
为什么需要Kafka?

背景
Kafka最早是由LinkedIn公司开发的,作为其自身业务消息处理的基础,后LinkedIn公司将Kafka捐赠给Apache,现在已经成为Apache的一个顶级项目了,Kafka作为一个高吞吐的分布式的消息系统,目前已经被很多公司应用在实际的业务中了,并且与许多数据处理框架相结合,比如Hadoop,Spark等。
消息系统
在实际的业务需求中,我们需要处理各种各样的消息,比如Page View,日志,请求等,那么一个好的消息系统应该拥有哪些功能呢?
拥有消息发布和订阅的功能,类似于消息队列或者企业消息传送系统;
能存储消息流,并具备容错性;
能够实时的处理消息;
以上3点是作为一个好的消息系统的最基本的能力。
那么Kafka为什么会诞生呢?
其实在我们工作中,相信有很多也接触过消息队列,甚至自己也写过简单的消息系统,它最基本应该拥有发布/订阅的功能,如下图所示:
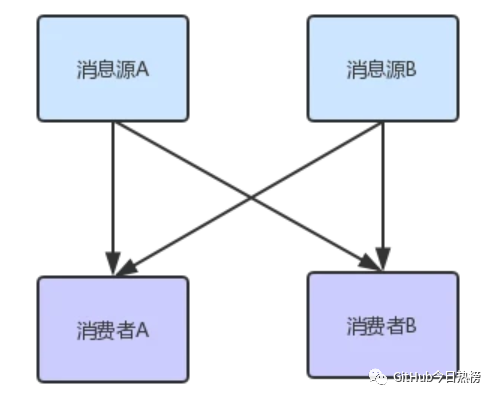
其中消费者A与消费者B都订阅了消息源A和消息源B,这种模式很简单,但是相对来说也有弊端,比如以下两点:
该模式下消费者需要实时去处理消息,因为这里消息源和消费者都不会维护一个消息队列(维护代价太大),这将会导致消费者若是暂时没有能力消费,则消息会丢失,当然也就不能获得历史的消息;
消息源需要维护原本不属于它的工作,比如维护订阅者(消费者)的信息,向多个消费者发送消息,亦或者有些还需要处理消息反馈,这是原本纯粹的消息源就会变得越来越复杂;
当然这些问题都是可以改进的,比如我们可以在消息源和消费者中间增加一个消息队列,如下图所示:
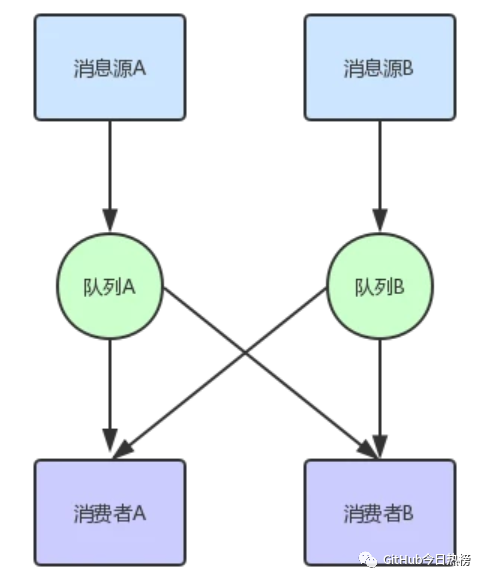
从图中我们可以看出,现在消息源只需要将消息发送到消息队列中就行,至于其他就将给消息队列去完成,我们可以在消息队列持久化消息,主动推消息给已经订阅了该消息队列的消费者,那么这种模式还有什么缺点吗?
答案是有,上图只是两个消息队列,我们维护起来并不困难,但是如果有成百上千个呢?那不得gg,其实我们可以发现,消息队列的功能都很类似,无非就是持久化消息,推送消息,给出反馈等功能,结构也非常类似,主要是消息内容,当然如果要通用化,消息结构也要尽可能通用化,与具体平台具体语言无关,比如用JSON格式等,所有我们可以演变出以下的消息系统:
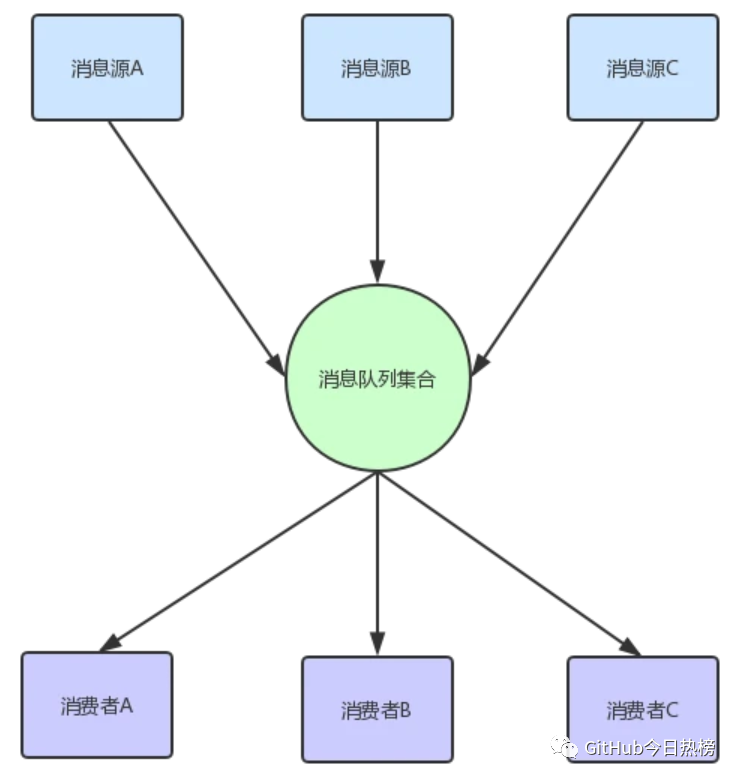
这个方式看起来只是把上面的队列合并到了一起,其实并不那么简单,因为这个消息队列集合要具备以下几个功能:
能统一管理所有的消息队列,不是特殊需求不需要开发者自己去维护;
高效率的存储消息;
消费者能快速的找到想要消费的消息;
当然这些只是最基本的功能,还有比如多节点容错,数据备份等,一个好的消息系统需要处理的东西非常多,很庆幸,Kafka帮我们做到了。
Kafka
在具体了解Kafka的细节前,我们先来看一下它的一些基本概念:
Kafka是运行在一个集群上,所以它可以拥有一个或多个服务节点;
Kafka集群将消息存储在特定的文件中,对外表现为Topics;
每条消息记录都包含一个key,消息内容以及时间戳;
从上面几点我们大致可以推测Kafka是一个分布式的消息存储系统,那么它就仅仅这么点功能吗,我们继续看下面。
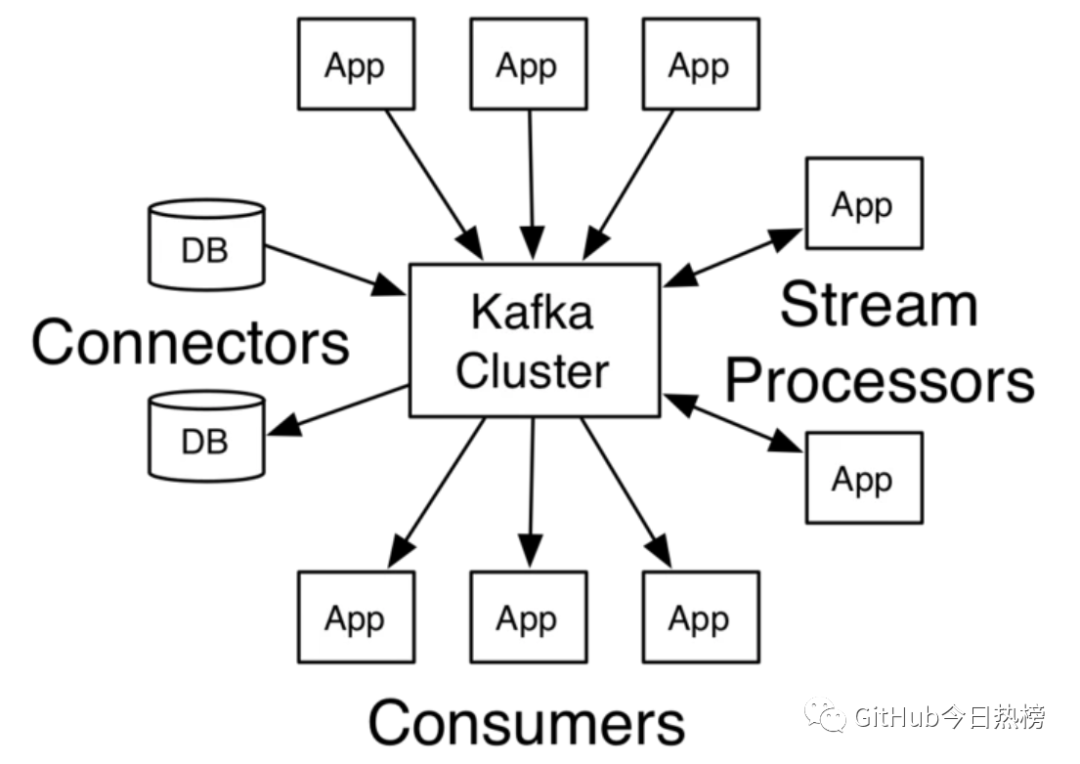
Kafka为了拥有更强大的功能,提供了四大核心接口:
Producer API允许了应用可以向Kafka中的topics发布消息;
Consumer API允许了应用可以订阅Kafka中的topics,并消费消息;
Streams API允许应用可以作为消息流的处理者,比如可以从topicA中消费消息,处理的结果发布到topicB中;
Connector API提供Kafka与现有的应用或系统适配功能,比如与数据库连接器可以捕获表结构的变化;
它们与Kafka集群的关系可以用下图表示:
在了解了Kafka的一些基本概念后,我们具体来看看它的一些组成部分。
Topics
顾名思义Topics是一些主题的集合,更通俗的说Topic就像一个消息队列,生产者可以向其写入消息,消费者可以从中读取消息,一个Topic支持多个生产者或消费者同时订阅它,所以其扩展性很好。Topic又可以由一个或多个partition(分区)组成,比如下图:
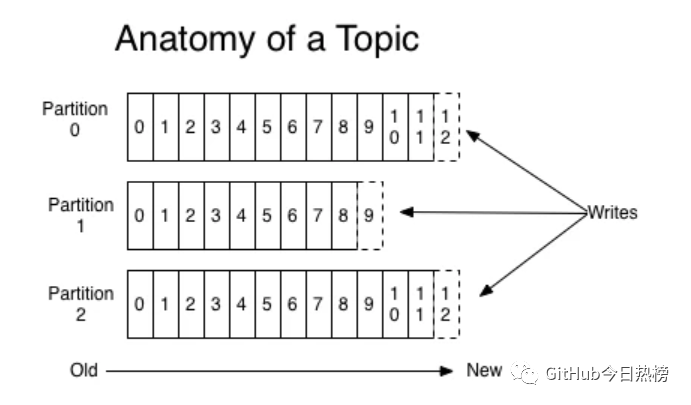
其中每个partition中的消息是有序的,但相互之间的顺序就不能保证了,若Topic有多个partition,生产者的消息可以指定或者由系统根据算法分配到指定分区,若你需要所有消息都是有序的,那么你最好只用一个分区。另外partition支持消息位移读取,消息位移有消费者自身管理,比如下图:
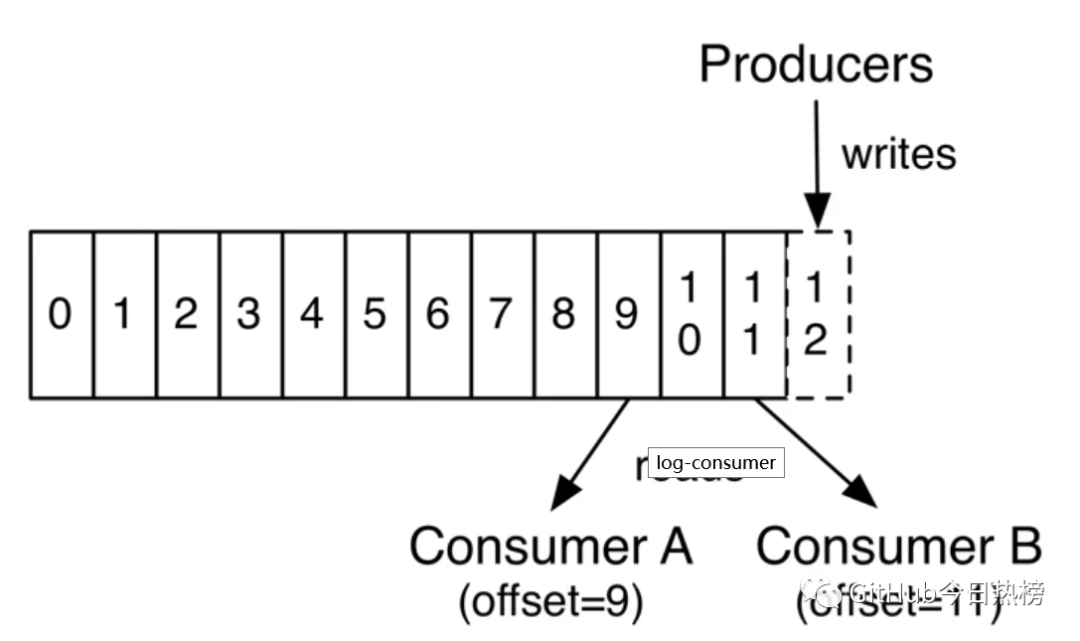
由上图可以看出,不同消费者对同一分区的消息读取互不干扰,消费者可以通过设置消息位移(offset)来控制自己想要获取的数据,比如可以从头读取,最新数据读取,重读读取等功能。
关于Topic的分区策略以及与消费者间平衡后续文章会继续深入讲解。
Distribution
上文说到过,Kafka是一个分布式的消息系统,所以当我们配置了多个Kafka
Server节点后,它就拥有分布式的能力,比如容错等,partition会被分布在各个Server节点上,同时它们中间又有一个leader,它会处理所有的读写请求,其他followers会复制leader上的数据信息,一旦当leader因为某些故障而无法提供服务后,就会有一个follower被推举出来成为新的leader来处理这些请求。
Geo-Replication
异地备份是作为主流分布式系统的基础功能,用于集群中数据的备份和恢复,Kafka利用MirrorMaker来实现这个功能,用户只需简单的进行相应配置即可。
Producers
Producers作为消息的生产者,可以自己指定将消息发布到订阅Topic中的指定分区,策略可以自己指定,比如语义或者结构类似的消息发布在同一分区,当然也可以由系统循环发布在每一个分区上。
Consumers
Consumers是一群消费者的集合,可以称之为消费者组,是一种更高层次的的抽象,向Topic订阅消费消息的单位是Consumers,当然它其中也可以只有一个消费者(consumer)。下面是关于consumer的两条原则:
假如所有消费者都在同一个消费者组中,那么它们将协同消费订阅Topic的部分消息(根据分区与消费者的数量分配),保存负载平衡;
假如所有消费者都在不同的消费者组中,并且订阅了同个Topic,那么它们将可以消费Topic的所有消息;
下面是一个简单的例子,帮助大家理解:

上图中有两个Server节点,有一个Topic被分为四个分区(P0-P4)分别被分配在两个节点上,另外还有两个消费者组(GA,GB),其中GA有两个消费者实例,GB有四个消费者实例。
从图中我们可以看出,首先订阅Topic的单位是消费者组,另外我们发现Topic中的消息根据一定规则将消息推送给具体消费者,主要原则如下:
若消费者数小于partition数,且消费者数为一个,那么它就消费所有消息;
若消费者数小于partition数,假设消费者数为N,partition数为M,那么每个消费者能消费的分区数为M/N或M/N+1;
若消费者数等于partition数,那么每个消费者都会均等分配到一个分区的消息;
若消费者数大于partition数,则将会出现部分消费者得不到消息分区,出现空闲的情况;
总的来说,Kafka会根据消费者组的情况均衡分配消息,比如有消息着实例宕机,亦或者有新的消费者加入等情况。
Guarantees
kafka作为一个高水准的系统,提供了以下的保证:
消息的添加是有序的,生产者越早向订阅的Topic发送的消息,会更早的被添加到Topic中,当然它们可能被分配到不同的分区;
消费者在消费Topic分区中的消息时是有序的;
对于有N个复制节点的Topic,系统可以最多容忍N-1个节点发生故障,而不丢失任何提交给该Topic的消息丢失;
相关这些点的细节,我准备再后续文章中再慢慢深入。
Kafka as a Messaging System
说了这么多,前面也讲了消息系统的演变过程,那么Kafka相比其他的消息系统优势具体在哪里?
传统的消息系统模型主要有两种:消息队列和发布/订阅。
1.消息队列
| 特性 | 描述 |
|---|---|
| 表现形式 | 一组消费者从消息队列中获取消息,消息会被推送给组中的某一个消费者 |
| 优势 | 水平扩展,可以将消息数据分开处理 |
| 劣势 | 消息队列不是多用户的,当一条消息记录被一个进程读取后,消息便会丢失 |
2.发布/订阅
| 特性 | 描述 |
|---|---|
| 表现形式 | 消息会广播发送给所有消费者 |
| 优势 | 可以多进程共享消息 |
| 劣势 | 每个消费者都会获得所有消息,无法通过添加消费进程提高处理效率 |
从上面两个表中可以看出两种传统的消息系统模型的优缺点,所以Kafka在前人的肩膀上进行了优化,吸收他们的优点,主要体现在以下两方面:
通过Topic方式来达到消息队列的功能
通过消费者组这种方式来达到发布/订阅的功能
Kafka通过结合这两点(这两点的具体描述查看上面章节),完美的解决了它们两者模式的缺点。
Kafka as a Storage System
存储消息也是消息系统的一大功能,Kafka相对普通的消息队列存储来说,它的表现实在好的太多,首先Kafka支持写入确认,保证消息写入的正确性和连续性,同时Kafka还会对写入磁盘的数据进行复制备份,来实现容错,另外Kafka对磁盘的使用结构是一致的,就说说不管你的服务器目前磁盘存储的消息数据有多少,它添加消息数据的效率是相同的。
Kafka的存储机制很好的支持消费者可以随意控制自身所需要读取的数据,在很多时候你也可以将Kafka作为一个高性能,低延迟的分布式文件系统。
Kafka for Stream Processing
Kafka作为一个完美主义代表者,光有普通的读写,存储等功能是不够的,它还提供了实时处理消息流的接口。
很多时候原始的数据并不是我们想要的,我们想要的是经过处理后的数据结果,比如通过一天的搜索数据得出当天的搜索热点等,你可以利用Streams API来实现自己想要的功能,比如从输入Topic中获取数据,然后再发布到具体的输出Topic中。
Kafka的流处理可以解决诸如处理无序数据、数据的复杂转换等问题。
总结
消息传递、存储、流处理这么功能单一来看确实很普通,但如何把它们完美的结合到一起,就是一种优雅的体现,Kafka做到了这一点。
相比HDFS分布式文件存储系统,虽然它能支持高效存储并且批处理数据,但是它只支持处理过去的历史数据。
相比普通的消息系统来说,虽然能处理现在至未来的数据,但是它并不没有存储历史的数据。
Kafka集众家之所长,使整个系统能兼顾各方面的需求,可以用一个词来说:“完美”!
出处:segmentfault.com/a/1190000013834998
关注GitHub今日热榜,专注挖掘好用的开发工具,致力于分享优质高效的工具、资源、插件等,助力开发者成长!
点个在看