
漫画讲解Kafka高效的存储设计|面试



在开始讲解之前,先带着大家回忆一下kafka一些名词概念:
a. Broker:提供数据存储和数据读写服务实例,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群。
b. Topic:代表的是一类消息,例如应用日志的topic,应用健康监控指标的topic等。
c. Partition:topic物理上的分组,一个topic可以分为多个partition。
d. Segment:partition物理上由多个segment组成,每个segment是一个文件。
e. offset:每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中。partition中的每个消息都有一个连续的序列号叫做offset,用于partition唯一标识一条消息.

下面是两个topic,页面浏览流量日志的topic page_view,和点击日志 click_log,在kafka数据目录下的分区存储情况:
|--page_view-0|--page_view-1|--page_view-2|--page_view-3|--click_log-0|--click_log-1|--click_log-2|--click_log-3

下图说明了文件的存储方式:
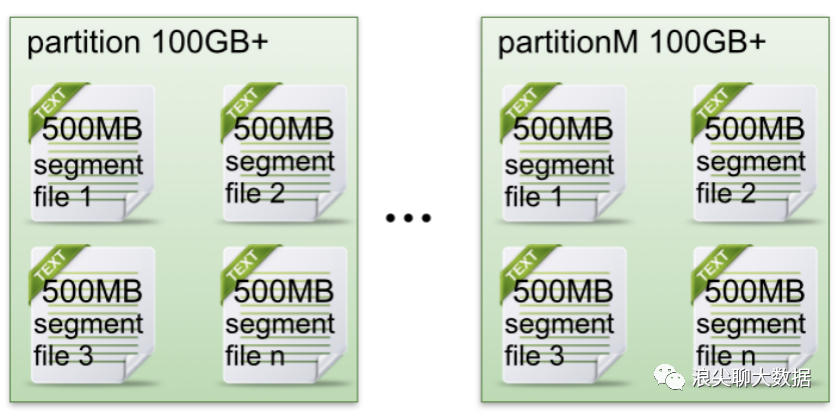
每个partion(目录)相当于一个巨型文件被平均分配到多个大小相等segment(段)数据文件中。但每个段segment file消息数量不一定相等,这种特性方便old segment file快速被删除。
每个partiton只需要支持顺序读写就行了,segment文件生命周期由服务端配置参数决定。
这样做的好处就是能快速删除无用文件,有效提高磁盘利用率。

partition中segment file组成和物理结构,细节如下:
segment file组成:由2大部分组成,分别为index文件和data文件,这两个文件一一对应,成对出现,后缀”.index”和“.log”分别表示为segment索引文件、数据文件.
segment文件命名规则:partion全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值。数值最大为64位long大小,19位数字字符长度,没有数字用0填充。
创建一个topicXXX包含1 partition,设置每个segment大小为500MB,并启动producer向Kafka broker写入大量数据,该partition文件内容如下:

图1

还有一张细节的图,说明一些index文件和log文件的对应关系:
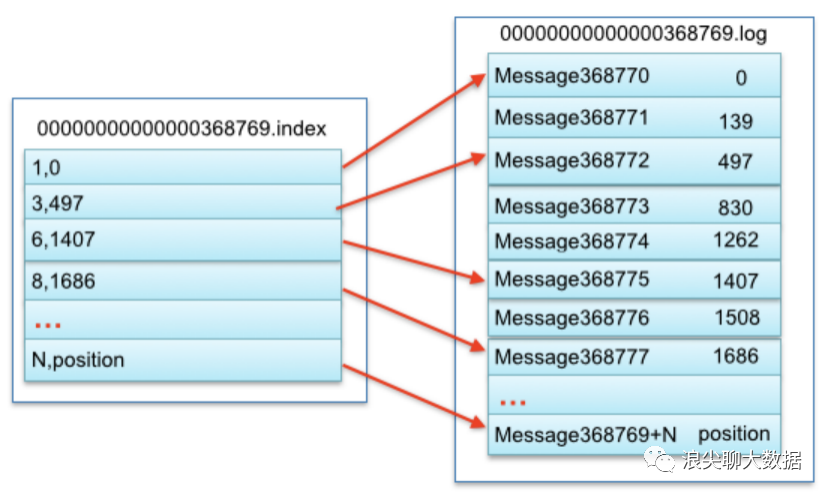
图2
索引文件存储大量元数据,数据文件存储大量消息,索引文件中元数据指向对应数据文件中message的物理偏移地址。其中以索引文件中元数据3,497为例,依次在数据文件中表示第3个message(在全局partiton表示第368772个message)、以及该消息的物理偏移地址为497。

例如读取offset=368776的message,需要通过下面2个步骤查找。
第一步查找segment file 以前面图1为例,其中00000000000000000000.index表示最开始的文件,起始偏移量(offset)为0.第二个文件00000000000000368769.index的消息量起始偏移量为368770 = 368769 + 1.同样,第三个文件00000000000000737337.index的起始偏移量为737338=737337 + 1,其他后续文件依次类推,以起始偏移量命名并排序这些文件,只要根据offset **二分查找**文件列表,就可以快速定位到具体文件。当offset=368776时定位到00000000000000368769.index|log
第二步 图2 ,通过segment file查找message 通过第一步定位到segment file,当offset=368776时,依次定位到00000000000000368769.index的元数据物理位置和00000000000000368769.log的物理偏移地址,然后再通过00000000000000368769.log顺序查找直到offset=368776为止。
这样做的优点很明显,segment index file采取稀疏索引存储方式,它减少索引文件大小,通过mmap可以直接内存操作,稀疏索引为数据文件的每个对应message设置一个元数据指针,它比稠密索引节省了更多的存储空间,但查找起来需要消耗更多的时间。


--end--
扫描下方二维码
添加好友,备注【交流】
可私聊交流,也可进资源丰富学习群