
【CVPR2021】用于立体匹配的可学习双边网格
来源:3D视觉开发者社区
高精度的实时立体匹配网络是时下研究的一个热点,它在自动驾驶、机器人导航和增强现实等领域中有着广泛的应用。虽然近年来对立体匹配网络的研究已经取得了显著的成果,但要同时兼顾实时性和高精度仍然是一个挑战。现有的高精度立体匹配网络,通常需要在较高的分辨率建立代价空间。比如,GANet在1/3分辨率建立代价空间,PSMNet在1/4分辨率,但这会影响网络的效率(GANet处理一对1242×375的图像,需要1.8s,PSMNet需要0.41s)。
本文的动机是期望寻求一种解决方案:用高分辨率代价空间预测视差图,以保持高的精度,同时要保持高的计算效率。
[CVPR 2021] Bilateral Grid Learning for Stereo Matching Networks
徐彬1,徐玉华1,2,*,杨晓立1,贾伟2,郭裕兰3
( 1奥比中光,2合肥工业大学,3国防科技大学)
论文链接: https://arxiv.org/pdf/2101.01601.pdf
代码开源: https://github.com/3DCVdeveloper/BGNet
1.创新点
(1)本文提出一种新的基于可学习的双边网格的代价空间上采样模块(Cost volume Upsampling in the learned Bilateral Grid, CUBG)。基于这个具有边缘保持特性的上采样模块,通过无参数的切片层(slicing layer)可以高效地从低分辨率的代价空间获得高质量的高分辨率代价空间。这样,费时的代价聚合只需要在低分辨率执行。该模块能够无缝嵌入到许多现有的立体匹配网络(如GCNet,PSMNet,GANet等)中,在保持相当精度的条件下取得4-29倍的加速。据我们所知,这是可微双边网格首次在立体匹配网络中的应用。
(2)基于本文提出的代价空间上采样模块,我们设计了一个高精度的实时立体匹配网络(称为BGNet),该网络在KITTI数据集的分辨率下能够达到39fps,且精度超过了之前所有实时立体匹配网络。
2. 相关工作
基于深度学习的立体匹配网络研究已经持续了很多年。MC-CNN [1]首次使用卷积神经网络(CNN)来计算两个图像块之间的匹配代价,但后续步骤(如代价聚合、视差后处理等)仍然使用传统方法。DispNetC [2]是第一个端到端的立体匹配网络,后续的工作[3, 4, 5]引入了残差优化模块,对网络预测的视差图做一步的优化。GCNet [6]首次使用3D卷积学习构建4D代价空间,并使用soft argmin操作进行视差回归。
基于3D卷积的立体匹配网络在各大数据集榜单上都取得了很好的结果,但是 3D卷积比2D卷积计算量大的多,现有的基于3D卷积的实时立体匹配网络[7, 8]都是对低分辨率代价空间进行代价聚合,得到低分辨率的视差图,然后对视差图进行逐级上采样和优化,这种策略不如使用高分辨率代价空间计算视差图的方法精度高。
我们的工作受到双边网格[9]的启发。双边网格最早用于加速双边滤波器,主要包含三个步骤,即splat,blur和slice。splat操作对图像进行下采样构建双边网格,blur操作对双边网格进行平滑滤波,最后通过slice操作将滤波后的双边网格上采样到高分辨率。slice操作主要涉及在高分辨率引导图的指引下进行线性插值,因此其计算是非常高效的。
3. 方法描述
双边网格代价空间上采样
本文采用的思路是使用3D卷积在低分辨率构建双边网格代价空间,并通过提出的上采样模块(CUBG)得到高质量的高分辨率代价空间,在高分辨率代价空间进行视差回归。
如图1所示,CUBG模块的输入是一个低分辨率的代价空间和高分辨率的图像特征,输出是高分辨率的代价空间,该模块包含双边网格的生成和slicing上采样操作。
给定一个维度为
为了得到维度为
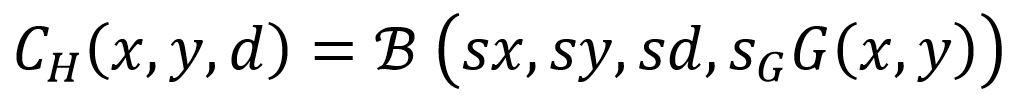
其中为低分辨率代价空间相对于高分辨率代价空间的宽度或者高度比例,
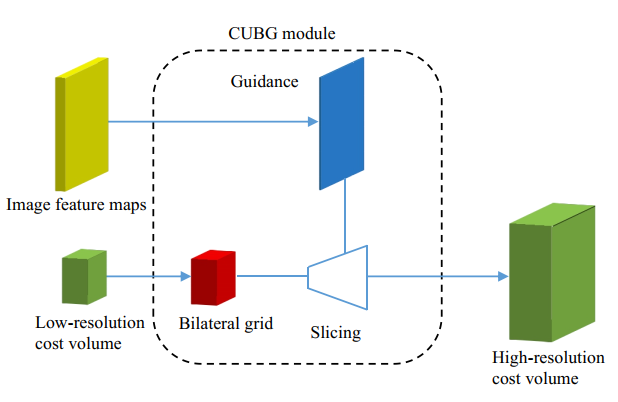
图1 基于双边网格的上采样模块,通过slicing操作能够从低分辨率的双边网格上采样得到一个高质量的高分辨率代价空间
嵌入式模块
CUBG模块可以无缝嵌入到许多现有的立体匹配网络结构中。在本文中,我把CUBG模块嵌入到四种具有代表性的网络,分别是GCNet, PSMNet, GANet和DeepPrunerFast。嵌入后的模型用后缀BG表示。比如,GCNet-BG表示在GCNet中嵌入了CUBG模块后的网络结构。
对于前三种网络结构,我们分别在1/8, 1/8, 1/6分辨率上重新建立代价空间,然后用CUBG模块把滤波后的代价空间分别上采样到1/2, 1/4和1/3分辨率。对于DeepPrunerFast,类似PatchMatch的视差上、下界估计模块和窄代价空间被1/8分辨率的完整的代价空间所代替。然后,用CUBG把滤波后的代价空间上采样到1/2分辨率。网络其余的结构都保持不变。
BGNet
基于CUBG模块,我们设计了一个高精度实时立体匹配网络,如图2所示。该网络主要包含四个模块:特征提取,代价空间聚合,代价空间上采样和残差优化模块。在不使用残差优化的情况下(对应BGNet),对于KITTI分辨率,速度为39fps。使用残差优化时(对应BGNet+),速度为30fps。
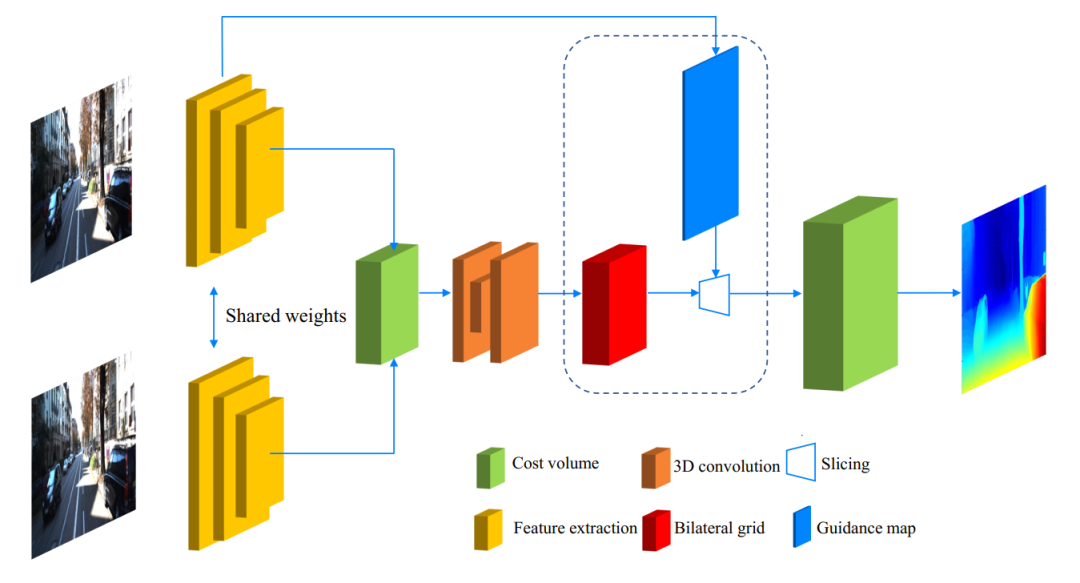
图2 BGNet 网络结构
4.实验结果
消融实验
为了验证所提出CUBG上采样模块的有效性,我们在SceneFlow、Middlebury 2014数据集上进行了消融实验,结果如表1,表2,图3所示。可见无论是在合成数据集还是在真实数据集上,CUBG都优于线性插值上采样(LU)。尤其是在深度边缘附近区域,CUBG优势更加明显(EPE-edge)。

表1 BGNet在SceneFlow上的消融实验结果. LU表示采用使用线性插值将低分辨率代价空间采样到高分辨率代价空间,EPE-edge表示边界区域的EPE误差,EPE-flat表示平坦区域的EPE误差

表2 BGNet在Middlebury 2014和KITTI 2015上的消融实验结果. Bad 2.0表示与真实值2像素误差的百分比,D1-all 表示对于全部区域误差超过3像素且超过真实值5%大小的异常点百分比

图3 在SceneFlow上的定性比较
嵌入到现有立体匹配网络
表3和表4展示了CUBG模块嵌入到GCNet,PSMNet,GANet_deep和DeepPrunerFast中,与原始网络在合成数据集和真实数据集的比较,可见使用CUBG模块能在与原始网络精度相当的情况下,得到大幅的速度提升。
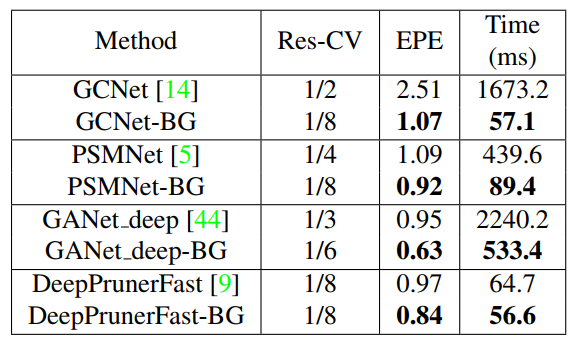
表3 将CUBG模块嵌入到现有立体匹配网络中在SceneFlow数据集上的定量比较.后缀BG代表嵌入CUBG后的模型,Res-CV表示构建的代价空间分辨率.
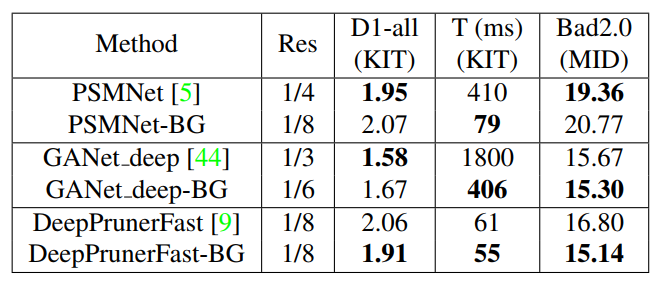
表4 将CUBG模块嵌入到现有立体匹配网络中在Middlebury 2014,KITTI 2015数据集上的比较
KITTI数据集评估
图4和表5是分别在KITTI数据集的定性和定量结果,在现有的50ms以内的网络中,BGNet的精度是最高的。
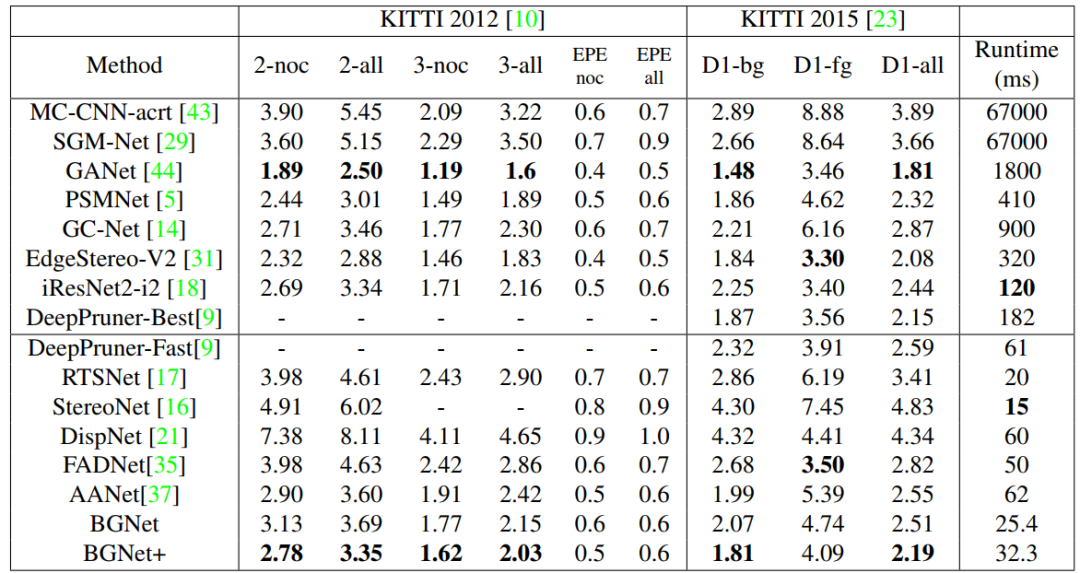
表5 在KITTI 2012和KITTI 2015数据集上的定量比较.其中x-noc表示在非遮挡区域误差大于x个像素的百分比,x-all表示在全部区域误差大于x个像素的百分比,fg表示前景区域,bg表示背景区域

图4 在KITTI 2015数据集上的定性比较.第一行为RGB图片,第二行,第三行,第四行分别是PSMNet,DeepPruner-Fast和BGNet+输出的视差图
泛化能力
泛化能力是立体网络中一个很重要的指标,我们测试了BGNet和BGNet+仅在合成数据集SceneFlow上训练时,在Middlebury 2014数据集上的泛化表现,如图5和表7所示,可见BGNet/BGNet+具有良好的泛化能力。此外,我们还用一个更大型的IRS数据集对网络进行了训练,其结果表明,具有真实感的合成数据集对于提升网络的泛化性能具有显著的作用。BGNet+ (IRS)在Middlebury上的泛化性能甚至超过了DSMNet [11]。
表7 Middlebury数据集泛化能力定量比较,其中IRS[10]表示使用了一个额外的室内数据集

图5 Middlebury数据集泛化能力定性比较,第一行是RGB图,第二行是BGNet+的视差图,第三行是PSMNet的视差图
参考文献
[1] Zbontar, Jure, and Yann LeCun. "Computing the stereo matching cost with a convolutional neural network." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2015.
[2] Mayer, Nikolaus, et al. "A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation." Proceedings of the IEEE conference on Computer Vision and Pattern Recognition (CVPR). 2016.
[3] Liang, Zhengfa, et al. "Learning for disparity estimation through feature constancy." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2018.
[4] Liang, Zhengfa, et al. "Stereo matching using multi-level cost volume and multi-scale feature constancy." IEEE Transactions on Pattern Analysis and Machine Intelligence (2019).
[5] Pang, Jiahao, et al. "Cascade residual learning: A two-stage convolutional neural network for stereo matching." Proceedings of the IEEE International Conference on Computer Vision Workshops. 2017.
[6] Kendall, Alex, et al. "End-to-end learning of geometry and context for deep stereo regression." Proceedings of the IEEE International Conference on Computer Vision (ICCV). 2017.
[7] Khamis, Sameh, et al. "Stereonet: Guided hierarchical refinement for real-time edge-aware depth prediction." Proceedings of the European Conference on Computer Vision (ECCV). 2018.
[8] Duggal, Shivam, et al. "DeepPruner: Learning efficient stereo matching via differentiable patchmatch." Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 2019.
[9] Chen, Jiawen, Sylvain Paris, and Frédo Durand. "Real-time edge-aware image processing with the bilateral grid." ACM Transactions on Graphics (TOG) 26.3 (2007): 103-es.
[10] Wang, Qiang, et al. "IRS: A large synthetic indoor robotics stereo dataset for disparity and surface normal estimation." arXiv preprint arXiv:1912.09678 (2019).
[11] Zhang F, Qi X, Yang R, et al. “Domain-invariant stereo matching networks.” European Conference on Computer Vision (ECCV). Springer, Cham, 2020: 420-439.
—版权声明—
来源丨3D视觉开发者社区
仅用于学术分享,版权属于原作者。
若有侵权,请联系微信号:yiyang-sy 删除或修改!
—THE END—