从0到1详解数据挖掘过程

导读:数据挖掘过程包含数据清洗、特征提取、算法设计等多个阶段,本文将讨论这些阶段。
作者:查鲁·C.阿加沃尔(Charu C. Aggarwal)
来源:大数据DT(ID:hzdashuju)

01 数据挖掘过程
典型数据挖掘应用的过程包含以下几个阶段。
1. 数据采集
数据采集工作可能是使用像传感器网络这样的专门硬件、手工录入的用户调查,或者如Web爬虫那样的软件工具来收集文档。虽然这个阶段与具体应用息息相关,但常常落在数据挖掘分析师们所考虑的范围之外,而这个阶段对数据挖掘过程也是至关重要的,因为这一阶段所做的选择会明显地影响整个数据挖掘过程。
采集阶段产生的数据通常会先存入数据库,广义上称为数据仓库,然后进行处理。
2. 特征提取和数据清洗
上述采集阶段得到的数据,其格式往往不适合直接进行处理。例如,采集来的数据可能是使用复杂编码的日志或自由格式的文档,并在许多情况下,各种类型的数据又任意地混合在一起,形成自由格式的文档。
要使这样的数据适合进一步加工,有必要把它们转化为对数据挖掘算法较为合适的格式,比如多维数据、时序数据或者半结构化数据等。
多维数据是最常见的格式,其不同的字段对应于可以称为特征、属性或维度的各种测量属性。抽取这些特征是数据挖掘的一个至关重要的阶段,而特征提取阶段通常与数据清洗阶段并行进行,以便估计或校正丢失的数据以及错误的数据。
另外,在许多情况下,数据可能从多个来源聚集而成,进行处理时需要把它们转换为统一的格式。上述过程的最终结果是一个有较好结构的数据集,可以由计算机程序有效地使用。在特征提取阶段之后,数据可以存回到数据库中用于进一步的处理。
3. 分析处理和算法
数据挖掘过程的最后一步是为处理过的数据设计有效的分析方法。在许多情况下,不太可能将手头的应用直接转化成一个标准的数据挖掘问题,比如转化成关联模式挖掘、聚类、分类以及异常检测这四个“超级问题”中的某一个。
但这四个超级问题具有很广泛的覆盖性,可以构成数据挖掘任务的基本模块,而大多数应用都能由这些作为基本模块的组件拼搭起来实现。
整个数据挖掘过程可由图1-1表示。请注意,图中的分析处理模块显示了对特定应用设计的、由多个基本模块组合而成的解决方案,这一部分依赖于分析师的技能。通常的做法是使用四个主要问题中的一个或多个作为基本模块来搭建。
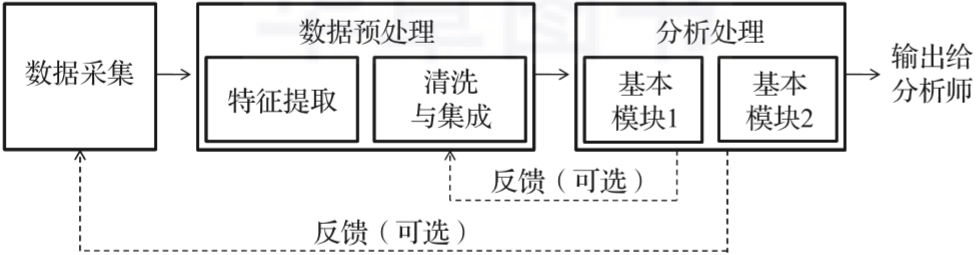
▲图1-1 数据处理流水线
需要承认的是,并非所有的数据挖掘应用都能用这四个主要问题来搭建解决方案,但许多应用可以这样解决,因此有必要给予这四个主要问题一个特殊的地位。下面我们使用一个有关推荐的应用实例来解释数据挖掘的整个过程。
示例1.2.1 考虑这样一个网上零售商的场景,此零售商保存了客户访问其网站的访问日志,还收集了客户的基本情况信息。假设网站的每个网页对应一个商品,客户访问一个网页可能表明对相应的商品感兴趣。零售商希望通过对客户的个人资料及其购买行为的分析,有针对性地给客户推荐商品。
解决问题的流程示例:分析师的第一步工作是收集两种不同来源的数据,其一是从该网站的日志系统中抽取的日志,其二是从零售商的数据库中抽取的客户个人资料。这里的一个难题就是这两种数据使用了非常不同的数据格式,放到一起处理很不容易。例如,一条日志可以以下面这种形式出现。

日志中可能包含成千上万个这种条目,上面这一条目显示IP地址为98.206.207.157的客户访问了productA.htm这一网页。要确认使用一个IP地址的客户是谁,可以通过之前的登录信息,或者通过网页的cookie记录,甚至直接通过IP地址本身,但这个确认过程可能充满噪声,不可能总是产生准确的结果。
作为数据清洗和提取过程的一部分,分析师还需要设计算法对不同的日志条目进行有效的过滤,以便只使用那些提供准确结果的数据段,因为原始日志中包含很多对零售商可能没有任何用处的额外信息。
在特征提取阶段,零售商决定从网页访问日志中提取特征,为每个客户创建一条记录,其中将每个商品设置为一个属性,记录此客户对相应商品网页的访问次数。
因此,这个特征抽取需要对每条原始日志进行处理,并将多条日志中抽取的特征进行聚合。之后在数据集成时,再将这些属性数据添加到零售商的客户数据库中去。这个客户数据库包含客户个人资料,倘若个人资料记录中缺少某些条目,则需要为其进行进一步的数据清洗。
最终,我们得到一个数据集,将客户个人资料的属性及客户对商品访问次数的属性整合在一起。
此时,分析师需要决定如何使用此清洗过的数据集,为客户提供推荐。分析师可以将类似的客户分成几类群体,并根据每类群体的购买行为提出推荐意见。
聚类分析在这里可以作为一个基本模块,用于确定类似客户的群体。对每一个客户,可以为其推荐该客户所在群体作为一个整体访问最多次的商品(这里指的是商品网页)。这个案例包含了一个完整的数据挖掘流程。
有许多优美的提供推荐的方法,它们在不同的情况下各有优劣,因此,整个数据挖掘过程是一门艺术,很大程度由分析师的技能所决定,而不完全由特定的技术或基本模块所左右,这种技能只能通过在不同应用需求下处理各类不同数据的实践中获得。

02 数据预处理阶段
数据预处理阶段也许是数据挖掘过程中最关键的一个阶段,然而,这个阶段很少得到应有的探讨,因为大部分数据挖掘讨论的重点放在了数据分析方面。这一阶段在数据采集后就开始,包括以下步骤。
1. 特征提取
分析师可能面临大量的原始文件、系统日志、商业交易,但几乎没有任何指导性的快速入门方法将这些原始数据转化为有意义的数据。这一步骤高度依赖于分析师的抽象能力,以找出与手头应用最相关的特征。
例如,在信用卡欺诈检测应用中,收费金额、重复频率以及位置信息往往是找出欺诈的有效指标,而许多其他特征信息也许就用处不大。因此,提取正确的特征往往是个技术活,需要对手头应用相关的领域有充分的了解。
2. 数据清洗
上述特征提取得到的数据中可能含有错误,也有些条目可能在采集及提取时丢失。因此,我们可能要丢弃一些含有错误的数据记录,或者对缺失的条目进行估计填充,并剔除数据中的不一致性。
3. 特征选择与转换
当数据维度很高时,很多数据挖掘算法就会失效。而且当数据维度很高时,数据噪声会增加,可能带来数据挖掘的错误。因此,需要使用一些方法,移除与应用无关的特征,或者将数据变换到一个新的维度空间中,使数据分析更容易进行。
另一个相关的问题是数据转换,将一些属性转换为另一种相同或类似数据类型的属性。比如将年龄数值转化成年龄段,可能对分析更有效也更便利。
数据清洗过程中通常需要使用对缺失数据进行估计的统计方法,此外,为确保挖掘结果的准确性,通常需要剔除错误的数据条目。
由于特征选择和数据转换高度依赖于具体的分析问题,不应视为数据预处理的一部分,甚至在某些情况下,特征选择可能与具体算法或方法紧密结合,以一种包装模型或嵌入模型的形式出现。但在一般情况下,会在应用具体挖掘算法之前执行特征选择阶段。
03 分析阶段
一个主要的挑战是每个数据挖掘应用都是独特的,很难为很多类应用打造出一个灵活的、可复用的挖掘技术。然而,我们发现有些数据挖掘方法在各类应用中反复出现,即所谓的“超级问题”或数据挖掘的基本模块。
怎样在特定的数据挖掘应用中使用这些基本方法很大程度上取决于分析师的技能和经验,所以虽然可以对这些基本模块进行很好的描述,但怎样在实际应用中使用它们,只能通过实践来学习。
关于作者:查鲁C. 阿加沃尔(Charu C. Aggarwal),IBM T. J. Watson研究中心的杰出研究人员,于1996年获麻省理工学院博士学位。他对数据挖掘领域有着广泛的研究,在国际会议和期刊上发表了250多篇论文,拥有80多项专利。他曾三次被评为IBM的“杰出发明人”,并曾获得IBM公司奖、IBM杰出创新奖和两项IBM杰出技术成就奖。
本文摘编自《数据挖掘:原理与实践(基础篇)》,经出版方授权发布。

延伸阅读《数据挖掘:原理与实践(基础篇)》
点击上图了解及购买
转载请联系微信:DoctorData
推荐语:大数据和人工智能时代数据挖掘教材,从四个“超级问题”出发,详解数据挖掘的基础知识,介绍高级数据类型,结合复杂多样的实际数据环境,探讨数据挖掘的应用场景和使用方法。

干货直达👇