
Flask + echarts 轻松搞定 日志可视化


最近,线上的业务系统不太稳定,需要分析下访问情况,能拿到的数据只有 nginx 服务器的访问日志,不过难不倒我,用合适的工具,分分钟做出图形化展示,看看怎么做的吧
思路
nginx 访问日志,记录了每次客户端请求,其中包括 ip、时间、使用的客户端等信息
通过解析每行数据,提取这些信息,然后对信息进行整理,并做一些必要的统计
最后将统计数据展示出来,可以直观地感知数据中蕴含的问题
基本思路就是这样,不过知道和做到之间地距离还有很远,为了达到目标,需要一些工具做支持
由于数据是 nginx 访问日志,所有不需要爬取,从服务器上下载就好
整理处理过程,除了 python 本身一些功能外,还离不开 pandas 的支持
最后数据展示部分,用的是 Flask + echarts,从头写,确实很有挑战,不过今天我们利用 TurboWay 同学的框架 bigdata_practice,就能轻松搞定
闲话少叙,开始吧
数据处理
下载到 nginx 访问日志,从 nginx 配置文件中可以查看日志存放地址,另外,本文源码中有附带示例日志文件,可下载使用
日志文件为文本文件,每行记录一条访问情况,例如:
124.64.19.27 - - [04/Sep/2020:03:21:12 +0800] "POST /api/hb.asp HTTP/1.1" 200 132 "http://erp.example.com/mainframe/main.html" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36" "-"
读取文本文件的行,实现比较简单,这里只对提取字段和通过 ip 确定省份做下说明
提取
提取字段的方法如下:
import re
obj = re.compile(r'(?P.*?)- - \[(?P )
result = obj.match(line)
# print(result.group("time"))
# ip处理
ip = result.group("ip").split(",")[0].strip() # 如果有两个ip,取第一个ip
# 状态码处理
status = result.group("status") # 状态码
# 时间处理
time = result.group("time").replace(" +0800", "") # 提取时间,并去掉时区信息
t = datetime.datetime.strptime(time, "%d/%b/%Y:%H:%M:%S") # 格式化
# request处理
request = result.group("request")
a = request.split()[1].split("?")[0] # 提取请求 url,去掉查询参数
# user_agent处理
ua = result.group("ua")
if "Windows NT" in ua:
u = "windows"
elif "iPad" in ua:
u = "ipad"
elif "Android" in ua:
u = "android"
elif "Macintosh" in ua:
u = "mac"
elif "iPhone" in ua:
u = "iphone"
else:
u = "其他设备"
# refer处理
referer = result.group("referer")
代码看着长,其实逻辑很简单,核心是提取信息的正则表达式,利用了命名分组的方式,匹配后,可以通过命名来提取数据
对提取出的数据,需要处理一下,比如请求时间,采用的是类似 UTC 时间格式,需要去掉时区,并转换为 datatime 类型
另外就是的客户端的处理,根据关键字,判断客户端类型
将提取的信息,存入一个 词典 对象中,即每行对于一个 词典 对象,最后将一个个对象追加到一个 列表 对象中,带进一步处理
获取用户省份
为了后面对访问者所在区域进行分析,需要对一些字段做处理,例如将 ip 转换为省份信息
转换主要利用的是百度的 ip 定位服务
百度的 ip 定位服务,通过认证,可以获得每日 3 万次的免费配额
通过提供的 api 可以获取 ip 地址所在的省名称
考虑到查询效率和配额限制问题,最好对 ip 定位的结果做个缓存:
import requests
import os
ak = "444ddf895 ... a5ad334ee" # 百度 ak 需申请
# ip 定位方法
def ip2province(ip):
province = ipCache.get(ip, None)
if province is None:
url = f"https://api.map.baidu.com/location/ip?ak={ak}&ip={ip}&coor=bd09ll"
try:
province = json.loads(requests.get(url).text)['address'].split('|')[1]
ipCache[ip] = province
# 这里就需要写入
with open("ip_cache.txt","a") as f:
f.write(ip + "\t" + province + "\n")
return province
except Exception as e:
return "未知"
else:
return province
# 初始化缓存
ipCache = {}
if os.path.exists("ip_cache.txt"):
with open("ip_cache.txt", "r") as f:
data = f.readline()
while data:
ip, province = data.strip().split("\t")
ipCache[ip] = province
data = f.readline()
首先需要申请一个百度 app key 合成请求,通过 requests get,得到响应,从中提取到 ip 对应的省份信息 对应地址缓存,将没有缓存的结果存入 ipCache 词典对象,并写入 ip_cache.txt 文件,下次启动时,用缓存文件中的内容初始化 ipCache 词典对象 在每次需要获取 ip 对应地址时,先检查缓存,如果没有才通过 api 获取
数据分析
数据分析,就是对提取到的特征数据做统计加工,利用的是强大的 pandas
通过数据处理过程,我们可以得到处理好的 列表 对象,列表对象很容易创建为 pandas 的 DataFrame
接着,利用 pandas 的统计功能,将原始数据转换为可以展示用的分析数据
最后将数据存入 Excel 文件
def analyse(lst):
df = pd.DataFrame(lst) # 创建 DataFrame
# 统计省份
province_count_df = pd.value_counts(df['province']).reset_index().rename(columns={"index": "province", "province": "count"})
# 统计时段
hour_count_df = pd.value_counts(df['hour']).reset_index().rename(columns={"index": "hour", "hour": "count"}).sort_values(by='hour')
# 统计客户端
ua_count_df = pd.value_counts(df['ua']).reset_index().rename(columns={"index": "ua", "ua": "count"})
# 数据存储
to_excel(province_count_df, 'data.xlsx', sheet_name='省份')
to_excel(hour_count_df, 'data.xlsx', sheet_name='按时')
to_excel(ua_count_df, 'data.xlsx', sheet_name='客户端')
def to_excel(dataframe, filepath, sheet_name):
if os.path.exists(filepath):j
excelWriter = pd.ExcelWriter(filepath, engine='openpyxl')
book = load_workbook(excelWriter.path)
excelWriter.book = book
dataframe.to_excel(excel_writer=excelWriter,sheet_name=sheet_name,index=None, header=None)
excelWriter.close()
else:
dataframe.to_excel(filepath, sheet_name=sheet_name, index=None, header=None)
analyse方法,接受一个列表对象,即在数据整理部分得到的数据将数据创建为 DataFrame,利用 pandas 的 value_counts方法对对应字段数据进行统计,注意,value_counts会做去重处理,从而统计出每个值出现的个数因为 value_counts处理的结果,是一个 Series 对象,索引为不重复的值,所以在用 reset_index 方法处理一下,将索引转换为一个正常列,并对列名做了替换,以便后续处理更方便由于 value_counts 后的结果是按统计数量从多到少排列的,对应按时间的统计有些奇怪,所以利用 sort_values方法,按时间列做了重新排序to_excel方法是为了将数据导出为 excel,可以支持导入不同 sheet,以便做数据展示
数据分析部分,可以从不同的角度对数据进行统计分析,最终将需要展示的数据存入 Excel,当然根据需要也可以存入其他数据库
数据展示
从头利用 Flask 和 echarts 做数据展示是可以的,不过需要处理更多的细节
如果利用一些框架,快速做展示,然后再做局部的个性化调整
这里用到的框架是 TurboWay 的 bigdata_practice,虽然功能比较单一,结构不太灵活,不过用来搭建一个可用的数据展示系统还是没问题的,重要的是可以通过源码学习构建思路的方法
bigdata_practice git 地址为:https://github.com/TurboWay/bigdata_practice.git
将其 clone 到本地
git clone https://github.com/TurboWay/bigdata_practice.git
然后按照依赖模块,在 bigdata_practice 文件夹中,有个 requirements.txt,里面列了项目所依赖的库和组件
关于如何构建 requirements.txt 文件,可参考 《部署 Flask 应用》
进入 bigdata_practice 文件夹,用 pip 安装依赖:
pip install -r requirements.txt
注意:最好使用虚拟环境安装,如何创建虚拟环境,可参考这篇文章
安装依赖之后,就可以启动 Flask 服务了
python app.py
* Serving Flask app "app" (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: on
* Restarting with stat
* Debugger is active!
* Debugger PIN: 137-055-644
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
如果一切正常,可以访问 localhost:5000,查看数据展示效果
这里对项目中的需要定制的部分做下说明
在 ironman 目录下,app.py 为 Flask 服务主代码,其中定义了系统的访问路径,比如首页、线图、饼图等,这里可以根据自己的需求添加或删改
每个访问路径对应一个页面模板,模板文件存放在,templates 文件夹下,如果需要调整菜单,需要对每个模板页面中的菜单部分进行修改,以调整菜单项目以及被激活的菜单
data.py 定义了展示数据的读取接口,相当于一个数据层,依赖于 nginx_log_data.py,将数据设置为,方便展示的结构,如果需要展示更多的图形,需要根据展示效果,修改或添加新的数据接口
nginx_log_data.py 从 Excel 文件中读取需要展示的数据,Excel 中的数据,就是 数据分析 部分得到的结果,这里利用 pandas 读取 Excel 的功能,如果需要展示更多的分析数据,可以在这里添加数据读取结果,另外通过调整 data.py 以及相应的页面模板文件,将数据得以展示
这里,我们就 24小时访问趋势、客户端占比以及用户分布做了展示,效果如下:
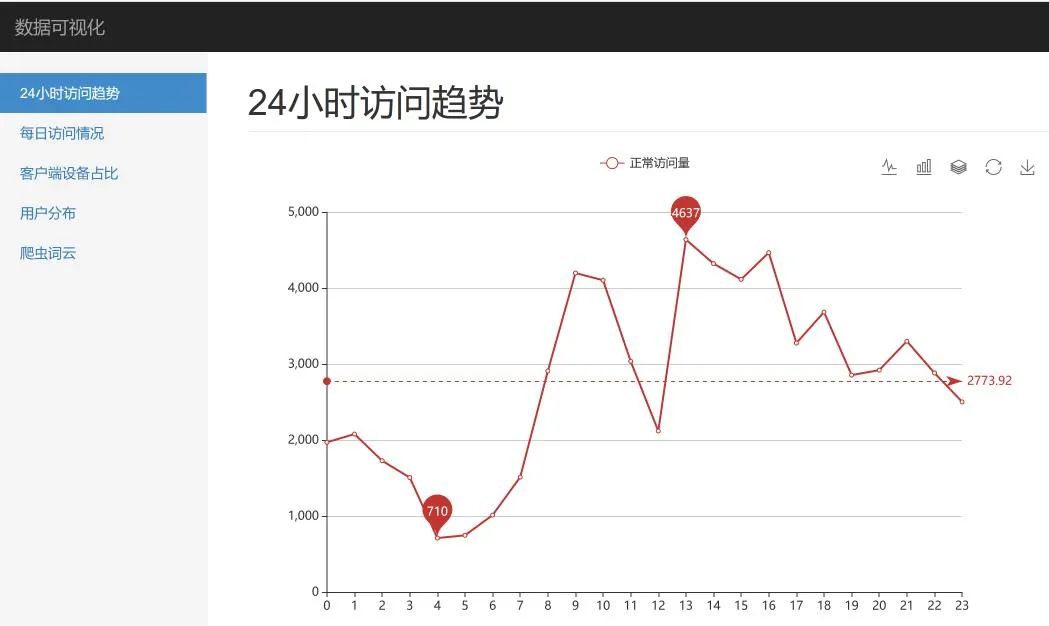
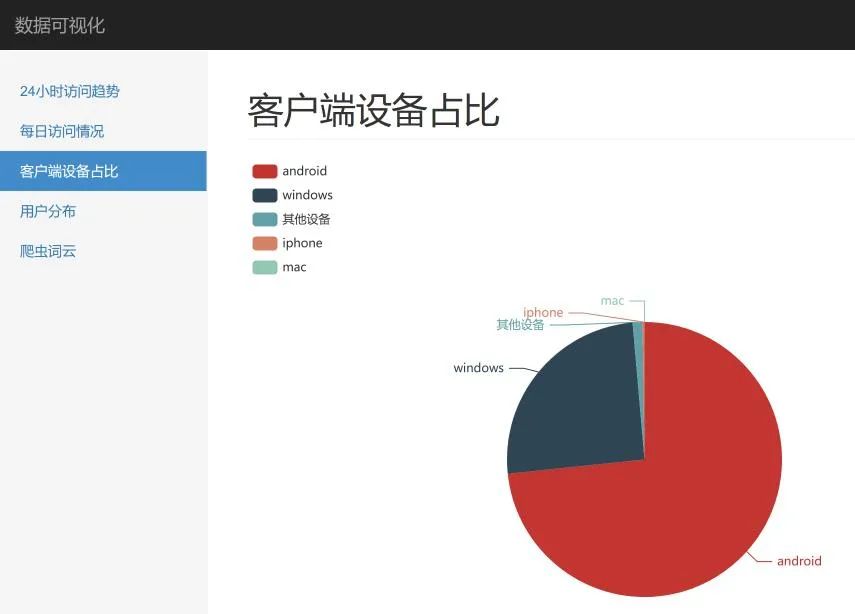
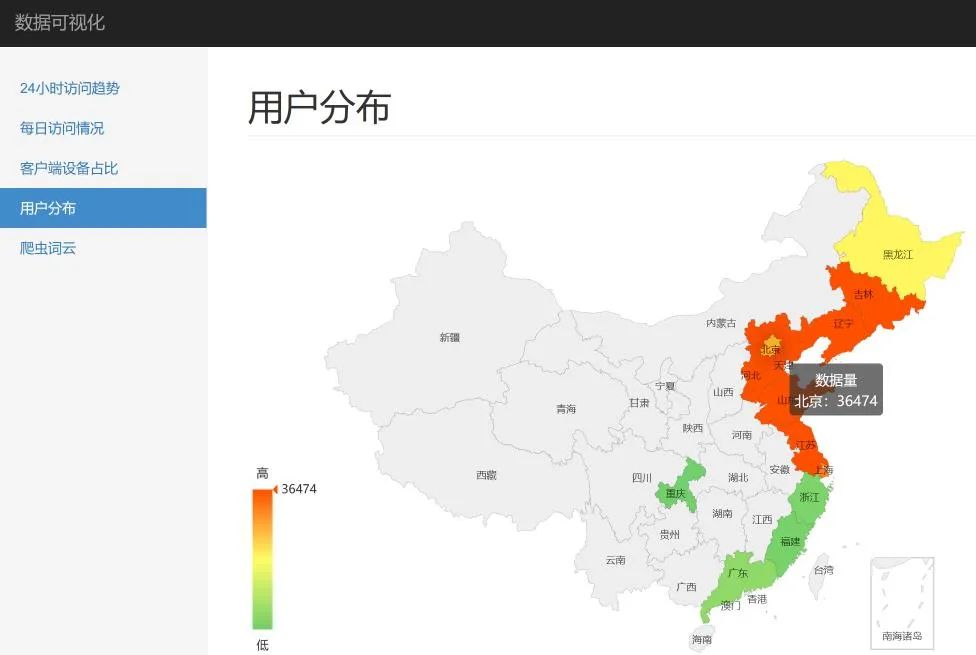
实践
下载源码后,先安装项目依赖
pip install -r requirements.txt
示例用的 nginx 访问日志,在 nginx_access.zip 压缩包里,先解压到当前目录
然后申请百度API,获取到 ak,修改到 analyse\baidu_api.py 的 13 行
将命令行切换到代码目录下,否则可能出现文件找不到的错误
执行数据分析脚本:
python .\analyse\main.py
最后启动 Flask 服务:
python .\ironman\app.py
总结
今天利用 pandas、Flask、echarts 对 nginx 服务器的访问日志做了简单分析和展示,完成任务的同时,学习和实践了如何通过一些简单的工具和方法构造一个数据展示平台的过程
文章主要说明了构建思路和需要注意的部分,具体细节,请下载示例代码,运行,同时欢迎交流探讨
参考
https://www.cnblogs.com/ssgeek/p/12119657.html https://blog.csdn.net/whaoxysh/article/details/22295317 http://lbsyun.baidu.com/index.php?title=webapi/ip-api http://lbsyun.baidu.com/apiconsole/key https://blog.csdn.net/unsterbliche/article/details/80578606 https://github.com/TurboWay/bigdata_practice
