
架构师之路,从「存储选型」起步

经常有人问,架构师的学习路线是什么?
我一般推荐架构师的基本功,是从「存储选型」开始的。

本文整理了存储选型的思路和整体框架,主要包括几个部分内容:
了解目前的存储技术趋势,以及对开发人员新的要求
存储选型的原则,避免日常的经典误区
结合典型数据库特点,说明如何进行存储选型,提高业务开发效率
常见的场景和解决方案
1、存储技术发展看存储选型
1.1 存储类型多元化
DB-Engines数据库排名并不代表数据库的安装数量,或者使用量。但某数据库越来越受欢迎则代表在一定时间范围内更加广泛的使用。
这里贴了一张2022年5月份的排行榜(https://db-engines.com/en/ranking)。
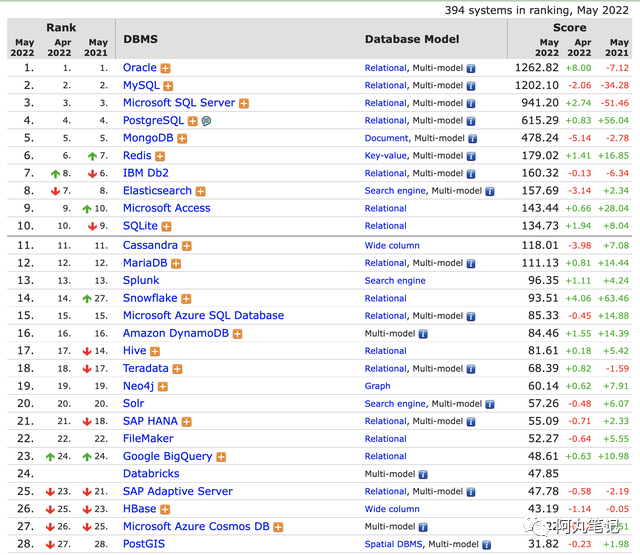
我们对于排名前10的数据库中,比较熟悉的应该是MySQL、Redis和ES,这三个数据库在我们日常开发中占据绝大多数的比例。
但是,这三个数据库只代表了一小部分的数据库类型,我们是不是可以把视野打开更多一些,看看没有更多的数据库类型,可以适合我们不同的业务,包括
Relational、Document、Key-value、Search engine、Wide column、Time Series、Graph等等不同数据库类型。
1.2 云原生存储多元化
除去上面的传统数据库之外,云时代存储技术又有了更多的变化。
除了简单的把上面的数据库托管到云上之外,还多了许多充分利用云的基础设施产生的云原生数据库,比如aws的Amazon Aurora、阿里云的PolarDB、腾讯云的TDSQL等。
另外,云时代还产生了更多类型的数据库,比如阿里云的多模数据库Lindorm、Pingcap的HTAP数据库TiDb等。
多类型数据库是各个云厂商发展的趋势,他们为什么会支持越来越多用途的数据库呢?
供给侧的改变一定是来源于需求侧,因为随着互联网、物联网等场景发展,有很多业务需求不是任何单一的数据库能解决的了。
1.3 告诉我们什么?
「数据库类型多元化」 & 「云原生数据库类型多元化」 是一个必然的发展趋势。
我们要解决的场景会越来越多,我们需要掌握的数据库领域也越来越广,只有这样,我们才能面对在线事务、离线分析、海量存储、成本与效率等因素,真正做好存储选型。
2、存储选型原则:不要耍流氓
2.1 不讲场景的选型都是耍流氓
大家可能都知道,数据库的选型一定是基于实际的业务场景的。但是,可能也遇到过类似的对话:
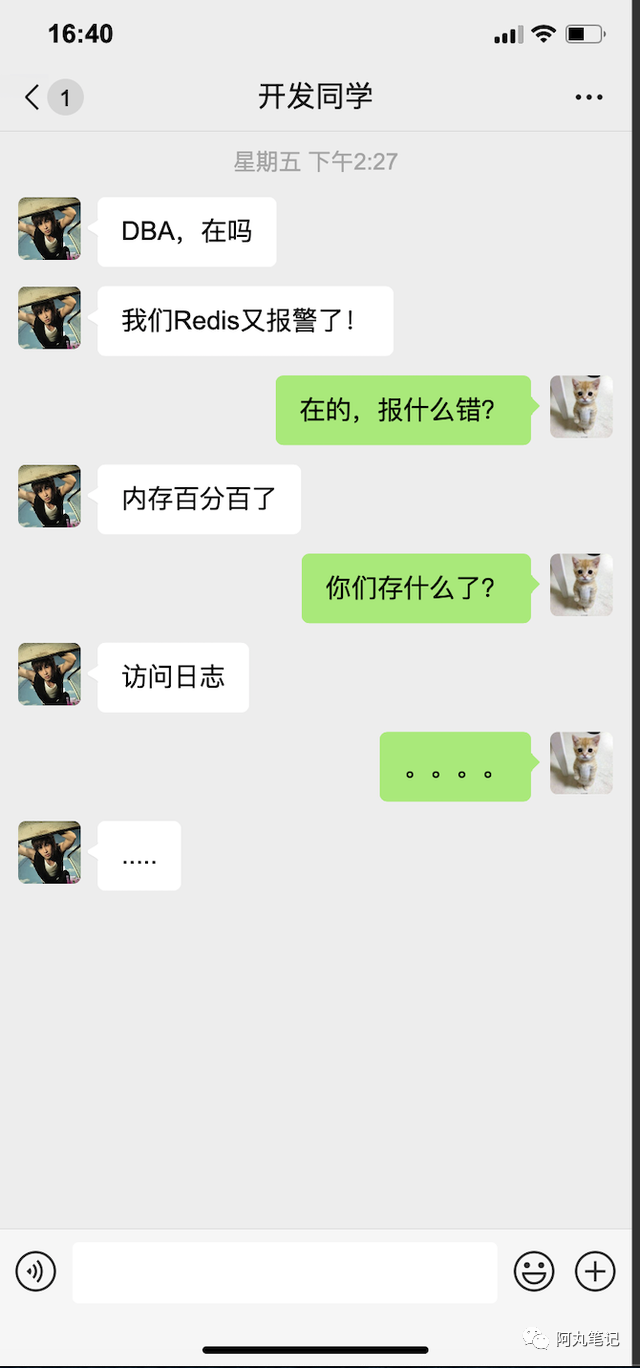
上面的对话可能有些夸张,但是实际生产中,可能是对场景的理解有误,也可能是为了快速完成任务开发,结果是在「特定场景」选择了错误的数据库的情况时有发生。
常见的特定场景包括:
离线业务:日志、搜索、统计等。
事务需求:强事务型、分析型。
数据热度:全热数据、冷热明显等。
数据读写偏好:多读、多写。
数据增长方式:按日期、按用户、按位置类型等。
对于存储选型来说,一定需要识别特定场景的特点,是在线业务还是离线业务?数据冷热是否明显?数据访问方式特点?数据增长方式等等。
如果没有根据场景特点来做存储选型,可能会带来不良后果,包括无法满足业务需求、存储成本暴涨等,然后就需要花大代价做不停机数据迁移和代码重构。
因此,针对特定业务场景的存储选型一定要仔细、慎重,并在一开始就设计好。
2.2 不讲数据规模的选型都是耍流氓
除了特定场景外,「数据规模」是存储选型的另一个核心要素。
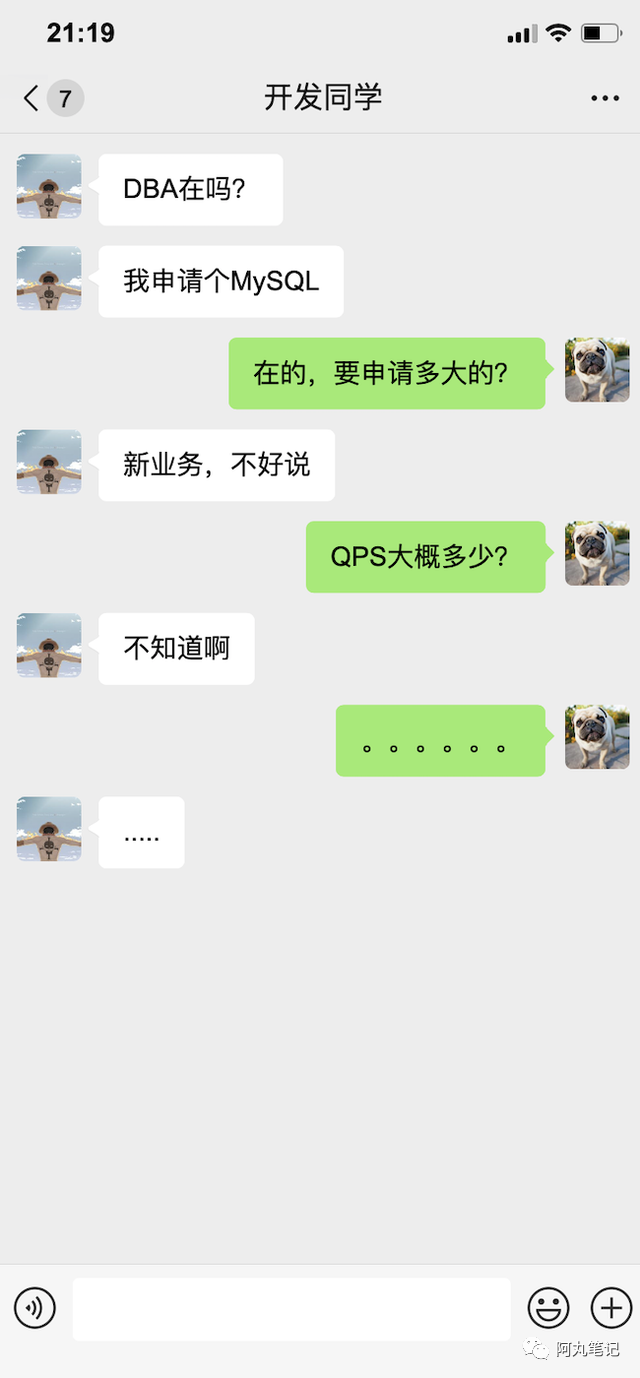
这样的对话非常常见。
虽然在一些新业务场景下,确实很难准确评估业务的数据规模,但是无法评估的数据规模,往往意味着无法做好正确的存储选型。
因此,如果有一定的先验知识,我们需要尽量做好数据规模的评估。比如,之前有没有类似的业务、其他组有没有类似的需求或功能,它们目前的数据规模大致如何,然后进行评估。
常见的数据规模指标有三个:
数据总量
QPS
rt
不同的数据规模指标,往往意味着不同的存储选型。
2.3 不讲掌控度的选型都是耍流氓
对于存储选型,「掌控度」是非常重要的选型原则。
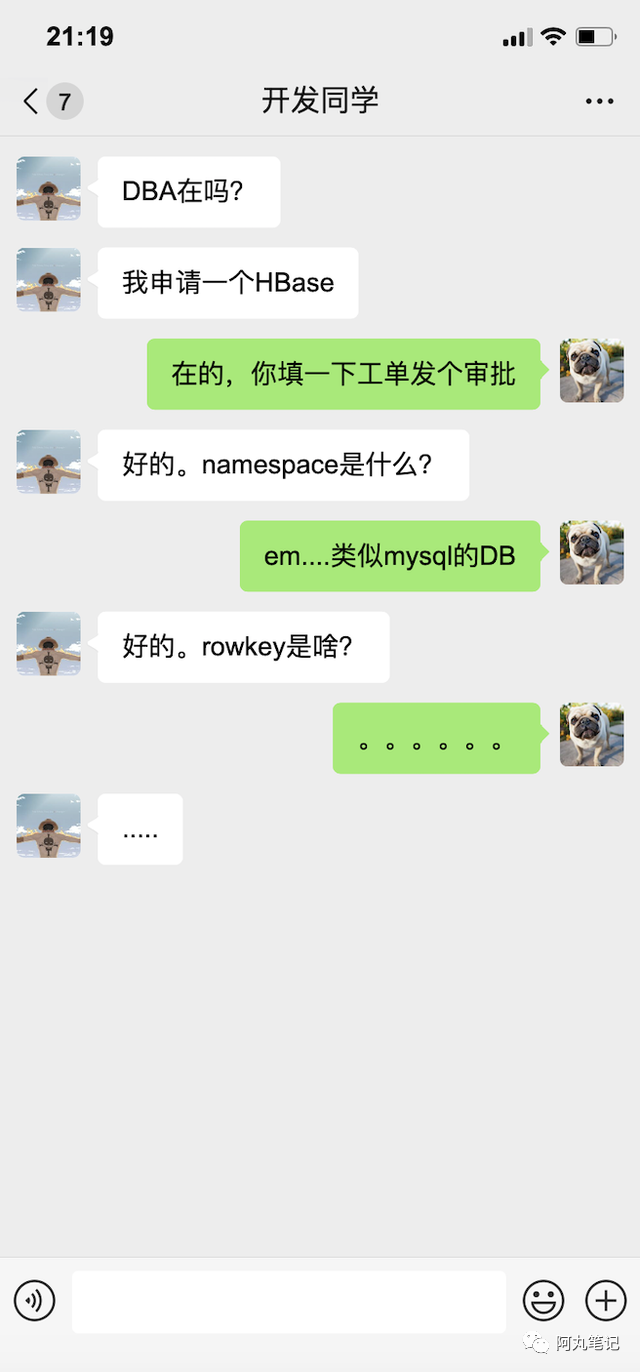
这里其实包括了两个维度,开发同学对存储的掌控度 & DBA对存储的掌控度。
1)开发同学的掌控度
对开发同学来说,选择一个存储,一定是基于对该存储的基本认知&最佳实践的了解。
一定不是其他人也这么用所以我这么用。
如果盲目使用一个自己不了解的存储,很容易带来不良后果,轻则造成资源浪费,重则引起线上故障(比如Mysql的慢sql、HBase的热点访问等)。
2)DBA对存储的掌控度
对DBA来说,对一个存储的基本认知&最佳实践是基础要求了。在此之上,还有其他更多的要求。
一个是社区活跃度。社区活跃度决定着你获取信息的难易程度,也决定到出现了故障后的定位速度甚至是能不能定位出来,如果社区很活跃,自然就能得到更多的帮助。
第二个是有没有案例背书。最好是一些中厂、大厂最新的案例实践(千万不要被大厂多年前的案例迷惑,技术发展往往意味着更新更合适的解决方案)。如果案例与存储不匹配,或者没有什么案例来支持你的存储选型,那么这个选型可能就是不合适的。
第三个是存储组件的上手成本。团队具备了什么样的技术储备?选择的是自研还是云产品?云产品是全托管的还是半托管的?毕竟每一种数据库都不是这么简单,如果人力有限而上手难度又很大,那么这个存储组件目前可能不是一个好的选择。
3、选型路线图
结合上面的原则,我们来做一个存储选型路线图供大家参考。
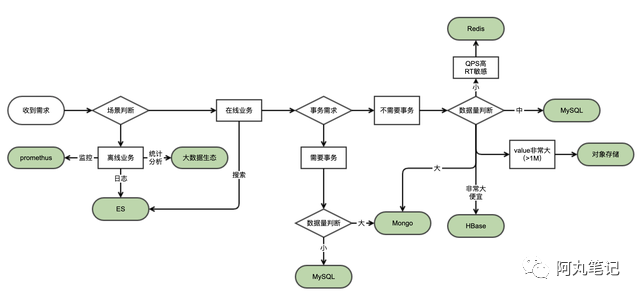
进一步,针对各个类型数据库,我们都需要了解它们的优点、缺点、最佳实践等,来结合业务场景因地制宜。
3.1 Relational
以MySQL为代表的关系型数据库。常用于在线业务(OLTP)场景,对于强事务有较好支持。
优点:
容易理解,大家基本上都用得比较熟
事务特性
配套成熟(备份恢复、数据订阅、数据同步等)
服务极度稳定
缺点:
不易水平扩展
大表表结构变更复杂
全文检索能力弱
复杂分析、统计能力弱
最佳实践:
索引设计
避免n+1轮训
避免深分页
单表千万考虑分库分表,或者使用云数据库(polarDB或者TDSQL)
冷热数据注意归档
不直接处理统计、分析型操作
3.2 Key-value
KV型NoSql顾名思义就是以键值对形式存储的非关系型数据库,是最简单、最容易理解也是大家最熟悉的一种 NoSql。
Redis是其中的代表,典型用于缓存场景。
优点:
数据基于内存,读写效率高
KV型数据,时间复杂度为O(1),查询速度快
缺点:
查询方式单一
内存有限,且非常昂贵
由于存储是基于内存的,会有丢失数据的风险(有持久化存储方案)
最佳实践:
合理控制kv大小,避免大key
避免热点key
设置合理的TTL
注意缓存雪崩、穿透、击穿、兼容问题
不要用于消息队列,异常情况无法堆积消息
不要将redis作为数据库使用,可能会丢数据
3.3 Search engine
搜索型NoSql顾名思义主要是用在搜索场景下的。
尽管MySQL可以通过索引来加速查询,但是对于全文搜索、模糊搜索等场景就比较无力,搜索型NoSql正是为了补足这个场景诞生的。
ElasticSearch是其中的代表产品。
优点:
支持分词场景、全文搜索,这是区别于关系型数据库最大特点
支持条件查询,支持聚合操作,适合数据分析
在集群环境下可以方便横向扩展,可承载PB级别的数据
缺点:
读写之间有延迟,写入的数据不一定能马上读到
硬件性能要求高
最佳实践:
核心在线应用强依赖ES需要考虑可行的降级方案
禁止使用单索引多type
ES成本较高,因此建议仅数据库加速、全文检索情况下使用es
ES中仅存储索引字段,通过id回查数据库,不要全量数据存储ES
根据节点数量设置合理的分片数量、分片大小
3.4 Document
文档型 NoSql 指的是将半结构化数据存储为文档的一种 NoSql,通常以 JSON 或者 XML 格式存储数据。
Mongo是其中的代表产品。
优点:
没有预定义的字段,扩展字段容易
相较于关系型数据库,读写性能优越
分片集群易水平扩展
缺点:
文档结构过于灵活,可能导致不易维护
客户端控制力强,对开发、优化上有一定要求
最佳实践:
选择合理的片键
建立合适的索引
正确使用写关注设置(Write Concern)
正确使用读选项设置(Read Preference)
正确使用更新语句(局部更新、防止大量更新集中在一条数据内)
3.5 Wide column
一般用于可靠性要求不高的海量存储场景。
HBase是代表产品(国外cassandra用得多,国内HBase用得多)。
优点:
动态列调整,不受表结构困扰
海量数据存储,PB 级别数据
横向扩展方便,且支持廉价存储扩展,成本低,适用于无法预估存储量的海量数据
缺点:
Hadoop生态产品,组件依赖多,没有云托管产品,运维能力要求比较高
Rowkey设计需要一定经验,避免热点
单集群SLA一般3个9,如果用于在线核心业务,一定需要考虑降级和容灾
只支持行级事务
最佳实践:
适用于行数多,但单个kv数据量小(1M以下)
特别注意Rowkey设计,避免热点
大value(10M以上)禁止存入HBase,考虑对象存储
表创建时必须预分区
表的列族数量不得超过 2 个
HBase是CP型系统,SLA一般是3个9,一般建议离线业务使用。如果核心在线业务使用,必须做好降级、容灾
4、常见场景和选型方案
上文提出了 三条选型原则 和 常见数据库的选型依据,下面结合不同场景做一下常规选型方案参考。
4.1 主要场景和方案
毋庸置疑,互联网业务的主要场景,是采用mysql进行数据存储。正如MySQL的自己所说 —— most popular open source database。

当然,为了扛住高并发场景,缓存也不可缺失。
因此,最主要的方案就是 MySQL + Redis。
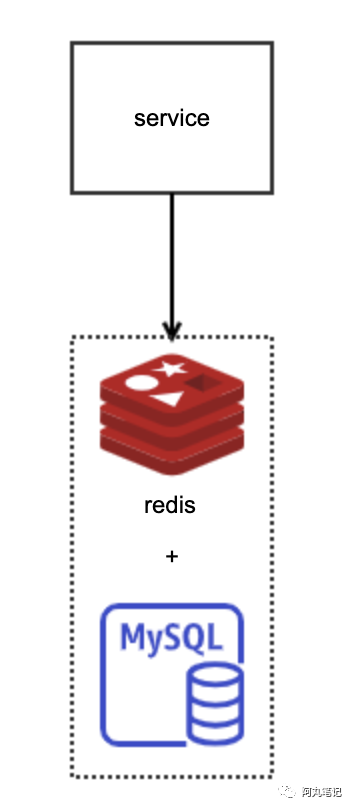
适用于日常主要场景:
MySQL满足事务性要求
Redis抗热点
4.2 模糊搜索 or 全文检索
MySQL数据库擅长在线业务(OLTP)读写,不擅长做统计、分析型业务(OLAP)。因此,一般会通过MySQL做持久化存储,ES构建索引进行查询、分析。
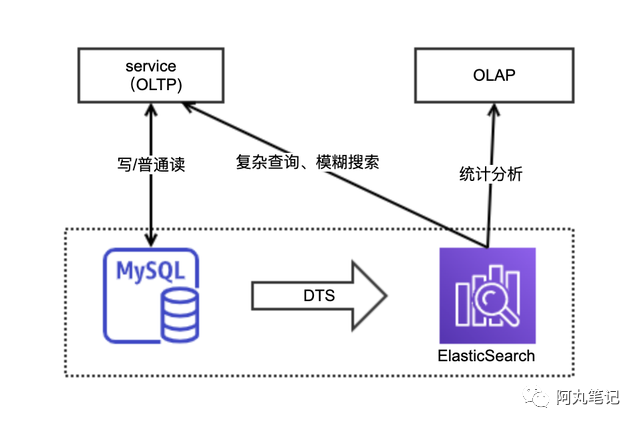
适用于搜索场景:
复杂查询
模糊搜索
全文搜索
统计分析
4.3 大量数据场景
数据规模:100TB以内的数据量。
1)MySQL分库分表 + es
传统MySQL横向扩展方案,利用分库分表中间件进行存储扩展,利用ES进行非分表键查询和复杂查询。
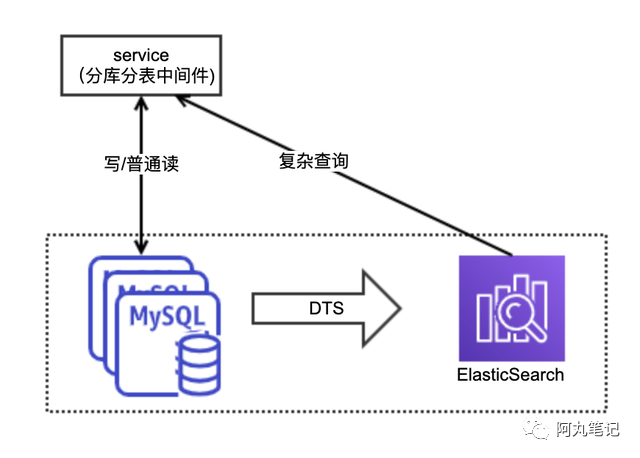
适用场景:
数据量较大
有中间件使用能力
已有MySQL横向扩展
2)云原生数据库(以polarDB为例)
云时代的新方案。
PolarDB是阿里巴巴自研的新一代云原生关系型数据库,在存储计算分离架构下,利用了软硬件结合的优势,为用户提供具备极致弹性、高性能、海量存储、安全可靠的数据库服务,100%兼容MySQL 5.6/5.7/8.0。
最高100 TB,不再需要因为单机容量的天花板而去购买多个实例做分片,由此简化应用开发,降低运维负担。
适用场景:
数据量较大
有公有云使用基础设施
3)mongo分片集群
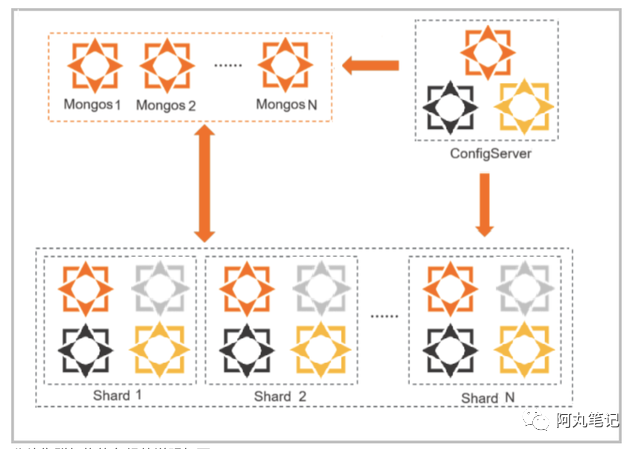
适用场景:
数据量较大的NoSQL场景
表结构变更频繁场景,free-schema
对mongo使用有一定理解
4.4 海量数据场景
数据规模:100TB以上的数据量。
1)高可用数据库 + HBase
由于数据量非常大,需要考虑存储成本。因此一般会考虑冷热数据分离。
热数据在高可用数据库进行读写,可以选择MySQL、Mongo等。冷数据存入成本较低的HBase或者对象存储等组件。
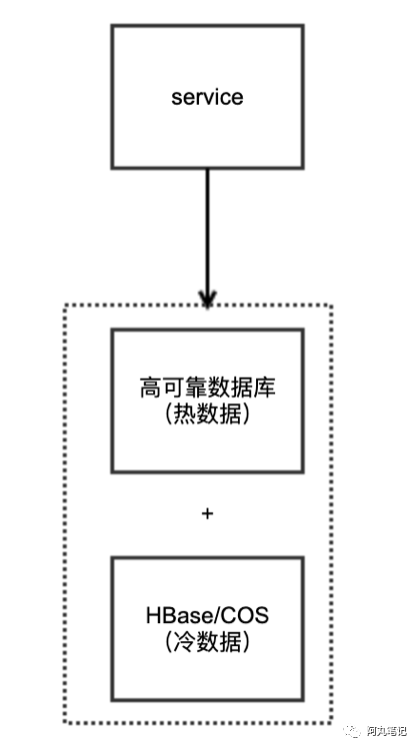
适用场景:
海量数据
可靠性要求高
2)直接使用HBase
如果是非核心在线业务,或者离线业务,可以考虑直接使用HBase。
适用场景:
海量数据
低成本
可靠性要求不高
5、总结
在业务开发过程中,除了常用的MySQL,一定要多关注市面上更合适的存储方案,这是架构师的基本功。
通过了解更多存储组件的基本特性和使用场景,因地制宜选择合适存储,提高业务开发效率,降低使用成本。
希望本文能够抛砖引玉,提供一些启发和思考。
往期热门笔记合集推荐:
原创:阿丸笔记(微信公众号:aone_note),欢迎 分享,转载请保留出处。
没有留言功能的悲伤,扫描下方二维码「加我」聊些有的没的吧~