
刚刚,微软和谷歌在SuperGLUE榜单上暴锤人类!OpenAI用「字生图」只是前菜

新智元报道
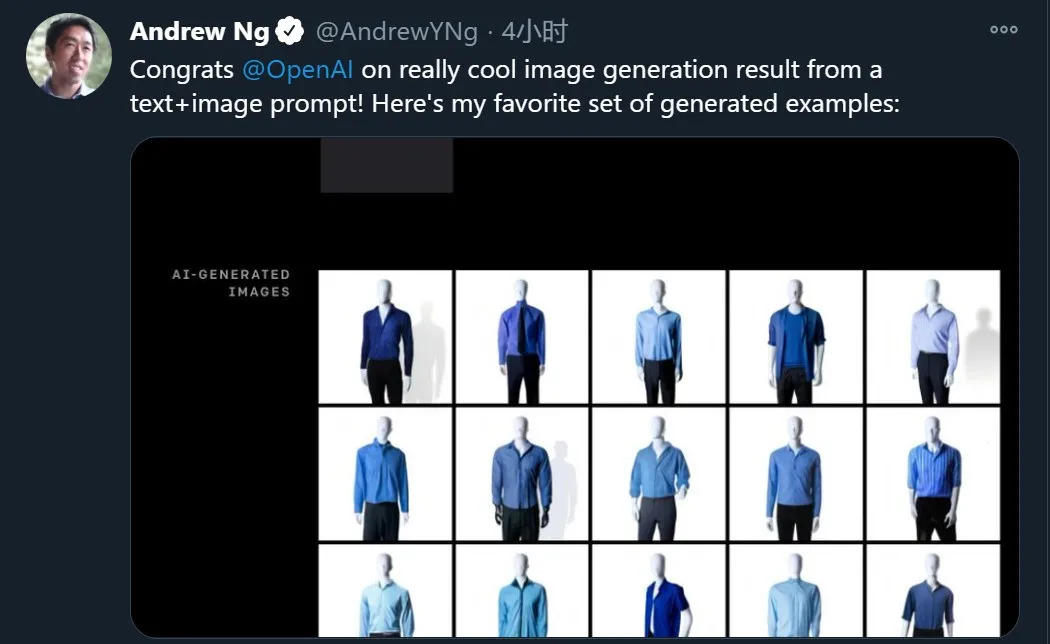
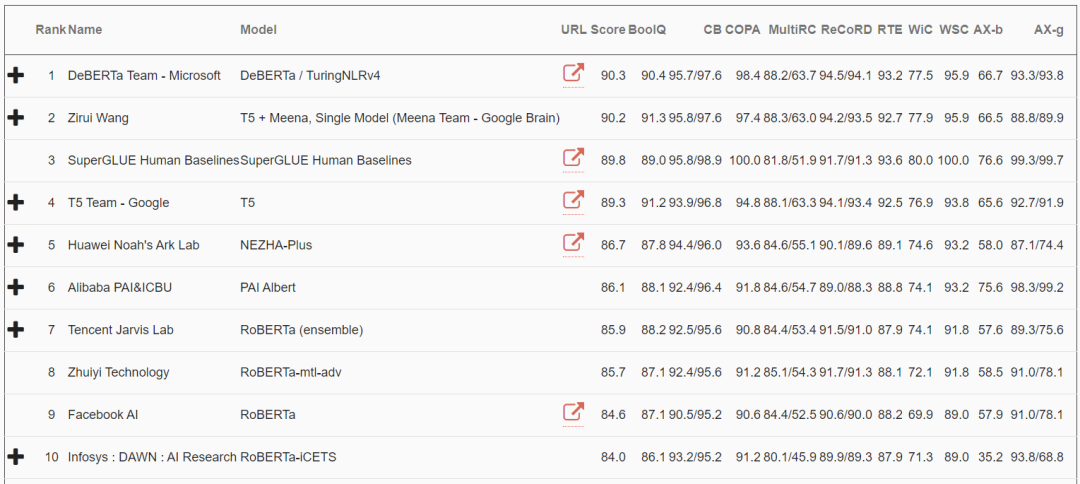
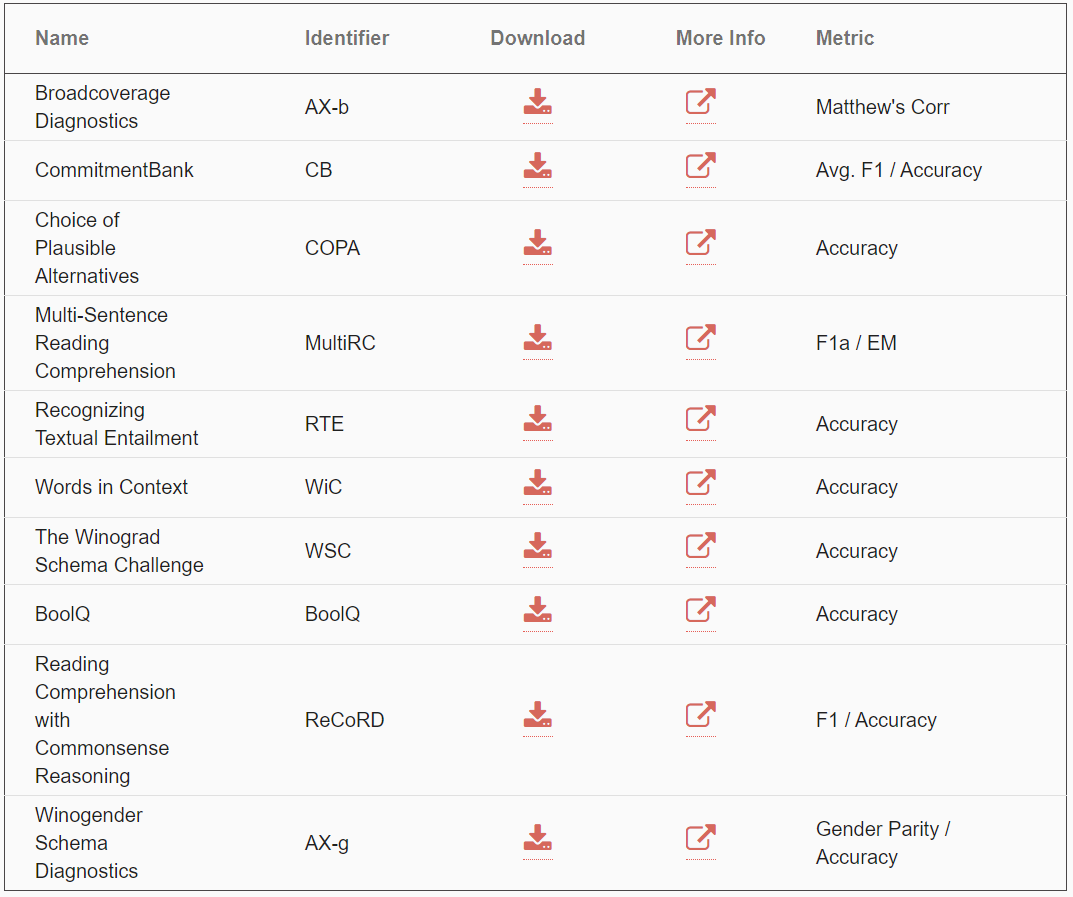
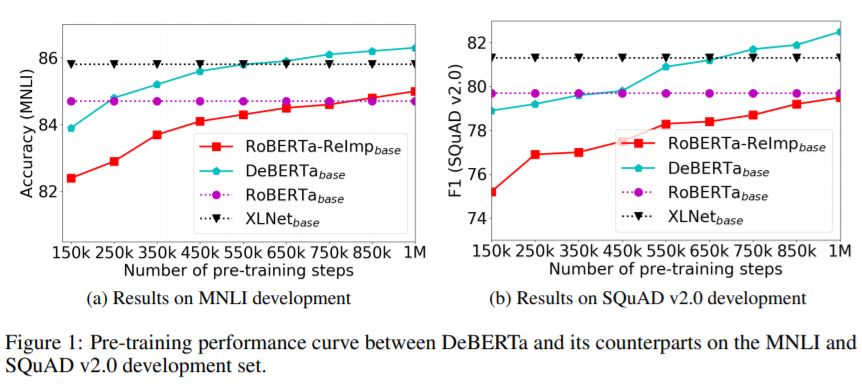
【新智元导读】还在为OpenAI的DALL-E 和 CLIP所惊艳?在刚刚刷新的SuperGLUE上,微软的DeBERTa和谷歌的T5+Meena分列第一第二,超越人类基准线,这是SuperGLUE引入以来,AI首次得分超过了人类的表现。难道说2021,AI正在加快缩小与人类的差距?









https://venturebeat.com/2021/01/06/ai-models-from-microsoft-and-google-already-surpass-human-performance-on-the-superglue-language-benchmark/


评论