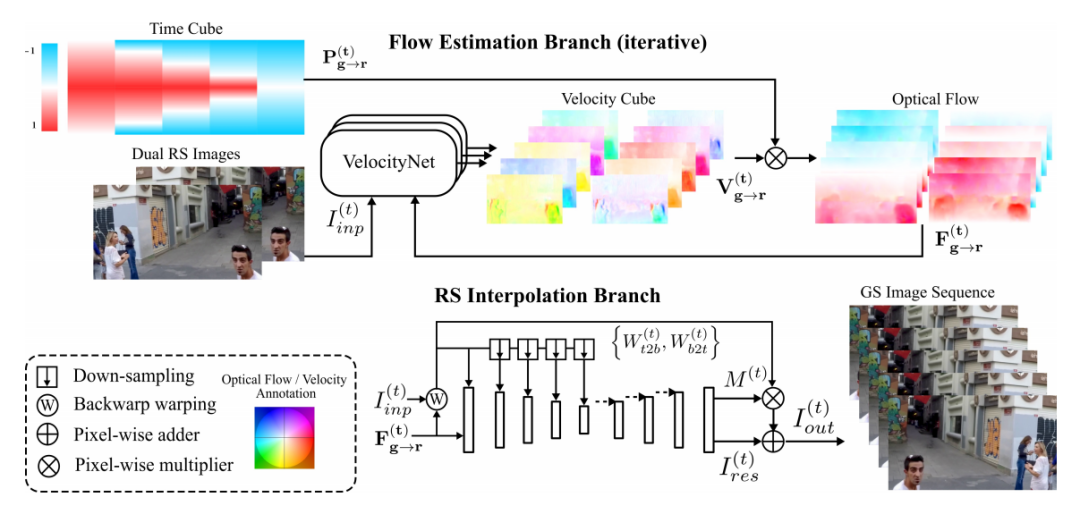
code:https://github.com/jinyeying/night-enhancement
图像去阴影/去反射
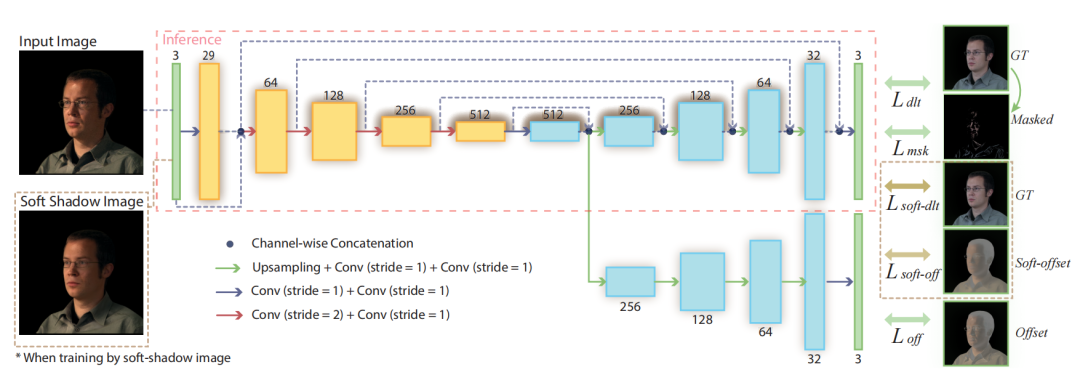
图像去噪
code:https://github.com/Owen718/Perceiving-and-Modeling-Density-is-All-You-Need-for-Image-Dehazing
code:https://github.com/zzh-tech/Animation-from-Blur
视频处理
视频修复
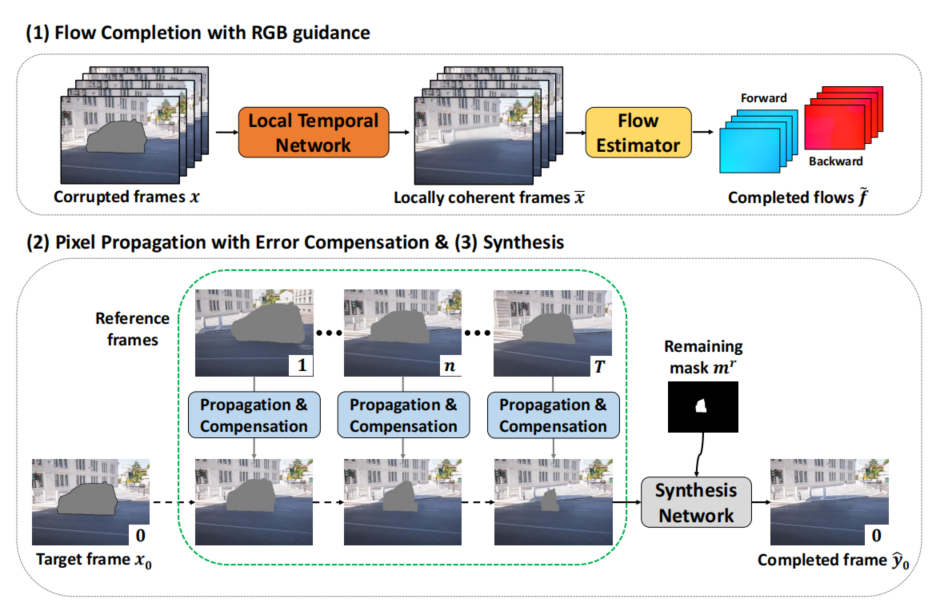
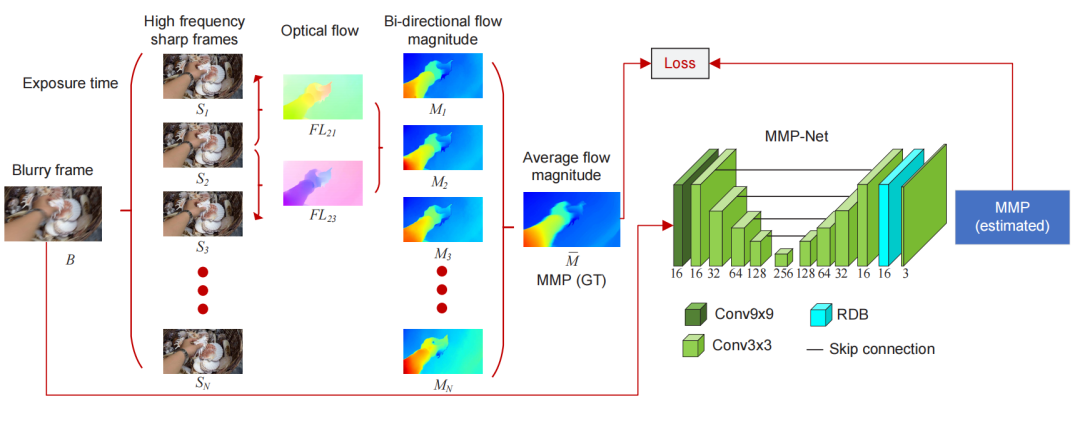
视频去模糊
code:https://github.com/sollynoay/mmp-rnn
图像&视频检索/视频理解
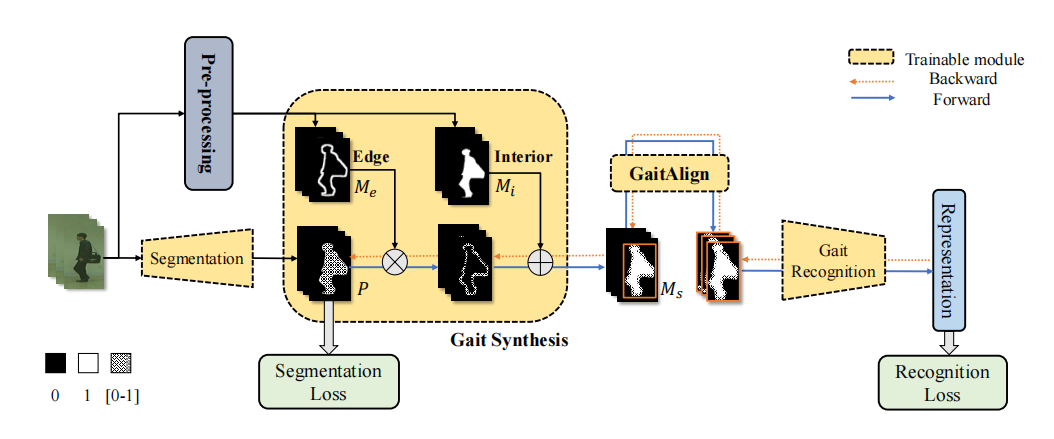
行为识别/行为识别/动作识别/检测/分割
code:https://github.com/shiqiyu/opengait
code:https://github.com/canbaoburen/CoDT
行人重识别/检测
code:https://github.com/casia-iva-lab/pass-reid
图像/视频检索
code:https://github.com/conghuihu/ucdir
code:https://github.com/mengcaopku/locvtp
估计
视觉定位/位姿估计
code:https://github.com/menghao666/hdr
code:https://github.com/164140757/scm
人脸
code:https://trust.is.tue.mpg.de/
code:https://github.com/zhuhao-nju/mofanerf
三维视觉
三维重建
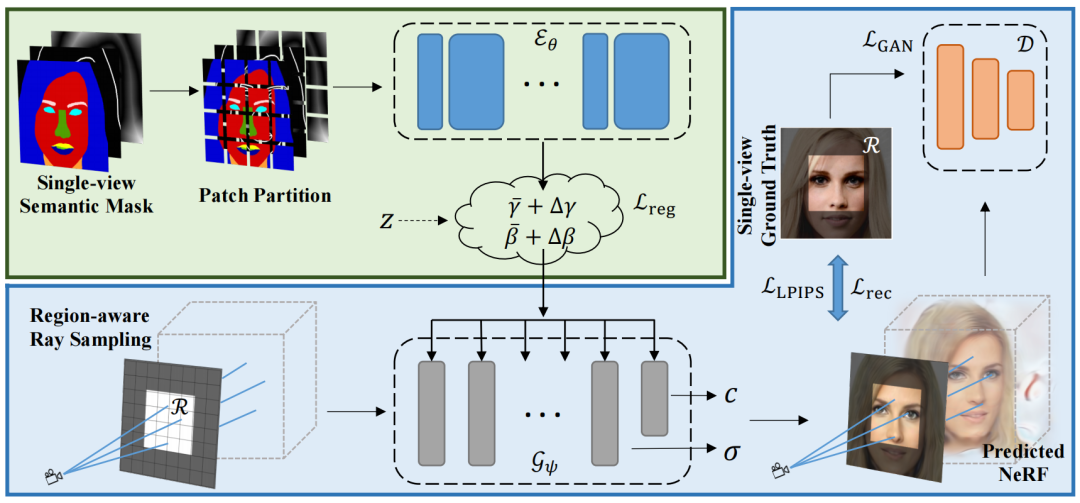
场景重建/视图合成/新视角合成
code:https://github.com/donydchen/sem2nerf
目标跟踪
文本检测/识别/理解
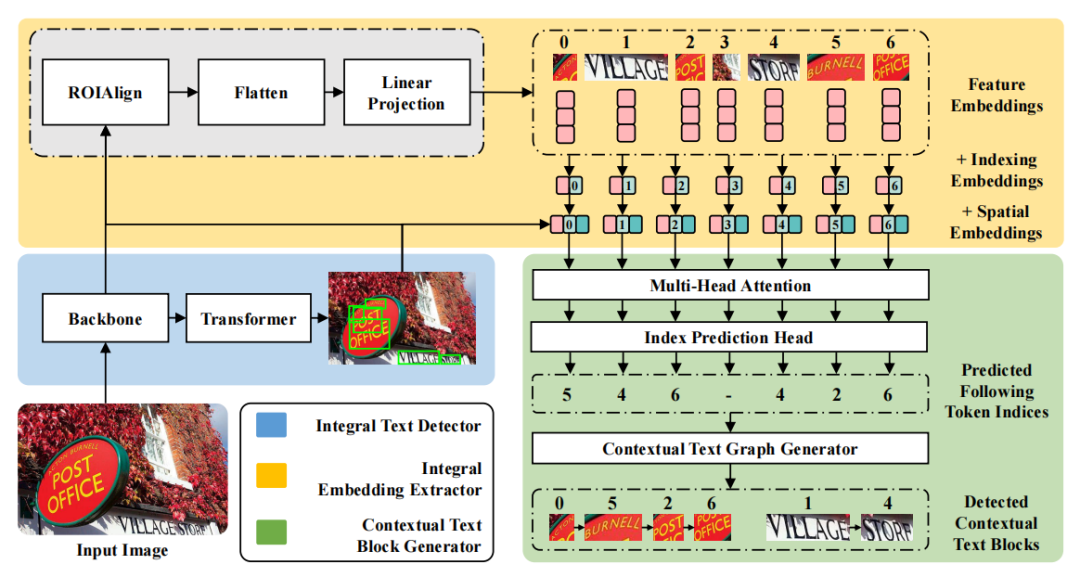
code:https://github.com/fcjian/PromptDet
code:https://github.com/weijiawu/transdetr
GAN/生成式/对抗式
code:https://github.com/xuwangyin/AT-EBMs
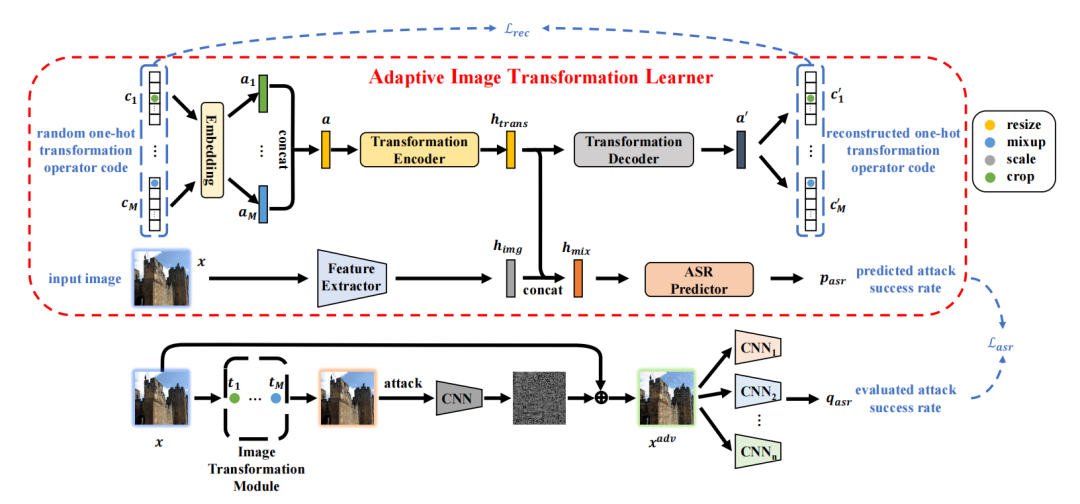
code:https://github.com/apple/ml-gmpi
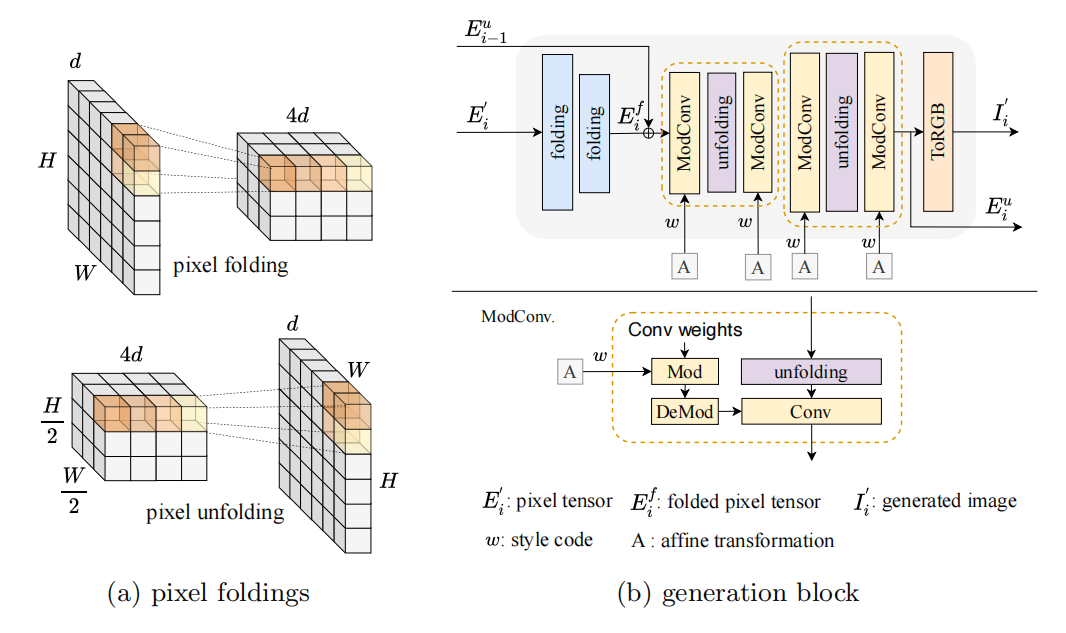
图像生成/图像合成
code:https://github.com/blinghe/pixelfolder
视觉预测
code:https://github.com/vtp-tl/d2-tpred
神经网络结构设计
DNN
code:https://github.com/jiawangbai/hpt
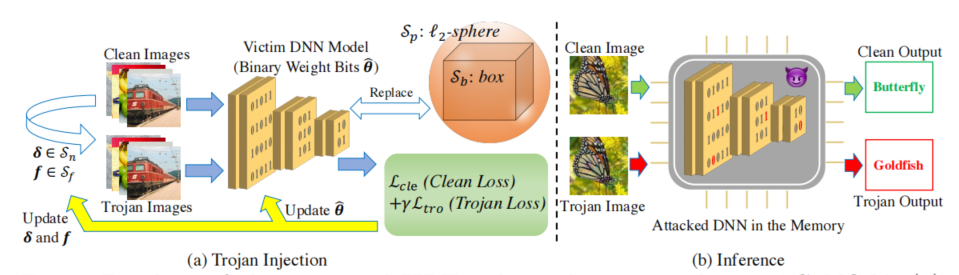
Transformer
code:https://github.com/jiawangbai/HAT
code:https://github.com/ftbabi/tie_eccv2022
code:https://github.com/yangr116/scalablevit
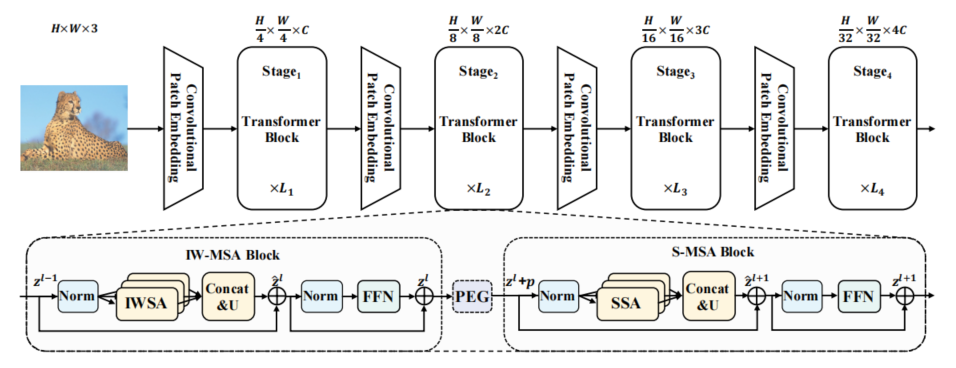
code:https://github.com/KMnP/vpt
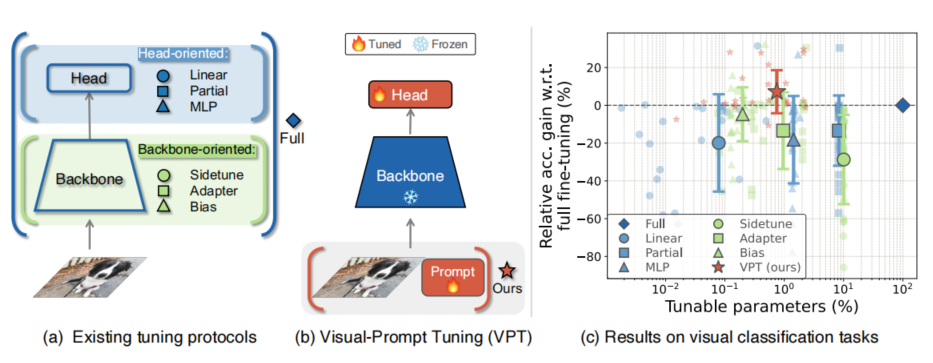
图像特征提取与匹配
视觉表征学习
code:https://github.com/qianyiwu/objsdf
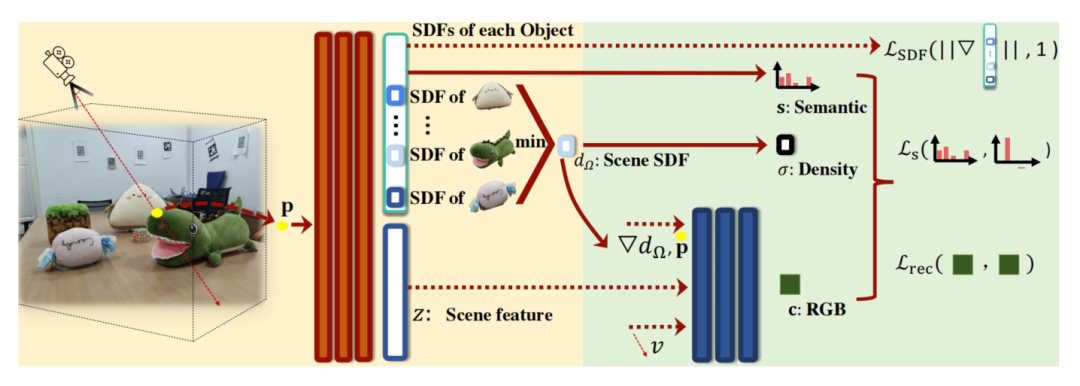
模型训练/泛化
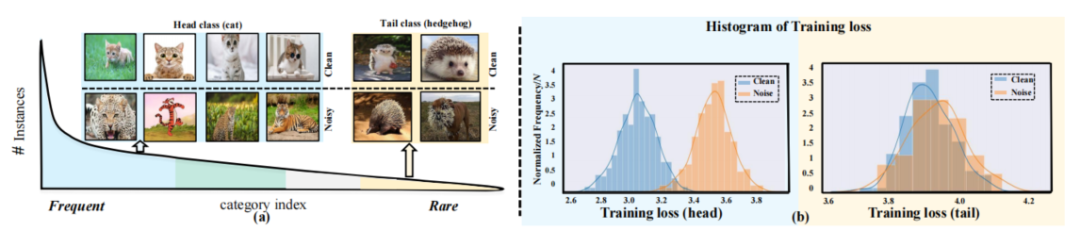
长尾分布
code:https://github.com/kostas1515/gol)
code:https://github.com/yxymessi/h2e-framework
模型压缩
知识蒸馏
code:https://github.com/ososos888/prune-then-distill
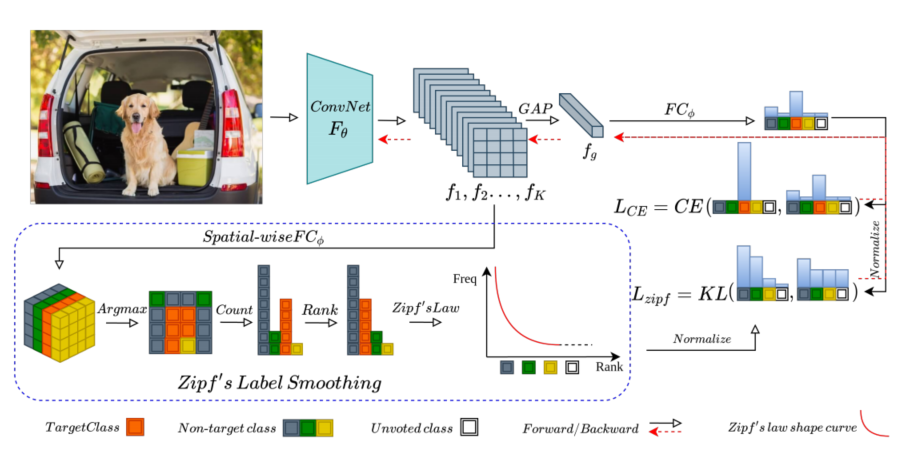
code:https://github.com/megvii-research/zipfls
半监督学习/弱监督学习/无监督学习/自监督学习
code:https://github.com/correr-zhou/spml-acktheunknown
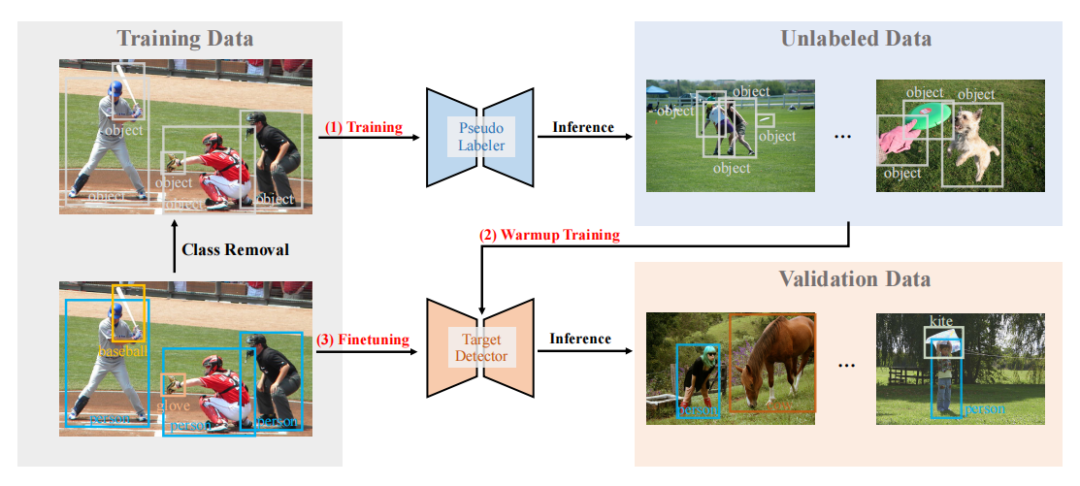
code:https://github.com/1170300714/w2n_wsod
code:https://github.com/dvlab-research/Entity
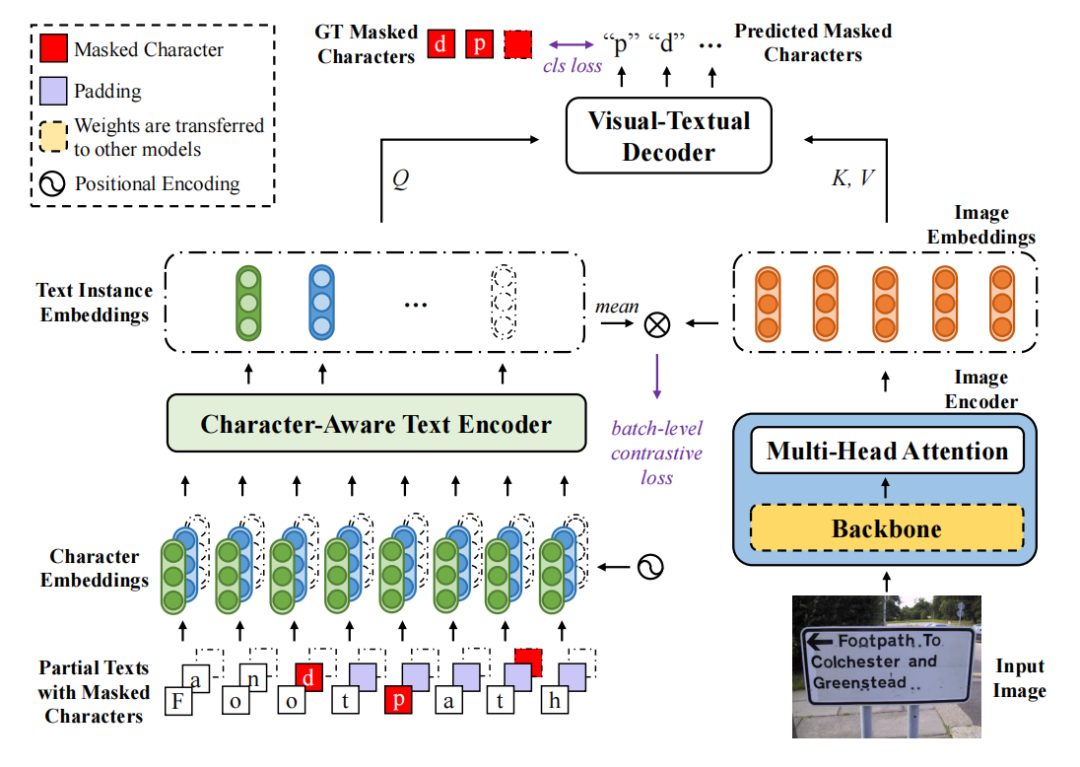
多模态学习/跨模态
视觉-语言
小样本学习/零样本学习
code:https://github.com/heekhero/ACSR
持续学习
模仿学习

点个在看 paper不断!
评论