
Flask + echarts 轻松搞定 nginx 日志可视化

作者 | 太阳雪
来源 | Python 技术

124.64.19.27 - - [04/Sep/2020:03:21:12 +0800] "POST /api/hb.asp HTTP/1.1" 200 132 "http://erp.example.com/mainframe/main.html" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36" "-"
import re
obj = re.compile(r'(?P.*?)- - \[(?P )
result = obj.match(line)
# print(result.group("time"))
# ip处理
ip = result.group("ip").split(",")[0].strip() # 如果有两个ip,取第一个ip
# 状态码处理
status = result.group("status") # 状态码
# 时间处理
time = result.group("time").replace(" +0800", "") # 提取时间,并去掉时区信息
t = datetime.datetime.strptime(time, "%d/%b/%Y:%H:%M:%S") # 格式化
# request处理
request = result.group("request")
a = request.split()[1].split("?")[0] # 提取请求 url,去掉查询参数
# user_agent处理
ua = result.group("ua")
if "Windows NT" in ua:
u = "windows"
elif "iPad" in ua:
u = "ipad"
elif "Android" in ua:
u = "android"
elif "Macintosh" in ua:
u = "mac"
elif "iPhone" in ua:
u = "iphone"
else:
u = "其他设备"
# refer处理
referer = result.group("referer")
datatime 类型词典 对象中,即每行对于一个 词典 对象,最后将一个个对象追加到一个 列表 对象中,待进一步处理百度的 ip 定位服务,通过认证,可以获得每日 3 万次的免费配额
import requests
import os
ak = "444ddf895 ... a5ad334ee" # 百度 ak 需申请
# ip 定位方法
def ip2province(ip):
province = ipCache.get(ip, None)
if province is None:
url = f"https://api.map.baidu.com/location/ip?ak={ak}&ip={ip}&coor=bd09ll"
try:
province = json.loads(requests.get(url).text)['address'].split('|')[1]
ipCache[ip] = province
# 这里就需要写入
with open("ip_cache.txt","a") as f:
f.write(ip + "\t" + province + "\n")
return province
except Exception as e:
return "未知"
else:
return province
# 初始化缓存
ipCache = {}
if os.path.exists("ip_cache.txt"):
with open("ip_cache.txt", "r") as f:
data = f.readline()
while data:
ip, province = data.strip().split("\t")
ipCache[ip] = province
data = f.readline()
首先需要申请一个百度 app key 合成请求,通过 requests get,得到响应,从中提取到 ip 对应的省份信息 对应地址缓存,将没有缓存的结果存入 ipCache 词典对象,并写入 ip_cache.txt 文件,下次启动时,用缓存文件中的内容初始化 ipCache 词典对象 在每次需要获取 ip 对应地址时,先检查缓存,如果没有才通过 api 获取
列表 对象,列表对象很容易创建为 pandas 的 DataFramedef analyse(lst):
df = pd.DataFrame(lst) # 创建 DataFrame
# 统计省份
province_count_df = pd.value_counts(df['province']).reset_index().rename(columns={"index": "province", "province": "count"})
# 统计时段
hour_count_df = pd.value_counts(df['hour']).reset_index().rename(columns={"index": "hour", "hour": "count"}).sort_values(by='hour')
# 统计客户端
ua_count_df = pd.value_counts(df['ua']).reset_index().rename(columns={"index": "ua", "ua": "count"})
# 数据存储
to_excel(province_count_df, 'data.xlsx', sheet_name='省份')
to_excel(hour_count_df, 'data.xlsx', sheet_name='按时')
to_excel(ua_count_df, 'data.xlsx', sheet_name='客户端')
def to_excel(dataframe, filepath, sheet_name):
if os.path.exists(filepath):j
excelWriter = pd.ExcelWriter(filepath, engine='openpyxl')
book = load_workbook(excelWriter.path)
excelWriter.book = book
dataframe.to_excel(excel_writer=excelWriter,sheet_name=sheet_name,index=None, header=None)
excelWriter.close()
else:
dataframe.to_excel(filepath, sheet_name=sheet_name, index=None, header=None)
analyse方法,接受一个列表对象,即在数据整理部分得到的数据将数据创建为 DataFrame,利用 pandas 的 value_counts方法对对应字段数据进行统计,注意,value_counts会做去重处理,从而统计出每个值出现的个数因为 value_counts处理的结果,是一个 Series 对象,索引为不重复的值,所以在用 reset_index 方法处理一下,将索引转换为一个正常列,并对列名做了替换,以便后续处理更方便由于 value_counts 后的结果是按统计数量从多到少排列的,对应按时间的统计有些奇怪,所以利用 sort_values方法,按时间列做了重新排序to_excel方法是为了将数据导出为 excel,可以支持导入不同 sheet,以便做数据展示
四、数据展示
https://github.com/TurboWay/bigdata_practice.gitgit clone https://github.com/TurboWay/bigdata_practice.git
bigdata_practice 文件夹中,有个 requirements.txt,里面列了项目所依赖的库和组件关于如何构建 requirements.txt 文件,可参考 《部署 Flask 应用》
bigdata_practice 文件夹,用 pip 安装依赖:pip install -r requirements.txt
注意:最好使用虚拟环境安装,如何创建虚拟环境,可参考这篇文章
python app.py
* Serving Flask app "app" (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: on
* Restarting with stat
* Debugger is active!
* Debugger PIN: 137-055-644
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
localhost:5000,查看数据展示效果app.py 为 Flask 服务主代码,其中定义了系统的访问路径,比如首页、线图、饼图等,这里可以根据自己的需求添加或删改data.py 定义了展示数据的读取接口,相当于一个数据层,依赖于 nginx_log_data.py,将数据设置为,方便展示的结构,如果需要展示更多的图形,需要根据展示效果,修改或添加新的数据接口nginx_log_data.py 从 Excel 文件中读取需要展示的数据,Excel 中的数据,就是 数据分析 部分得到的结果,这里利用 pandas 读取 Excel 的功能,如果需要展示更多的分析数据,可以在这里添加数据读取结果,另外通过调整 data.py 以及相应的页面模板文件,将数据得以展示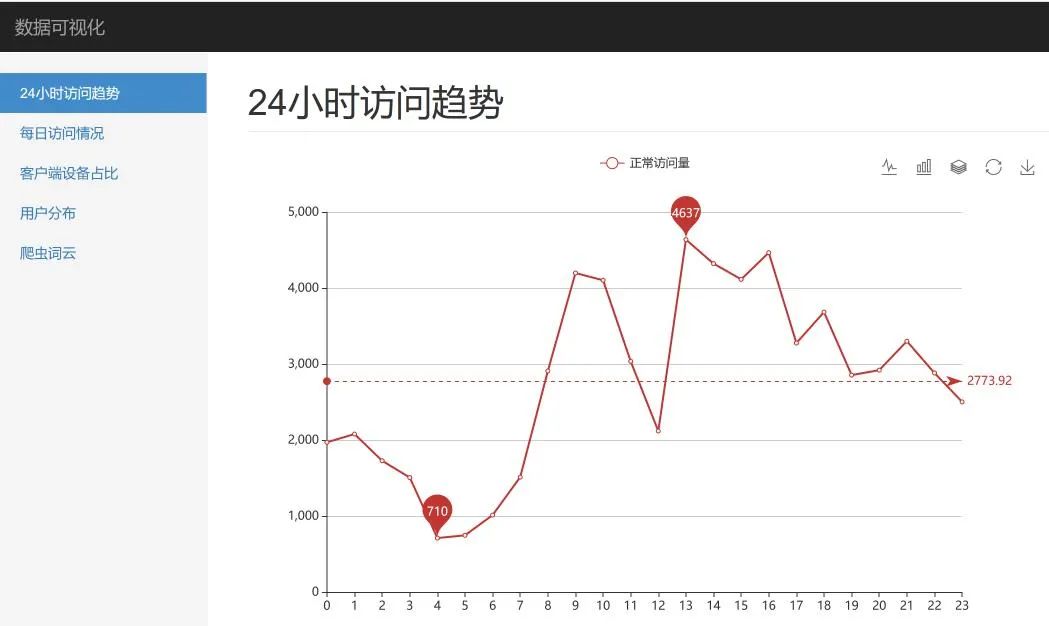
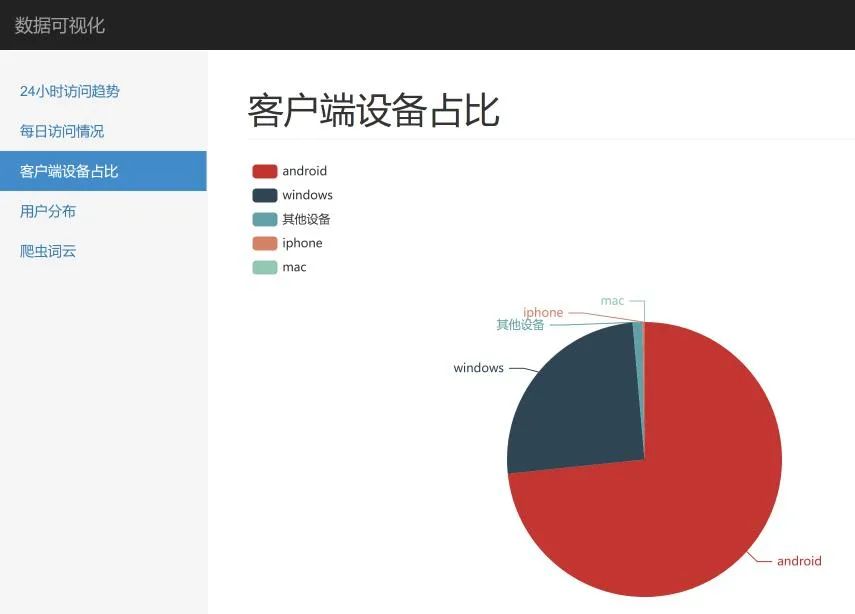
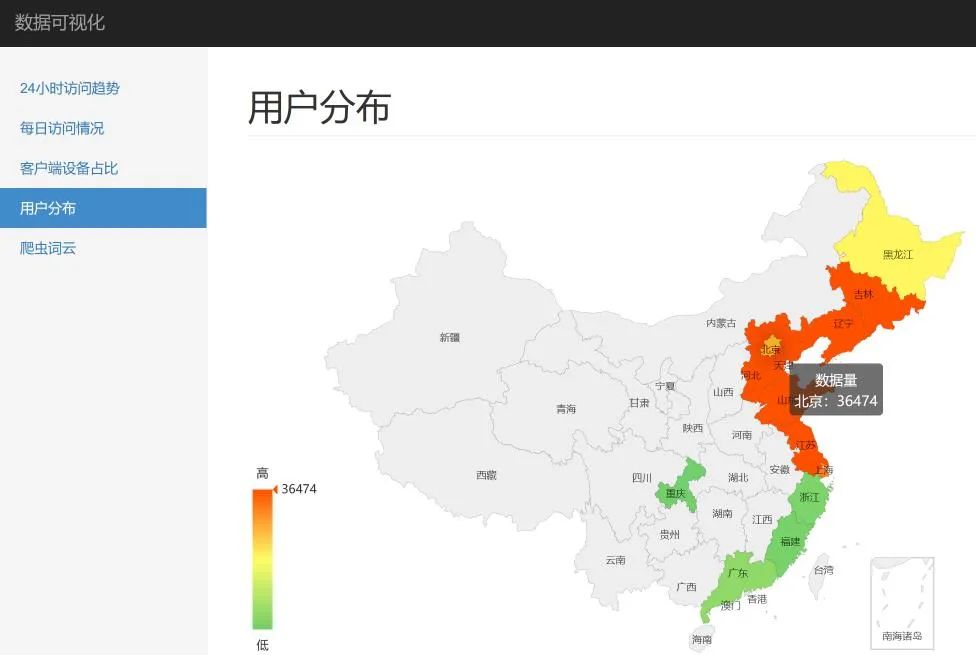
五、如何白嫖
pip install -r requirements.txt
python .\analyse\main.py
python .\ironman\app.py
六、总结
参考
https://www.cnblogs.com/ssgeek/p/12119657.html https://blog.csdn.net/whaoxysh/article/details/22295317 http://lbsyun.baidu.com/index.php?title=webapi/ip-api http://lbsyun.baidu.com/apiconsole/key https://blog.csdn.net/unsterbliche/article/details/80578606 https://github.com/TurboWay/bigdata_practice
评论