
geopandas 0.10版本重磅新特性一览

添加微信号"CNFeffery"加入技术交流群
❝本文示例代码及文件已上传至我的
❞Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
1 简介
就在前不久,我们非常熟悉的Python地理空间分析库geopandas更新到了0.10.0版本,而伴随最近一段时间其针对新版本的一些潜在bug进行的修复,写作本文时最新的正式版本为0.10.2。此次0.10.x版本为我们带来了诸多令人兴奋的新功能新特性,本文就将带大家一睹其中一些比较重要的内容😋。

2 geopandas 0.10版本重要新特性一览
如果你已经安装了旧版本的geopandas,那么推荐执行下列命令进行geopandas的更新:
conda update geopandas -c https://mirrors.sjtug.sjtu.edu.cn/anaconda/cloud/conda-forge -y
而如果你还没有安装geopandas,那么下面的安装方式是最稳妥的:
conda install geopandas=0.10.2 -c https://mirrors.sjtug.sjtu.edu.cn/anaconda/cloud/conda-forge -y
pip uninstall rtree -y
pip install rtree -i https://pypi.douban.com/simple/
pip install pygeos -i https://pypi.douban.com/simple/
安装/更新完成后,检验一下geopandas是否被正确安装:
下面我们就来看看这次版本更新中有哪些重要新变动吧~
2.1 新增空间最近连接方法sjoin_nearest()
我们都知道利用geopandas中的sjoin(),可以完成基于多种空间拓扑关系的「空间连接」操作。
但有些时候我们需要判断的并不是左右两表中矢量列相交、包含等直接的「拓扑关系」,而是左右两表矢量列之间「距离至多xx米」这类的空间距离关系判断,这在旧版本的geopandas中,通常可以左右两边分别做「缓冲区」后进行「常规空间连接」来实现。
而这次新增的sjoin_nearest()就可以支持我们开展上述分析计算功能,它的主要参数有:
「left_df」:连接对应的左 GeoDataFrame「right_df」:连接对应的右 GeoDataFrame「how」:设置连接方式,可选的有 'left'、'right'及'inner',默认为'inner'「max_distance」:重要参数,用于设置最大搜索距离阈值,当矢量间的距离小于此阈值时才会进行连接 「lsuffix」:设置左表重名字段后缀文字,默认为 'left'「rsuffix」:设置右表重名字段后缀文字,默认为 'right'「distance_col」:设置连接结果表中记录对应矢量间距离的字段名称,默认不设置时不会在结果表中添加距离信息
下面我们来通过一个简单的例子来体验这个功能:
import geopandas as gpd
from shapely.geometry import Point
# 构造示例点要素表1
gdf1 = gpd.GeoDataFrame(
{
'id1': list('abc'),
'geometry': [
Point(0, 0),
Point(1, 0),
Point(-1, 0)
]
}
)
# 构造示例点要素表2
gdf2 = gpd.GeoDataFrame(
{
'id2': list('def'),
'geometry': [
Point(0.4, 0),
Point(1.2, 0),
Point(-1.3, 0)
]
}
)
ax = gdf1.plot(color='red')
ax = gdf2.plot(color='green', ax=ax)
ax.axis('equal');
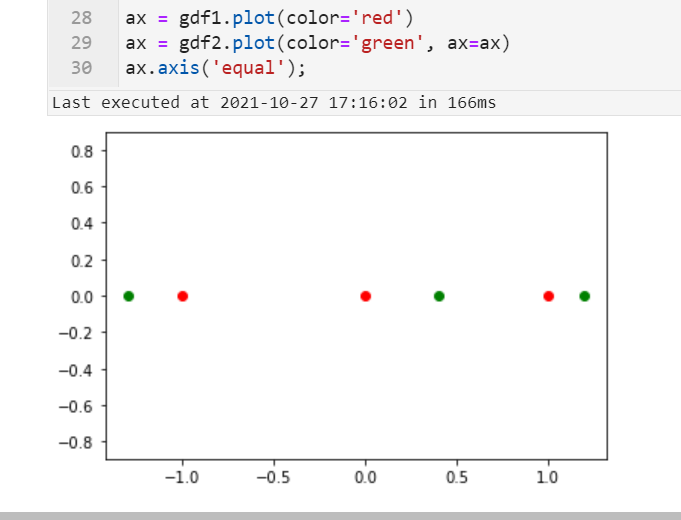
颜色即用来区分我们的左右表对应矢量点位置,下面直接运用sjoin_nearest()进行空间最近连接,设置的距离阈值为0.35:
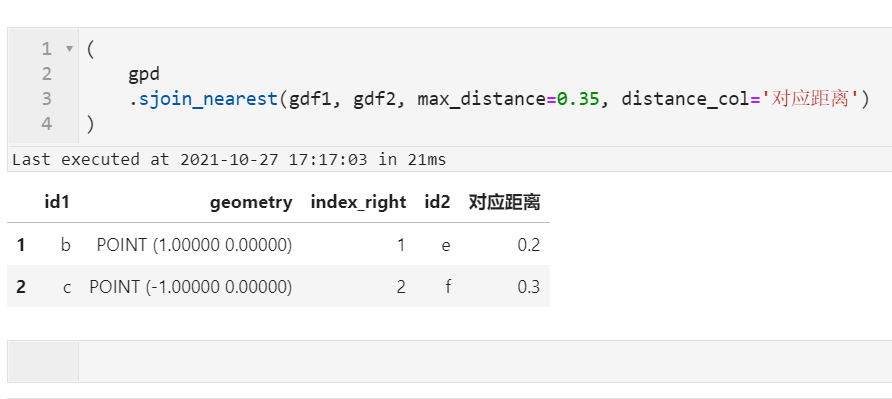
(
gpd
.sjoin_nearest(gdf1, gdf2, max_distance=0.35, distance_col='对应距离')
)
非常的方便快捷:
2.2 新增交互地图式数据探索方法explore()
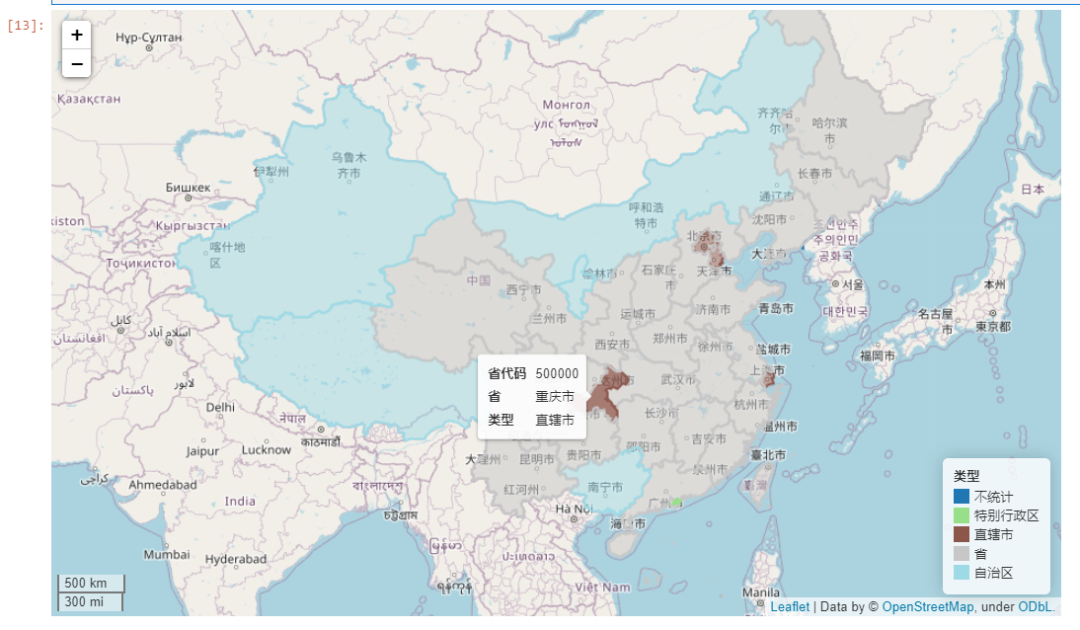
很多人都知道著名的在线地图可视化组件leaflet在Python中有对应的库folium,而在这次新版本中,geopandas为GeoDataFrame及GeoSeries对象新增交互式地图可视化方法explore(),你可以理解为交互式版本的plot()方法。
其参数设置较为丰富,我之后会单独写一篇文章来为大家介绍,下面展示一个简单易懂的例子(注意,如果你的矢量数据非常大,请「不要」用此方法绘图,在线地图方式适合较小的矢量数据):
provinces = gpd.read_file('省.shp')
provinces.head(3)
...
provinces.explore(
column='类型',
zoom_start=4
)
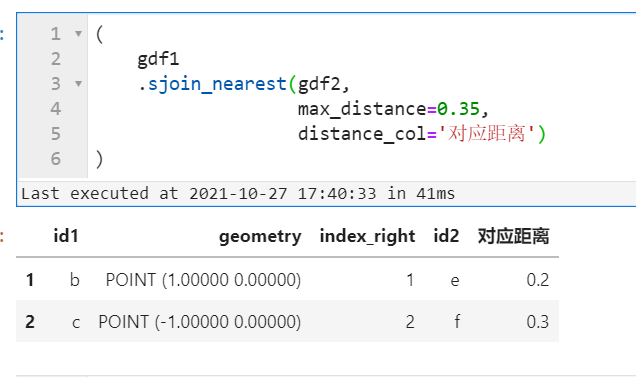
2.3 sjoin()、sjoin_nearest()、overlay()和clip()亦可作为GeoDataFrame的方法来使用
在以前的版本中,我们只能使用gpd.XXX()的方式来使用sjoin()、overlay()、clip()等方法,而在这次新版本更新中,我们可以像pandas里的merge()、join()那样作为方法使用,好处就是可以更好的书写链式运算过程啦🥳!以上文介绍的sjoin_nearest()为例,只需向sjoin_nearest()方法中传入右表即可:
(
gdf1
.sjoin_nearest(gdf2,
max_distance=0.35,
distance_col='对应距离')
)
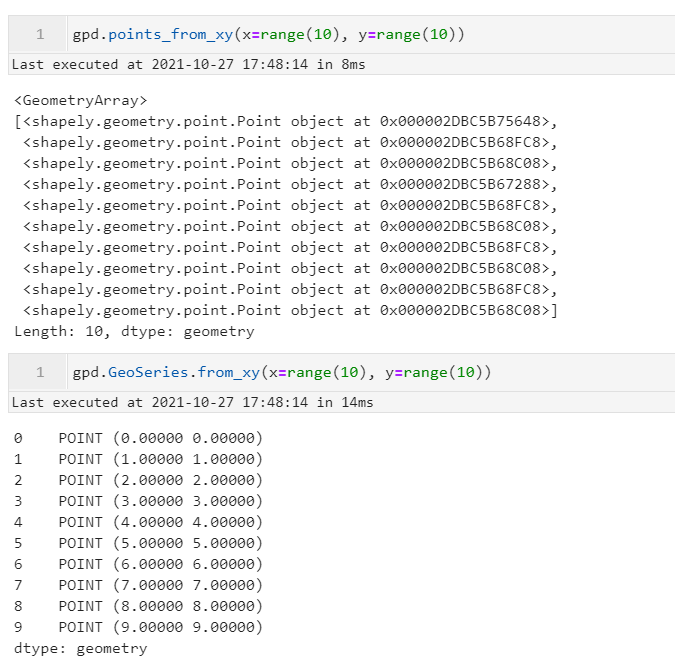
2.4 GeoSeries新增批量XY转点方法from_xy()
新版本中为GeoSeries对象新增了from_xy()方法来快速实现坐标转点,下面与gpd.points_from_xy()的效果进行对比:
gpd.points_from_xy(x=range(10), y=range(10))
...
gpd.GeoSeries.from_xy(x=range(10), y=range(10))
2.5 to_file()方法在driver参数缺省时可自动识别导出文件类型
在新版本中,若未在to_file()中指定driver参数,geopandas会自动根据文件后缀名来自动推断要导出的矢量文件类型:
import os
gdf1.to_file('test.shp')
gdf1.to_file('test.geojson')
[file for file in os.listdir() if 'test.' in file]

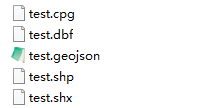
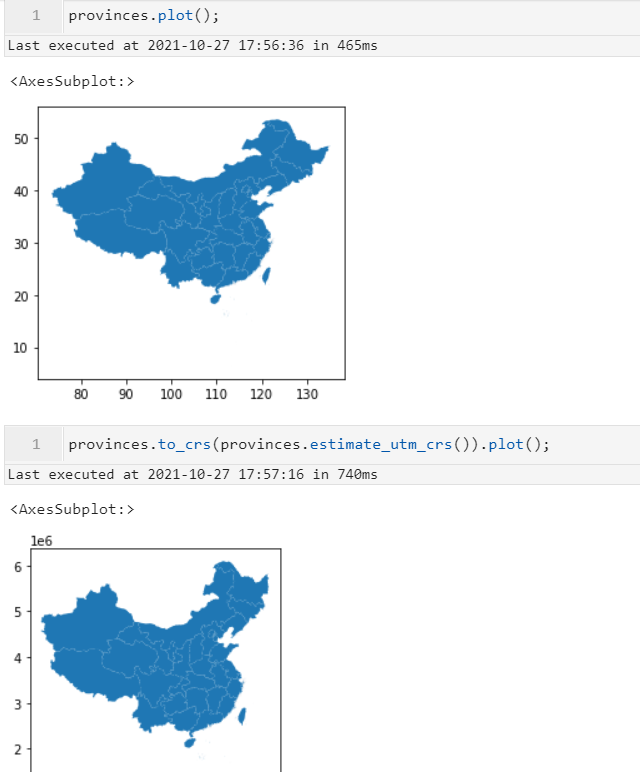
2.6 支持对矢量数据自动推断合适的横轴墨卡托坐标参考系
其实这个特性在0.9版本中就已加入,但是还有一些小问题,而新版本中这个功能更加完善,效果如下:
2.7 sjoin()中的op参数改名为predicate
为了让参数名更加的贴切,在以前版本sjoin()中用于设置拓扑关系的参数op在这次新版本中被改名为predicate,大家在使用时要留意:
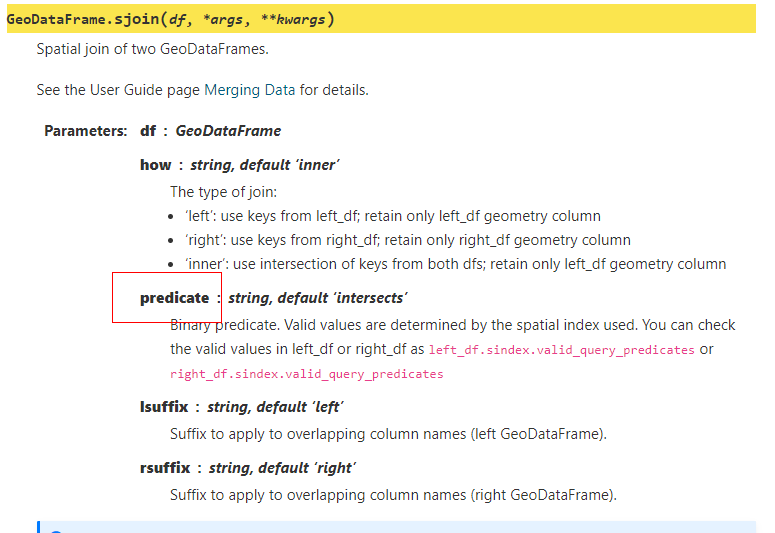
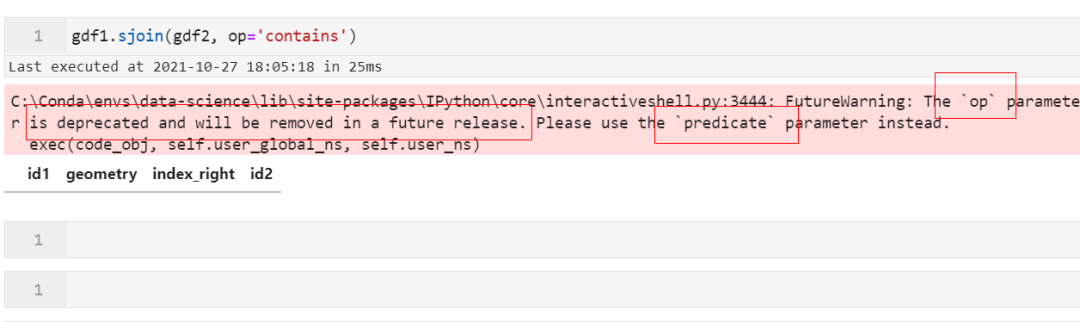
大家在了解到这些新功能和变动后,在使用新版geopandas时,如果遇到未知bug,欢迎在https://github.com/geopandas/geopandas/issues及时提交说明,一起帮助geopandas变得更加好用和完善😇。
以上就是本文的全部内容,欢迎在评论区与我进行讨论~
加入知识星球【我们谈论数据科学】
400+小伙伴一起学习!
· 推荐阅读 ·