
如何看待 DeepMind 论文宣称构建通用人工智能的所有技术已经具备?

来源:知乎
回答整理自知乎,著作权归属原作者,侵删。
匿名用户回答:
比这篇文章的内容更令人绝望的是这篇文章的作者。
一作是david silver,通讯是richard sutton,对RL有点了解的应该都知道这两个名字意味着什么。
这种江湖地位的人要亲自下场来写些我怀疑他们自己是不是都不相信的东西,那这个领域的前景可想而知了。
再结合一下这几年的形式,尤其是,关注一下全世界最厉害的那几个大牛,人才最多的那几个实验室,都在产出什么文章。
傻孩子们,快跑啊!

桔了个仔回答:
目录
论文内容
摘要
1. Introduction
2. BackGround
3. Reward is Enough
4. Reinforcement learning agents
5. Related work
6. Discussion
7. Conclusion
总结与吐槽
首先,问题和新闻报道我觉得并不准确。论文并没有「宣称所有技术已经具备」,仅仅是提出了一个构建通用人工智能的方向。不过确实也不能怪媒体,你这个《xxx is enough》的论文届震惊体确实也够唬人,真怀疑deepmind团队和uc震惊部是否经常合作。
预感未来几年论文的标题将会变化,以前是《xxx is all you need》,这篇《Reward is Enough》出来后,估计以后大家都写《xxx is Enough》这种标题了。
不过这篇论文读起来算是很轻松,没有复杂的公式。与其说是技术论文,不如说是哲学论文。
这里允许我再解读多些:作者写的是:Reward而不是Rewards,作者的论点是,单个reward就能催生复杂的智能行为,甚至产生通用人工智能。
论文内容
我们来看看这篇论文的内容吧。我不太擅长翻译论文,若中文内容读起来不太通顺,还得烦请读者读原文。
摘要
首先看看摘要。

主要内容是,在这个文章里,作者假设智能以及其相关能力,都可以被理解成促进奖励最大化。因此(咦,这个Accordingly真的成立吗),奖励足以驱动自然和人工智能领域所研究的智能行为,包括知识、学习、感知、社交智能、语言、泛化能力和模仿能力。然后就是讲强化学习里的trial and error,最后笔锋一转,「因此强大的强化学习代理可以构成通用人工智能的解决方案」。
额,看到这里感觉,摘要里的「起承转合」似乎上升得有点快?好吧,看看文章内容。
1. Introduction
Introduction部分基本就是在概括强化学习的概念,以及总结自己提出新的东西。首先,作者总结了各种智能体(自然的或者人造的)的原理。

然后作者说到:在本文中,我们考虑了另一种假设:
最大化奖励的通用目标足以驱动某些行为,这些行为表现出大多数的(如果不是所有)能力是自然和人工智能所研究的(原文真的句子太长了,读起来费劲)
接着,用了松鼠觅食和机器人清洁为例子,介绍了强化学习的概念,论述了自己的观点:追求单个目标可以催生多种智能行为。
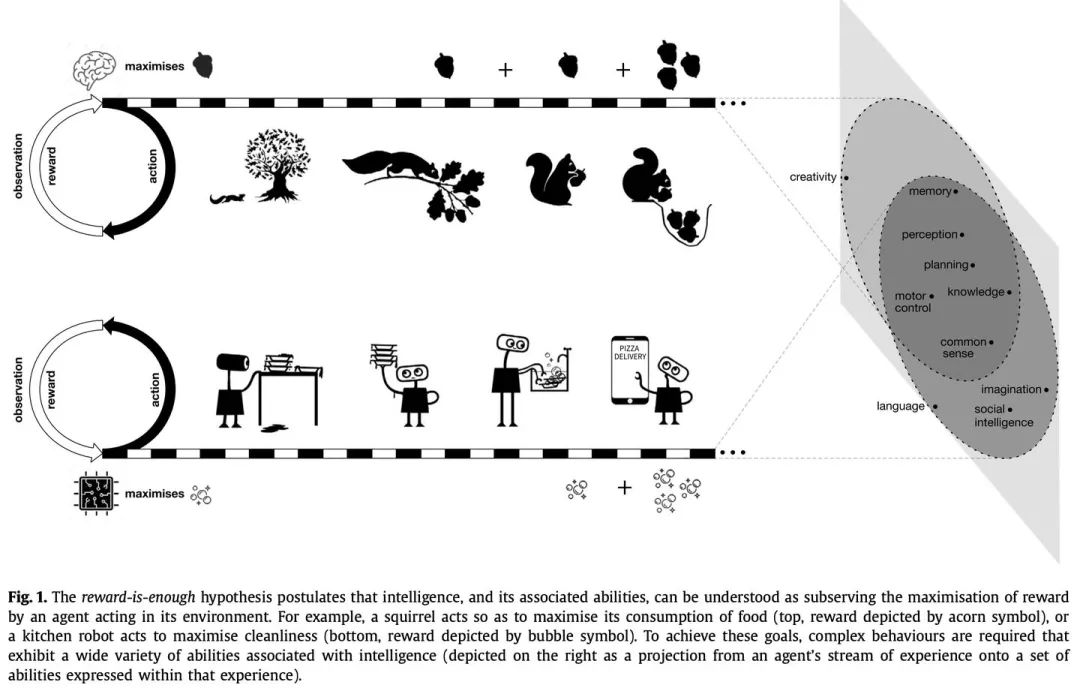
「追求单个目标也许能产生复杂的行为,展现出多种智能相关的能力。」我猜作者的意思是,你们别搞太复杂的系统,也许一个很简单的系统,只要reward给对了,就会自己产生行为。

作者还拿了AlphaZero来做例子。但离general intelligence似乎有点距离吧(我个人觉得)

2. BackGround
这节没什么好介绍的,如果你了解强化学习,知道Agent,Environment,Reward的概念,就行了。
3. Reward is Enough
接下来重点来了。reward is enough for xxx,一共有七点:
Reward is enough for knowledge and learning
Reward is enough for perception
Reward is enough for social intelligence
Reward is enough for language
Reward is enough for generalisation
Reward is enough for imitation
Reward is enough for general intelligence
前面六点,我们也能理解。但第七点,咋就突然跳到了通用智能呢?我知道,通用智能研究的内容包括前面几点,但难道把前面几点结合一下就等于通用智能了吗?感觉是突然跨越了鸿沟。读这一节,给我的感觉,是这样的(图我自己p的):

4. Reinforcement learning agents
作者可能猜到了读者想问什么。没错,那么怎么构建一个能自己最大化奖励的agent呢?作者的回答是:还是通过最大化奖励的方法来构建这个agent。

那么如果这个agent真的行,训练得多久?作者说:我也不知道。

5. Related work
行吧,我们看看,目前都有哪些相关工作。
前面几段没有通用人工智能相关的,我们就看后面两段。

作者提到了Unified Cognitive Architectures(统一认知架构)在追求通用人工智能。然而,这种架构并不是提供一个通用的目标。也提到了某篇文章,论诉了在多代理模式下,追求单一代理的好处。
6. Discussion
基本就是Q&A环节了。回答了一些你也许会想到的问题。
7. Conclusion
大家都知道作者想说什么了。
总结与吐槽
总的来说,与其说是技术文章,不如说是哲学文章。虽然有很多吐槽说,「这篇文章不就是把效用函数优化换了个说法吗」,但其实不是的。作者试图指出一个新的研究方向:「别搞其他有的没的,只要RL搭配合适的reward,就行了」。万一这个方向对了,这篇文章就能名垂千古了。
也许作者真的想到了不错的观点,甚至在研发相应的架构了,这几位作者都是RL领域的大神了,但恕我直言,就这篇文章而言,仅仅是提出了「Reward is Enough」这个观点,论证过程确实不太能让人信服。
我个人认为,reward并不enough。那么什么才是enough?我推荐达尔文的《Evolution is Enough》(开玩笑的,达尔文的标题不是这样的)
事实上,在reddit上已经很多人吐槽了!
总体来说,大家都尊敬作者本人,认可其在RL领域的成就,但对这篇文章都非常不解。
例如这个人,想法和我一样:

这两位都是RL领域的大神,然而这篇文章的感觉是:「我用了数学方法来解决美丽的概念」
也有吐槽标题的


「什么时候才出现《够了,真的够了》的论文」
不过,还是很期望这几位大牛能跟着这篇文章的思路,做出一些让大家震惊的结果。
赵冷回答:
论文说的是“最大化奖励的强化学习可能足以导向通用人工智能”,这并不等于“所有技术已经具备”。论文中谈到了“也许使用尚未发现的算法”,更别提硬件了。他们还谈到奖励最大化的学习机制尚未确定,“如何在实际代理中有效学习去最大化奖励”是机器学习领域的核心问题[1]。
文中称“我们不对强化学习代理的样本效率提供任何理论保证”,并考虑到“能力出现的速度和程度将取决于特定的环境、学习算法和归纳偏差;人们构建的人工环境可能导致学习失败”,并没有像其他回答担忧的那样一味“画饼”。作者的推测是,“如果将强大的强化学习代理放置到复杂的环境中,那么在实践中会产生复杂的智能表达”。这是可以着手实验的。
文中考虑了一个替代假设:“奖励最大化”这一通用目标,足以驱动“自然智能和人工智能研究中的大部分(如果不是全部)”智能行为。这个想法是很可以理解的,从蚂蚁、白蚁的行为来看不言自明——不必真正达到最大化,只要效率没低到种群断绝,就还有改良的希望。
文中谈论的“人类和其他动物所拥有的那种通用智力,可以定义为在不同环境中灵活实现各种目标的能力”在生物学上也是受到诸多学者欢迎的。
文中讨论“不同形式的智能源于不同环境中不同奖励信号的最大化”“这些能力的产生将服务于一个单一的目标”并对比松鼠和机器人的时候,将松鼠的奖励目标定为“活着”并讨论子目标“饥饿最小化”,没去谈论个体的永生不死、种群的世代交替、演化之类问题,这是个取巧的办法。松鼠真正的奖励目标可能是松鼠自己并不知道的一件事:活着的目的是永远活着,即使个体暂时不能做到,一部分自我制造的物质也将继续自我制造下去。这避免了“上来就谈论将这个教给计算机、立即引起大量读者的末日情结”。
但是,在谈论“奖励对通用智能足够了”的时候,他们还是没忍住,为机器的单一目标列举的例子是“电池寿命或生存(such as battery-life or survival)”。
网络上有些很可爱的质疑,例如说“这个例子没有解释为什么同样是最大化奖励,人类就能写出人工智能,而松鼠就不行”——解决问题的方法不是单一的,我们也不能保证人类现在所走的道路是通往永生与力量的最佳道路,不能保证通用人工智能及超人工智能的可实现性,更不能保证超人工智能降临后人类不会被立即灭绝。松鼠也不必是一条合适的道路,细菌面对复杂环境的生存能力显然比它强得多。
神经科学家 Patricia Churchland 认为,“对于哺乳动物和鸟类而言,个体之间的亲情关系往往会对社会决策产生重大影响,比如动物会为了保护孩子而将自己置于危险中而不顾”,这篇论文里对社会决策的讨论可能需要补充。不过,我们可以预期,所谓亲情关系是“种群的世代交替”能够作为自我制造的一部分时迭代出来的,无需加入特别的先验知识或设定。
人工智能专家 Herbert Roitblat 认为这篇论文谈论的是无限猴子定理的类似物,目前强化学习代理的潜在操作方式是有限的,奖励标准、价值函数往往是提前设定的,和自然演化不好直接类比。大概他没理解自然演化涉及的化学物质的潜在操作方式也是有限的、物理化学性质也可以算是提前设定的吧。
参考
^作者的表述:One may of course wonder how to learn to maximise reward effectively in a practical agent. For example, the reward could be maximised directly (e.g. by optimising the agent's policy), or indirectly, by decomposing into subgoals such as representation learning, value prediction, model-learning and planning, which may themselves be further decomposed. We do not address this question further in this paper, but note that it is the central question studied throughout the field of reinforcement learning.
YukiRain回答:
更像是一篇为RL领域招揽人才的pr文,文章展开的层次太大,导致每个结论都只是蜻蜓点水,没有触及核心矛盾。
就拿reward is enuogh来说,文章认为所有knowledge,perception,language,social intelligence等等问题都可以归纳到RL的reward maximization框架下,这个道理在前几年RL刚刚火起来的时候就应该已经成为领域共识了,然而现实是,有多少人工就有多少智能这个基础的道理在RL上也并不会有多少变化。
对于足够复杂的任务来说,光是定义一个好的reward function就已经非常难了,因为过于sparse过于抽象的reward只会让模型什么都学不到,OpenAI做dota的时候就是手动设计一套make sense的reward function,然后人力迭代去调参,猜猜这种环境上得到一套可以用的参数需要多少人力多少时间?猜猜直接把这套参数用在王者荣耀上做微调细化,又需要多少人力多少时间能够达到人类顶尖玩家水平?
alphagozero用value网络拟合胜率,alphastar用population-based training,看起来都很比上面的人工调参更fancy,但这种实验需要的算力成本是一般公司望之而不能及的,这种实验对超参数值设定的敏感也是超出很多人心理预期的。
再说perception学习起来有多苦难,现在有什么不toy的RL环境是可以靠直接RGB image输入训练出来的吗?
NLP+RL,不做评价,心领神会。
Social intelligence里面的Nash equilibrium听起来很美好,然而像alphago这类基于self-play的算法并没有理论可以保障收敛到nash,而且用一套reward就能得到diversed policy behavior是美好的幻想,学术界对于population diversity的研究更多还是在action层面,而对于真正需要diversity的场景,policy之间的差异往往都是抽象的,就好比你要在dota里刻画四保一,速推或者冲脸这几种战术的policy差异,是很难在action维度构建一个metric来描述的。。。
有多少人工就有多少智能,只要这一点基础没有变,其他领域的人站在他们领域的山顶,望向RL这边的态度都是一致的:
“那座山很漂亮,就是太难爬”

读者,你好!我们建立人工智能学习交流群,欢迎对AI感兴趣的朋友扫码进群!
微商广告请绕道,谢谢合作!
