
pandas 1.3版本主要更新内容一览
1 简介
就在几天前,pandas发布了其1.3版本,在这次新的版本中添加了诸多实用的新特性,今天的文章我们就一起来get其中主要的一些内容更新~

2 pandas 1.3主要更新内容一览
使用pip install pandas==1.3.0 -U -i https://pypi.douban.com/simple/安装1.3版本后,下面我们来看看新的版本给我们带来了哪些新特性:
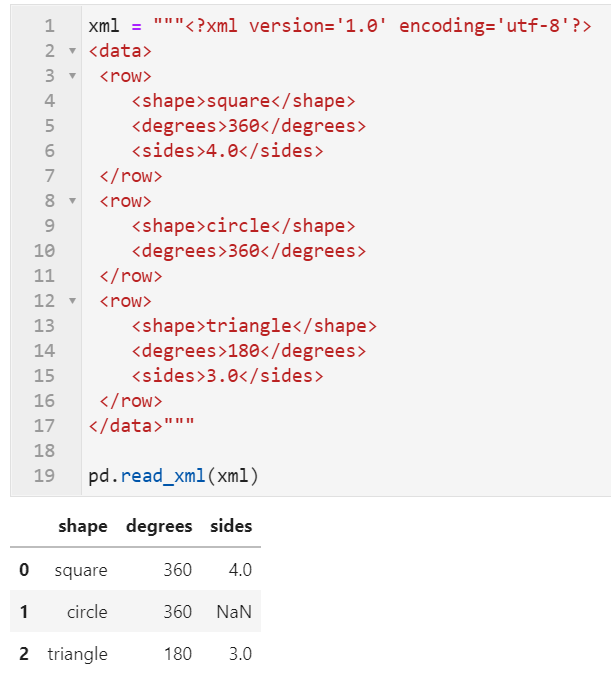
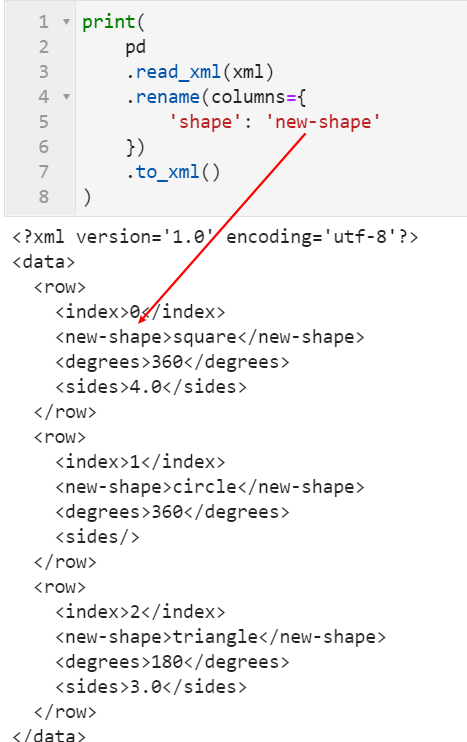
2.1 新增对xml文件的读写操作
在这次新版本中新增了对xml格式数据进行解析读写的功能,对此有特殊需求的朋友可以前往https://pandas.pydata.org/docs/user_guide/io.html#xml详细了解:
2.2 Styler可使用原生css语法
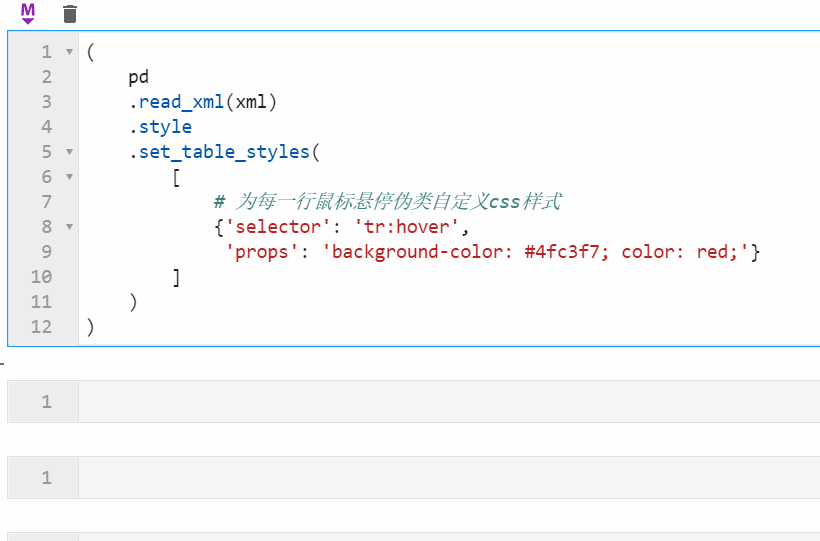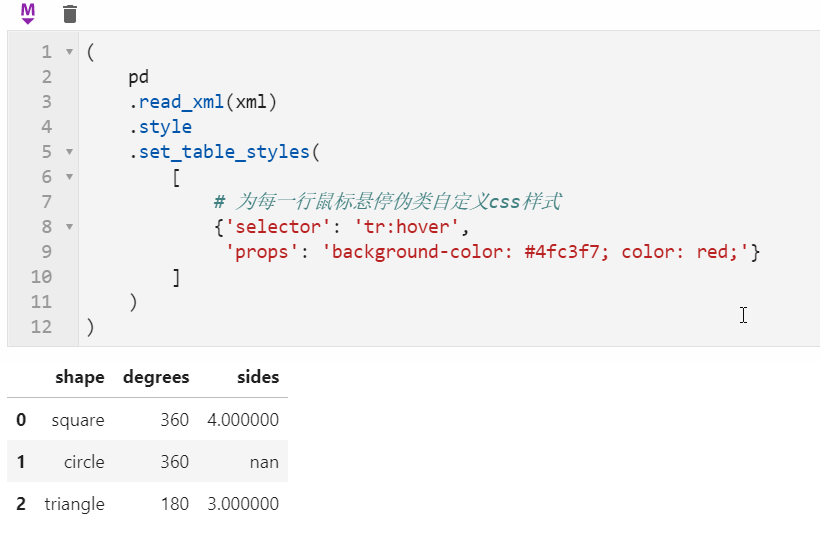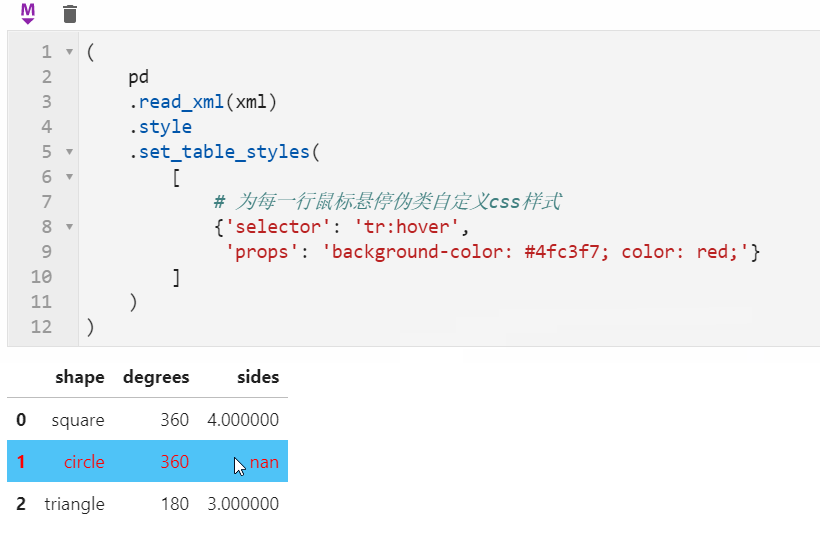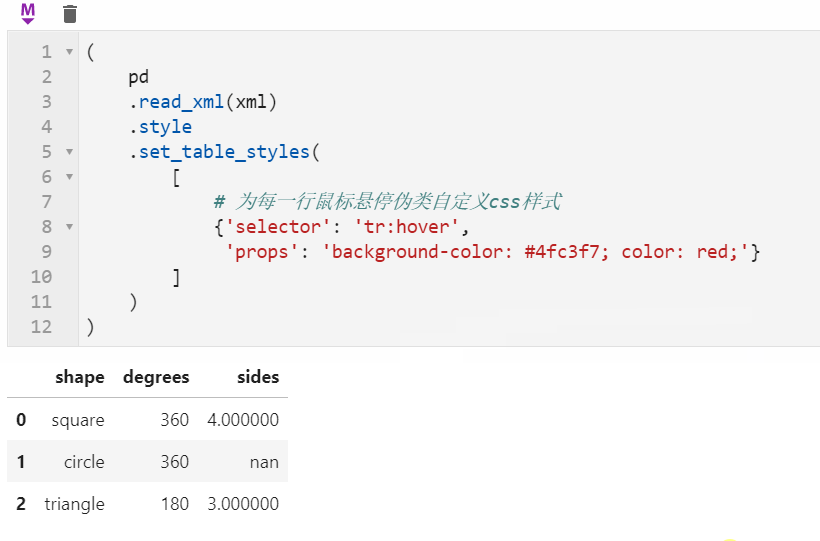
很多朋友都知道pandas中可以配合Styler对数据框进行自定义样式输出,其中最自由的是通过Styler.set_table_styles()来自定义css样式,以前的方式需要将一条css属性写到二元组中传入,在1.3版本中可以直接传入css字符串,比如下面我们通过设置hover伪类样式,来修改每一行鼠标悬停时的样式:
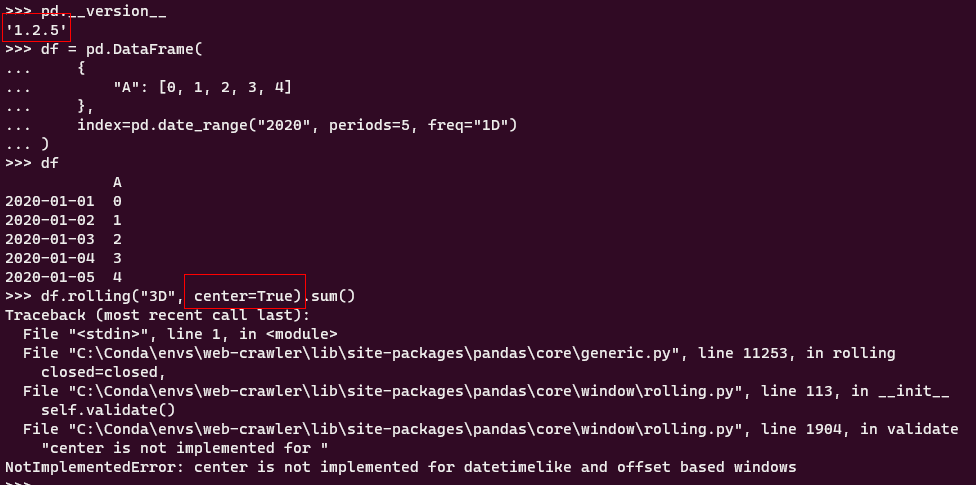
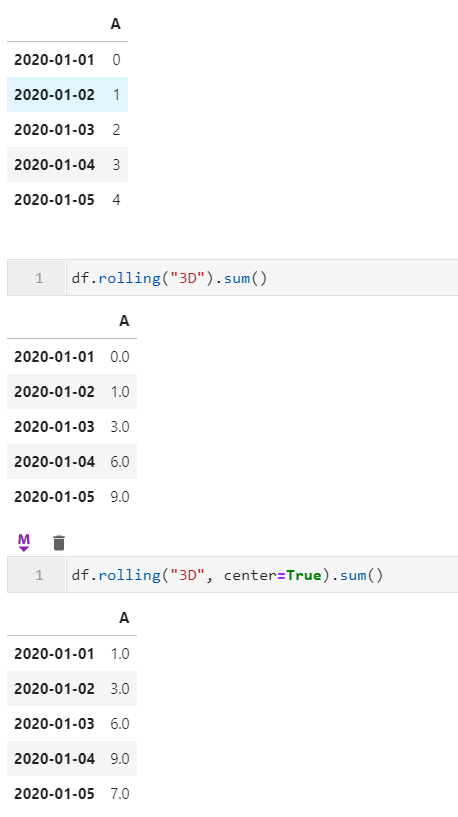
2.3 center参数在时间日期index的数据框rolling操作中可用
在先前的版本中,如果针对行索引为时间日期型的数据框进行rolling滑窗操作使用center参数将每行记录作为窗口中心时会报错:
而在1.3中这个问题终于得到解决~方便了许多时序数据分析时的操作:
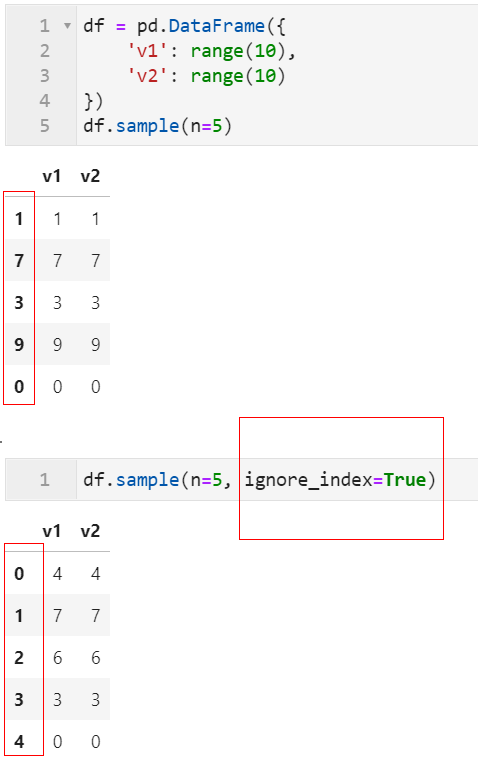
2.4 sample()随机抽样新增ignore_index参数
我们都知道在pandas中可以使用sample()方法对数据框进行各种放回/不放回抽样,但以前版本中抽完样的数据框每行记录还保持着先前的行索引,使得我们还得多一步reset_index()操作,而在1.3中,新增类似sort_values()和drop_duplicates()中的同名参数ignore_index:
2.5 explode()新增多列操作支持
当数据框中某些字段某些位置元素为列表、元组等数据结构时,我们可以使用explode()方法来基于这些序列型元素进行展开扩充,但在以前的版本中每次explode()操作只支持对单个字段的展开,如果数据中多个字段之间同一行对应序列型元素位置是一一对应的,需要展开后也是一一对应的,操作起来就比较棘手。
而1.3版本中直接对多字段同步explode()进行了支持:

2.6 append模式下写出多工作表excel文件的新策略
在1.3版本中,针对mode='a'模式下向外写出多工作表excel文件,新增了参数if_sheet_exists来设定新工作表与已存在工作表重名时的处理策略,默认为'error'即直接抛出错误,'new'则会自动修改工作表名,'replace'则会覆盖原同名工作表:

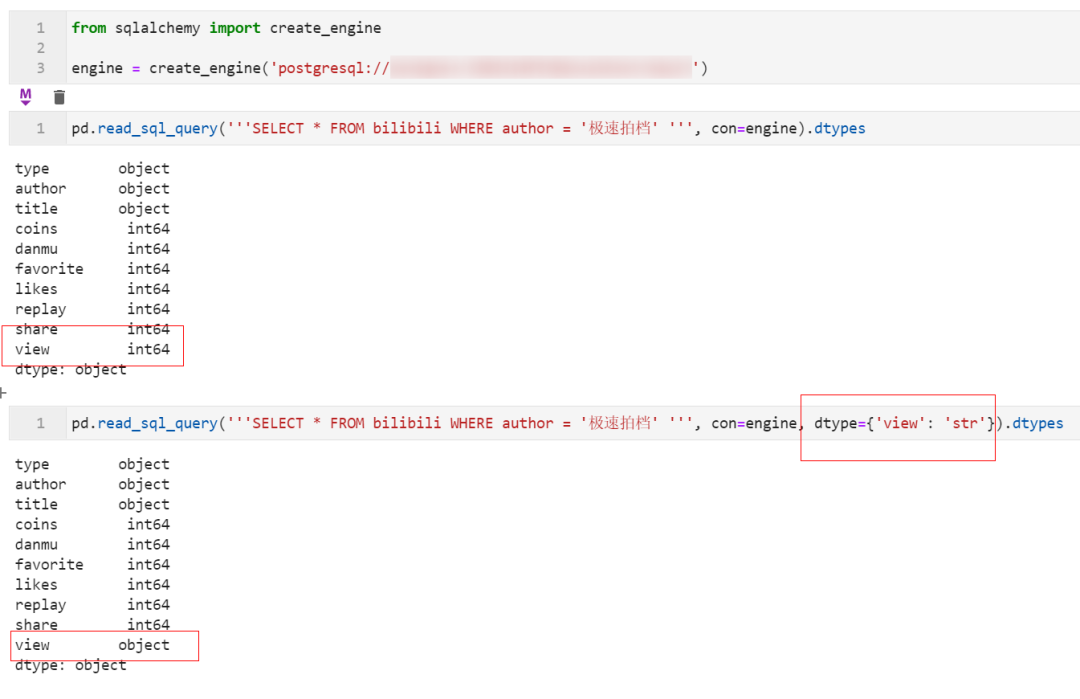
2.7 结合SQL读取数据库表时可直接设置类型转换
在1.3版本中,我们在使用read_sql_query()结合SQL查询数据库时,新增了参数dtype可以像在其他API中那样一步到位转换查询到的数据:
以上就是本文的全部内容,欢迎在评论区与我进行讨论~
相关阅读: