
为什么芯片设计也需要「匠人精神」?
曾经看到过一部红极一时的纪录片《寿司之神》。
小野二郎是世界上年纪最大的米其林三星主厨,老爷子一辈子就钻研了一件事:寿司。
在垂直的领域做到世界顶级,靠的就是匠人精神。
如果我们抛开那些外在的包装和炒作,沉淀下来去观察他做的事情,就不难发现匠人精神的本质,其实就是专业和坚持。
捏寿司是这样,各行各业也是这样。
推动行业发展的,或许并不是图灵那样可遇不可求的天才,而是更多『匠人』对极致的追求,特别是他们在某个小领域不断地深耕、优化、提升。
打个最简单的比方,天才创造了开天辟地的理论,就像是1,但需要无数匠人在后面补上0,才能让这个数变的越来越大。
芯片行业也不例外。
当FPGA在1984年诞生的时候,就像是一个不起眼的1,没有人会想到这将成为一个价值几十亿美元的产业。不到四十年的时间,后面加了十个0。
这就是指数级的爆发。
摩尔定律描述的就是指数级的规律,而FPGA一直都是体现摩尔定律的最好例子。接下来我们就从FPGA存储器这个小领域,看看匠人精神是怎么用在这里的。
1、新型存储架构
英特尔总结过,FPGA现在和未来的发展趋势只有三个:
传输更快,存储更多,计算更广。
Move fast, Store more, Process everything.
所以,就像不要觉得寿司只是酸米饭配芥末一样,再也不要觉得FPGA只是用来做芯片原型验证的了。FPGA早就被用作高能效的硬件加速单元,去加速你能想到的所有应用了。
FPGA之所以有这样的能力,是由它本身的结构决定的。比如FPGA有着很强的硬件并行性,能像GPU那样进行并行运算,但功耗却低很多;它还能灵活地调整数据的精度,让神经网络的压缩和优化成为现实。
同样重要的是,FPGA能提供极高的内存带宽、同时兼顾计算的效率,从而解决很多应用都存在的内存瓶颈问题。
而存储,就是FPGA上最体现「匠人」功力的地方。
传统的FPGA存储单元并不是只有一种结构,而是分成下面两类:
片上内存:如M20K、MLAB等
片外内存:如DDR5、LPDDR5等
片上内存速度最快、容量最小、造价最高;片外内存速度慢、容量大、造价低。
这样的结构,并不是某个天才一拍脑门想出来的。最早的FPGA只支持片上内存。但是随着需要处理的数据越来越多,就慢慢加入了对片外内存的支持,并且逐渐成为了主流FPGA的标配。
匠人精神的本质,就是不断发现问题、解决问题、并且极致优化的过程。
在这个过程中人们逐渐发现,片上和片外这两种内存之间,仍然存在着一个巨大而关键的缺口:对于很多数据密集型的应用,它们的数据量比片上内存的容量大得多,但对于带宽的需求又比片外内存能提供的大得多。
这时出现了第三种内存类型:封装内存。这种内存的最典型代表,就是HBM。
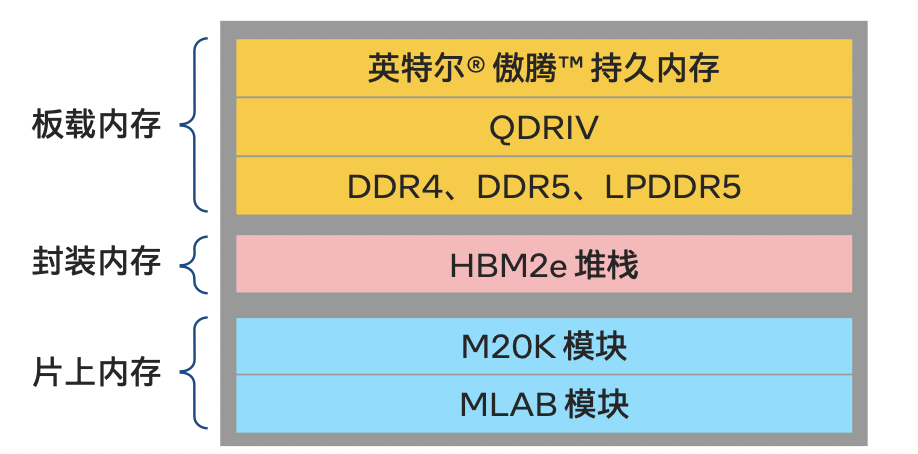
典型的存储层次结构
它之所以叫「封装内存」,是因为内存颗粒与FPGA被集成在同一个芯片封装里了。比如在英特尔最新的Agilex-M系列FPGA里,就在芯片的上下两侧通过EMIB技术集成了两个HBM2e,这也是业界第一个集成了HBM2e高带宽存储器的FPGA。这样不仅减小了芯片的尺寸,还能进一步降低功耗和数据传输的时延。
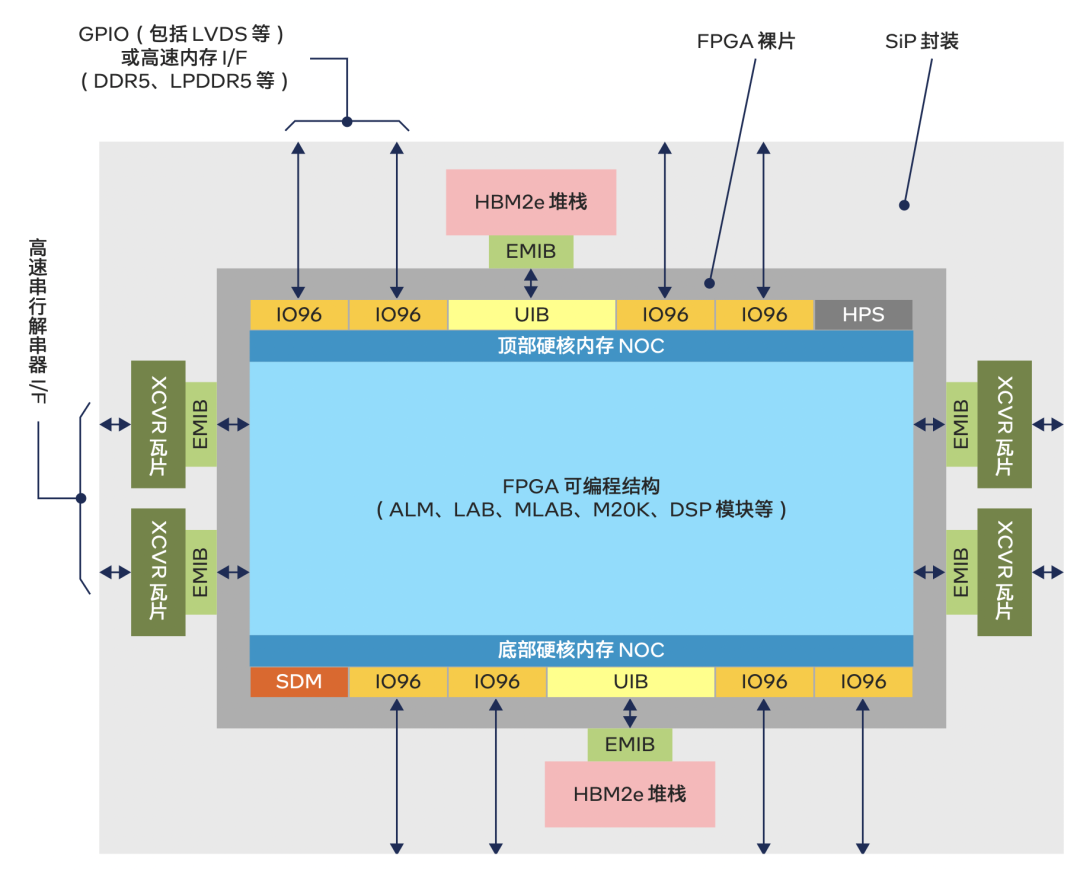
英特尔Agilex-M FPGA平面图
一个有趣的小知识,Agilex-M的“M”,就是Memory存储器的意思。也就是说,Agilex-M就是专门为高性能存储而优化的FPGA芯片。
和传统的芯片结构不同,HBM2e是一种三维结构。如果说传统芯片是平房,那么HBM2e就是大楼。所以在容量这个维度,HBM2e秒杀片上内存。比如它可以包含4层或8层,每层提供2GB内存,再考虑到一个Agilex-M里包含两个HBM2e,这样FPGA就能提供高达32GB的内存容量,比片上内存多两个数量级。
从内存带宽这个维度来看,每个HBM2e能提供410Gbps的内存带宽,比业界前沿的DDR5和GDDR6分别高18倍、和高7倍,比更加“主流”的DDR4等等更不知道要高到哪里去了。
有了HBM,看起来存储的问题已经解决了?还远远没有:HBM只是第一步。
2、新型非易失性存储
对于片外内存,新的问题又出现了。对于很多应用来说,DDR最大的问题并不是慢,而是断电后数据会消失。这时人们就不得不采用闪存这样的“非易失性”存储,来保存那些关键数据。但硬币的另一面,是闪存的性能比DDR还要低。
为了解决这个问题,英特尔提供了一种名叫“傲腾”的新型存储介质,这种存储级内存其存储密度比普通内存高,但存取速度又比闪存快。更重要的是,傲腾™技术作为一种持久内存的形态存在时(之所以这么表达是因为还有一个傲腾SSD。。。怕有混淆,您看看这样说是不是更好?),它独有的非易失性,使得它里面存的数据在断电后并不会消失。与 DRAM 内存相比,持久内存具有更经济的价格和更大的容量,和固态盘相比则拥有更优的数据响应速度和传输速度(接近 DRAM 内存)。正因于此,傲腾也逐渐成为了很多高性能应用里的关键存储单元,多用来做内存的大补充或者为内存密集型应用和延时敏感型应用服务。
3、片上网络,终于来了
同样还在进化的,是FPGA的芯片架构。之前的文章里介绍过,Agilex FPGA对芯片布局进行了大修,把各种I/O接口和存储单元都移到了芯片的上下两端,把各种高速收发器放在了芯片的左右两端,这样芯片中间就成了一个像足球场一样的特别平整的结构。之前开一个大脚会踢到各种模块单元,数据跑起来自然就慢。现在一马平川,没有挡路的东西了,数据跑起来就快多了。
可以说,这已经是近几年来FPGA架构上最有创意的尝试了。但你以为这样就完了吗?
Agilex-M最大的架构变化,就是引入了片上网络Network-on-Chip。这就像在城市规划里,不仅有道路交通,还有轨道交通。在轨道上运行的地铁或城铁,不仅速度可以更快,还能运更多的人。更重要的是,轨道可以建在地上或者地下,不影响在路上跑的汽车自行车摩托车。
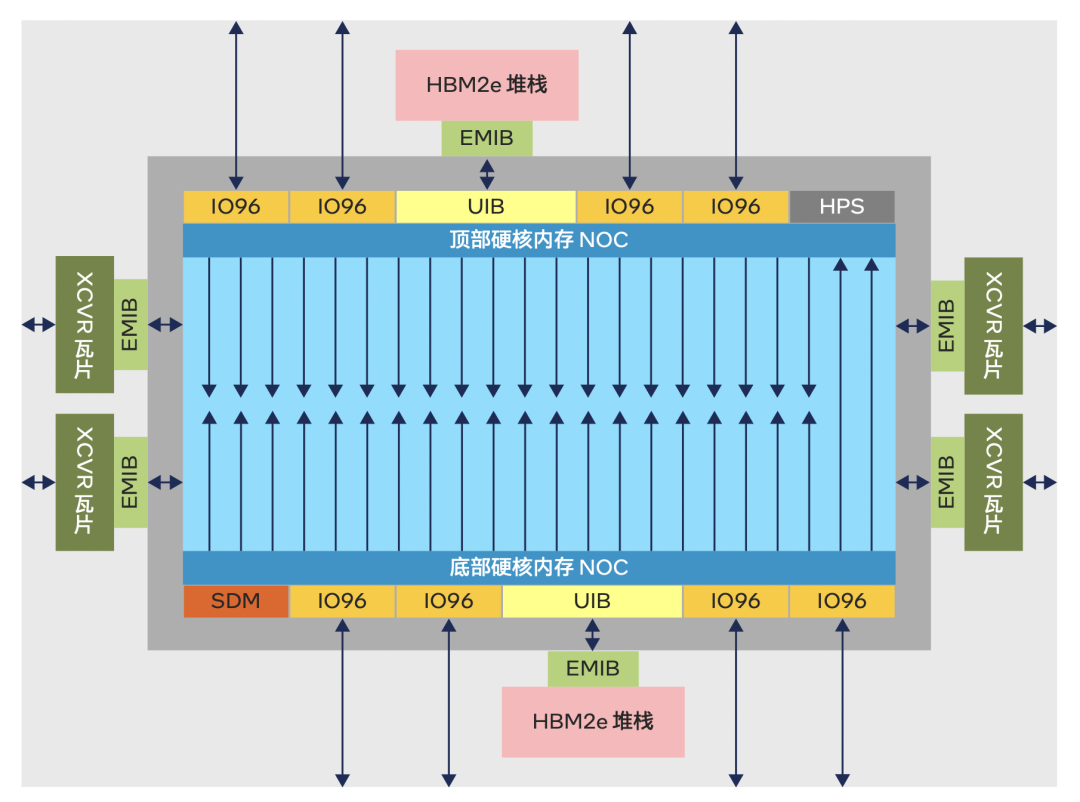
Agilex-M的片上网络NoC结构示意图
Agilex-M的片上网络专门为存储设计,也就是说,这是一趟专列。
有了片上网络,FPGA和各种内存之间的数据传输就不用经过FPGA的路由资源了。HBM2e通过UIB接口连接片上网络、DDR和傲腾这些片外内存则通过IO96子系统连接片上网络,并且可以实现7.52Tbps的总带宽。
4、其他架构优化
除了片上网络,Agilex-M还有很多其他的架构优化。I/O方面,它的收发器带宽可以达到116Gbps,可以支持CXL、PCIe Gen5、400G以太网等等这些数据中心和网络通信的最新协议和接口。
计算性能方面,Agilex-M集成了高达12300个可变精度DSP模块,可以支持高达18.5TFLOPS的单精度浮点运算、37TFLOPS的半精度浮点运算、以及88.6TOPS的INT8运算。

结语
作为专门针对存储性能进行优化的FPGA,Agilex-M已经把优化做到了极致。这样的优化方式和思路其实有着很强的普适意义:它并不是由某个天才创造出来的突破性成果,而是在各种问题的驱动下,一步一步发展起来的,然后靠一个个拥有「匠人精神」工程师的专注与积累,达到最后的结果。
在大多数情况下,这种方式更加现实,也更加有效。
(关于Agilex M 系列FPGA的更多内容和技术细节,可以点击“阅读原文”查看)