
Kafka 存储选型的奥秘

1. Kafka 的存储难点是什么?
但是在讲解 Kafka 的存储方案之前,我们有必要去尝试分析下:为什么 Kafka 会采用 Logging(日志文件)的存储方式?它的选型依据到底是什么?
这也是本系列希望做到的,思考力胜过记忆力,多问 why,而不是死记 what。
Kafka 的存储选型逻辑,我认为跟我们开发业务需求的思路类似,到底用 MySQL、Redis 还是其他存储方案?一定取决于具体的业务场景。
1、功能性需求:存的是什么数据?量级如何?需要存多久?CRUD 的场景都有哪些?
2、非功能性需求:性能和稳定性的要求是什么样的?是否要考虑扩展性?
再回到 Kafka 来看,它的功能性需求至少包括以下几点:
1、存的数据主要是消息流:消息可以是最简单的文本字符串,也可以是自定义的复杂格式。
但是对于 Broker 来说,它只需处理好消息的投递即可,无需关注消息内容本身。
2、数据量级非常大:因为 Kafka 作为 Linkedin 的孵化项目诞生,用作实时日志流处理(运营活动中的埋点、运维监控指标等),按 Linkedin 当初的业务规模来看,每天要处理的消息量预计在千亿级规模。
3、CRUD 场景足够简单:因为消息队列最核心的功能就是数据管道,它仅提供转储能力,因此 CRUD 操作确实很简单。
首先,消息等同于通知事件,都是追加写入的,根本无需考虑 update。其次,对于 Consumer 端来说,Broker 提供按 offset(消费位移)或者 timestamp(时间戳)查询消息的能力就行。再次,长时间未消费的消息(比如 7 天前的),Broker 做好定期删除即可。
接着,我们再来看看非功能性需求:
1、性能要求:之前的文章交代过,Linkedin 最初尝试过用 ActiveMQ 来解决数据传输问题,但是性能无法满足要求,然后才决定自研 Kafka。ActiveMQ 的单机吞吐量大约是万级 TPS,Kafka 显然要比 ActiveMQ 的性能高一个量级才行。
2、稳定性要求:消息的持久化(确保机器重启后历史数据不丢失)、单台 Broker 宕机后如何快速故障转移继续对外提供服务,这两个能力也是 Kafka 必须要考虑的。
3、扩展性要求:Kafka 面对的是海量数据的存储问题,必然要考虑存储的扩展性。
1、功能性需求:其实足够简单,追加写、无需update、能根据消费位移和时间戳查询消息、能定期删除过期的消息。
2、非功能性需求:是难点所在,因为 Kafka 本身就是一个高并发系统,必然会遇到典型的高性能、高可用和高扩展这三方面的挑战。
2. Kafka 的存储选型分析
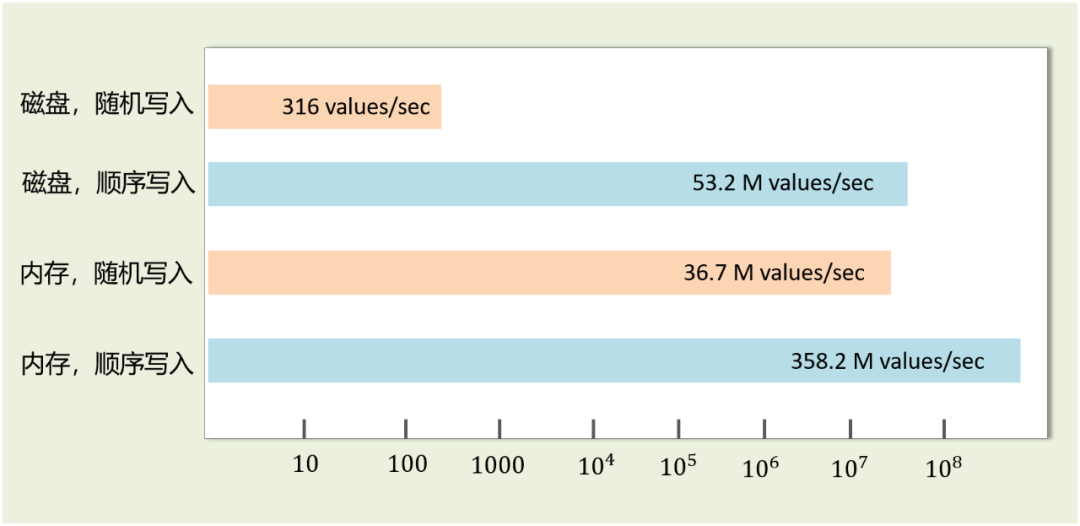
1、内存的存取速度快,但是容量小、价格昂贵,不适用于要长期保存的数据。
2、磁盘的存取速度相对较慢,但是廉价、而且可以持久化存储。
3、一次磁盘 IO 的耗时主要取决于:寻道时间和盘片旋转时间,提高磁盘 IO 性能最有效的方法就是:减少随机 IO,增加顺序 IO。
4、磁盘的 IO 速度其实不一定比内存慢,取决于我们如何使用它。
1、加快读:通过索引( B+ 树、二份查找树等方式),提高查询速度,但是写入数据时要维护索引,因此会降低写入效率。
2、加快写:纯日志型,数据以 append 追加的方式顺序写入,不加索引,使得写入速度非常高(理论上可接近磁盘的写入速度),但是缺乏索引支持,因此查询性能低。
1、哈希索引:通过哈希函数将 key 映射成数据的存储地址,适用于等值查询等简单场景,对于比较查询、范围查询等复杂场景无能为力。
2、B/B+ Tree 索引:最常见的索引类型,重点考虑的是读性能,它是很多传统关系型数据库,比如 MySQL、Oracle 的底层结构。
3、 LSM Tree 索引:数据以 Append 方式追加写入日志文件,优化了写但是又没显著降低读性能,众多 NoSQL 存储系统比如 BigTable,HBase,Cassandra,RocksDB 的底层结构。
2.2 Kafka 的存储选型考虑
1、写入操作:并发非常高,百万级 TPS,但都是顺序写入,无需考虑更新
2、查询操作:需求简单,能按照 offset 或者 timestamp 查询消息即可

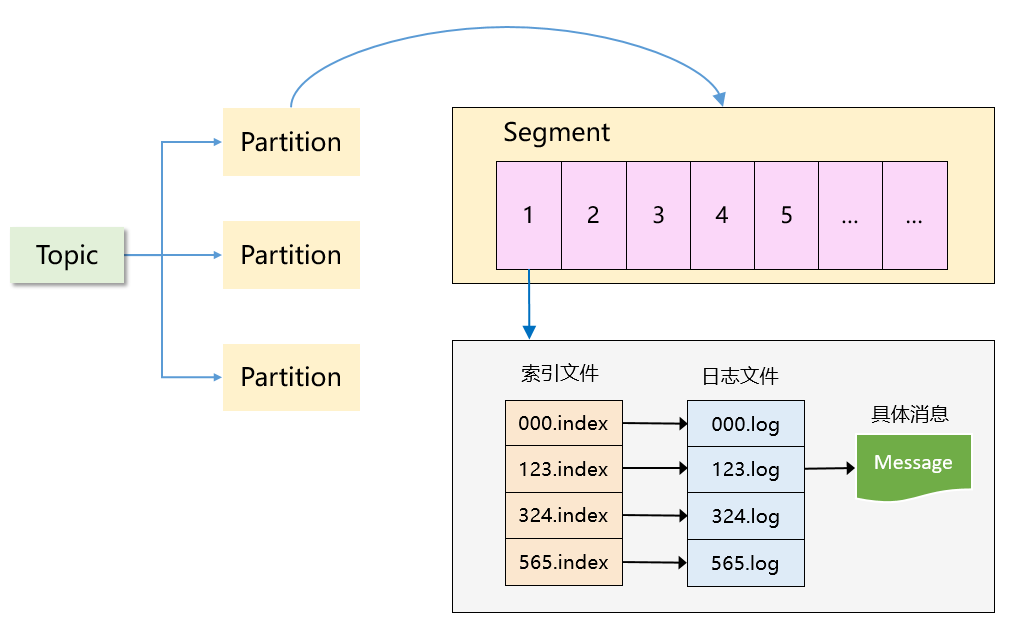
图3:Kafka 的稀疏索引示意图
最终我们发现:Append 追加写日志 + 稀疏的哈希索引,形成了 Kafka 最终的存储方案。而这不就是 LSM Tree 的设计思想吗?

https://www.infoq.com/presentations/lsm-append-data-structures/
3. Kafka 的存储设计
4. 写在最后
1. 推荐一个完善的停车管理系统,物联网项目springboot,有源码
2. 图文并茂的聊聊ReentrantReadWriteLock的位运算
3. 上班摸鱼,我是认真的
最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
获取方式:点“在看”,关注公众号并回复 Java 领取,更多内容陆续奉上。
文章有帮助的话,在看,转发吧。
谢谢支持哟 (*^__^*)
