
人力和财务工作中常会用到的Pandas代码
各部门有多少名员工?
员工总体流失率是多少?
员工平均薪资是多少?
员工平均工作年限是多少?
公司任职时间最久的3名员工是谁?
员工整体满意度如何?
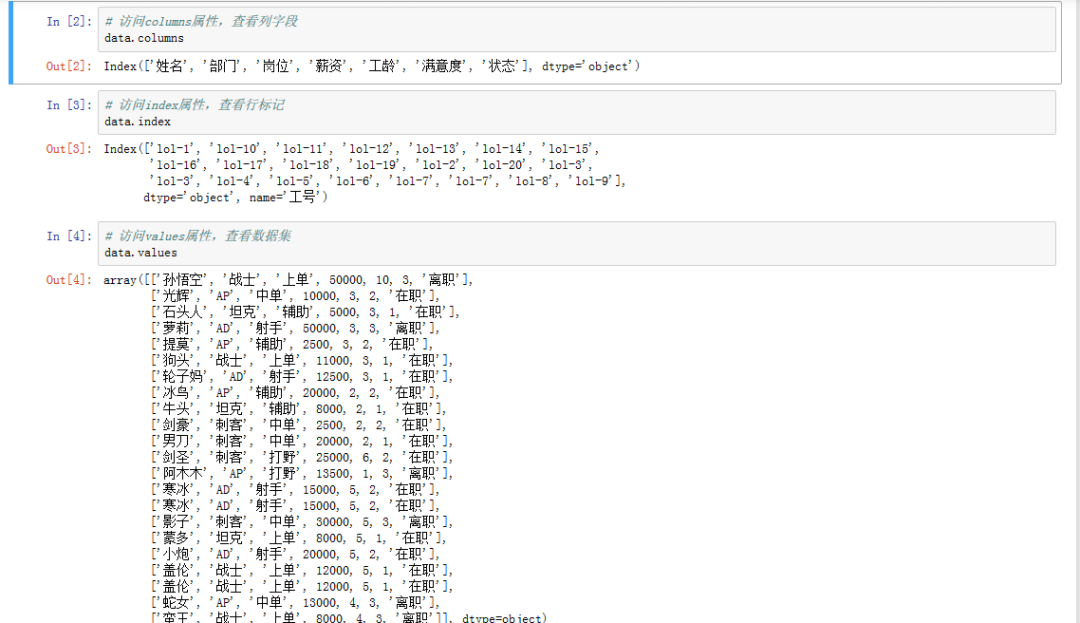
import pandas as pddata = pd.read_excel(r'英雄联盟员工信息表.xlsx', index_col='工号')# 访问columns属性,查看列字段data.columns# 访问index属性,查看行标记data.index# 访问values属性,查看数据集data.values
(单击查看大图)
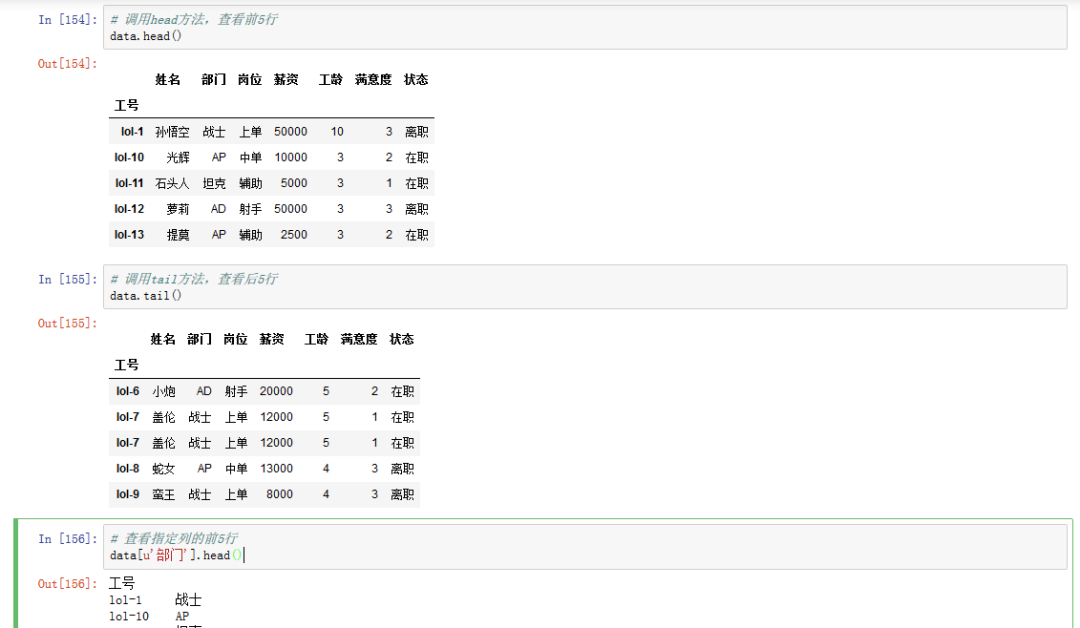
# 调用head方法,查看前5行data.head()# 调用tail方法,查看后5行data.tail()# 查看指定列的前5行data['部门'].head()
(单击查看大图)
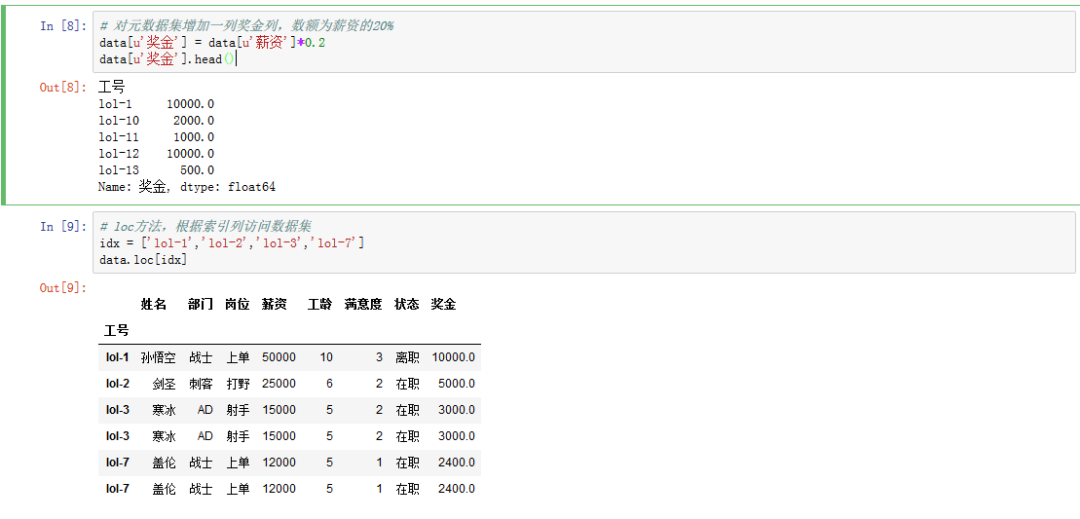
# 对原数据集增加一列奖金列,数额为薪资的20%data['奖金'] = data['薪资']*0.2data['奖金'].head()# loc方法,根据索引列访问数据集idx = ['lol-1','lol-2','lol-3','lol-7']data.loc[idx]
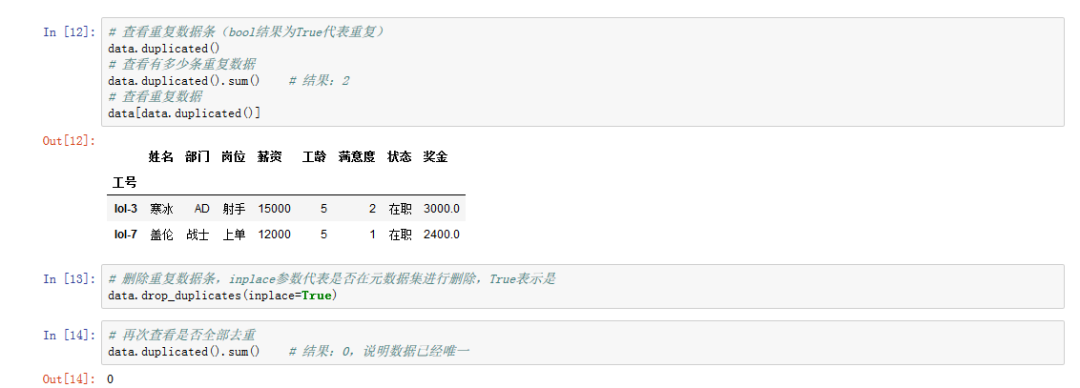
# 查看重复数据条(bool结果为True代表重复)data.duplicated()# 查看有多少条重复数据data.duplicated().sum() # 结果:2# 查看重复数据data[data.duplicated()]# 删除重复数据条,inplace参数代表是否在原数据集进行删除data.drop_duplicates(inplace=True)# 再次查看是否全部去重data.duplicated().sum() # 结果: 0, 说明数据已经唯一
(单击查看大图)
一、各部门有多少名员工?
# 频数统计data['部门'].value_counts()# ascending = True代表升序展示data['部门'].value_counts(ascending=True)
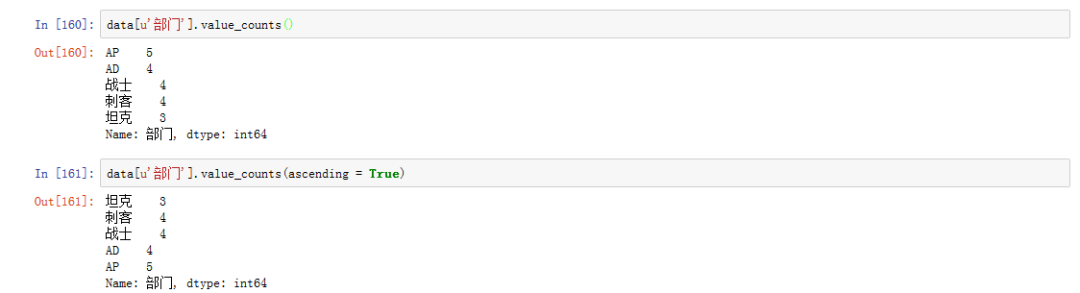
(单击查看大图)
二、员工总体流失率是多少?
# 频数统计data['状态'].value_counts()# normalize=True, 获得标准化计数结果data['状态'].value_counts(normalize=True)# 展示出员工总体流失率rate = data['状态'].value_counts(normalize = True)['离职']rate
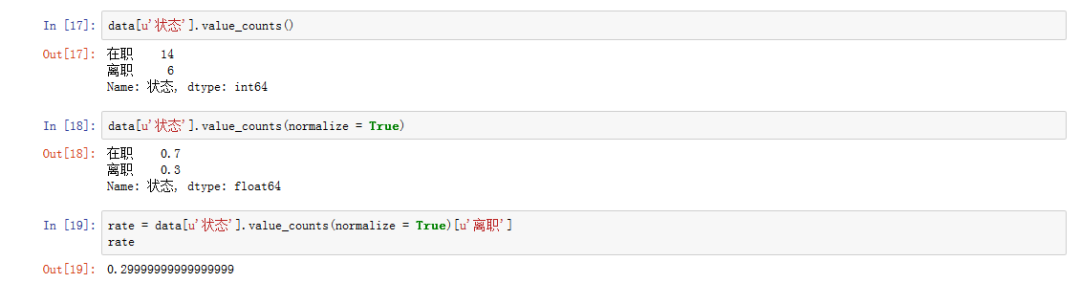
(单击查看大图)
三、员工平均薪资是多少?

(单击查看大图)
由上图的结果可以看出,平均薪资在16800元,你达到了吗?!允许你去哭一会o(╥﹏╥)o!
四、员工平均工作年限是多少?
五、公司任职时间最久的3名员工是谁?
# describe方法也是常用的一种方法,而且结果更全面data['工龄'].describe()# 通过降序排序、切片操作,找到待的最久的三名员工data['工龄'].sort_values(ascending=False)[:3]ID = data['工龄'].sort_values(ascending=False)[:3].indexdata.loc[ID]
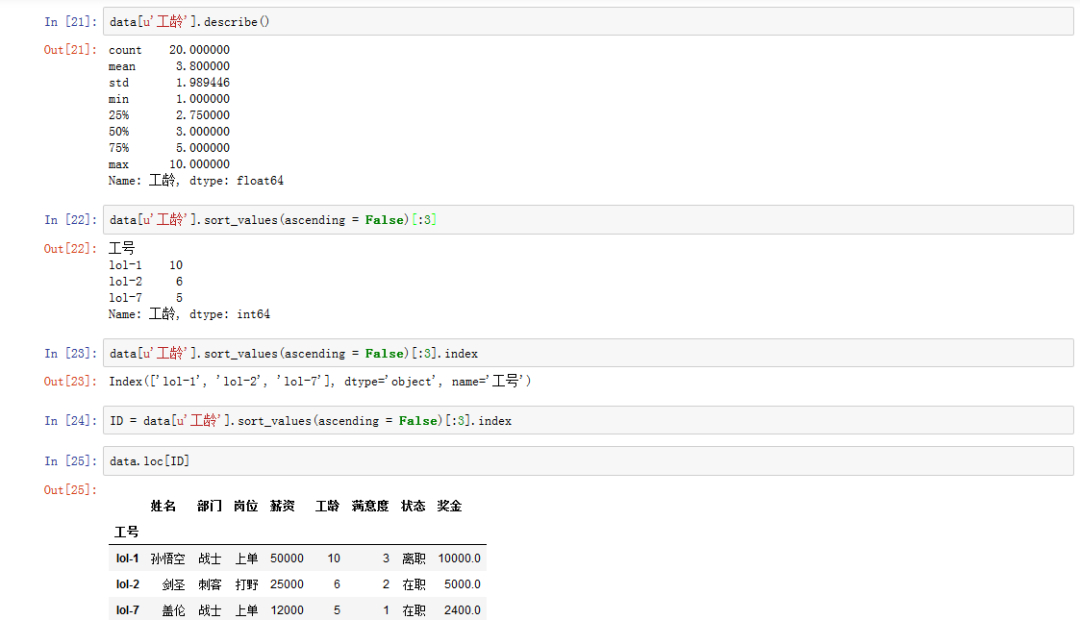
(单击查看大图)
六、员工整体满意度如何?
data['满意度'].head()# 通过查看满意度前五行发现,不太直观,我们可以用map进行映射,先建立一个映射字典JobSatisfaction_cat = {1:'非常满意',2:'一般般吧',3:'劳资不爽'}data['满意度'].map(JobSatisfaction_cat)# 对原数据集进行满意度映射data['满意度'] = data['满意度'].map(JobSatisfaction_cat)data['满意度'].head()
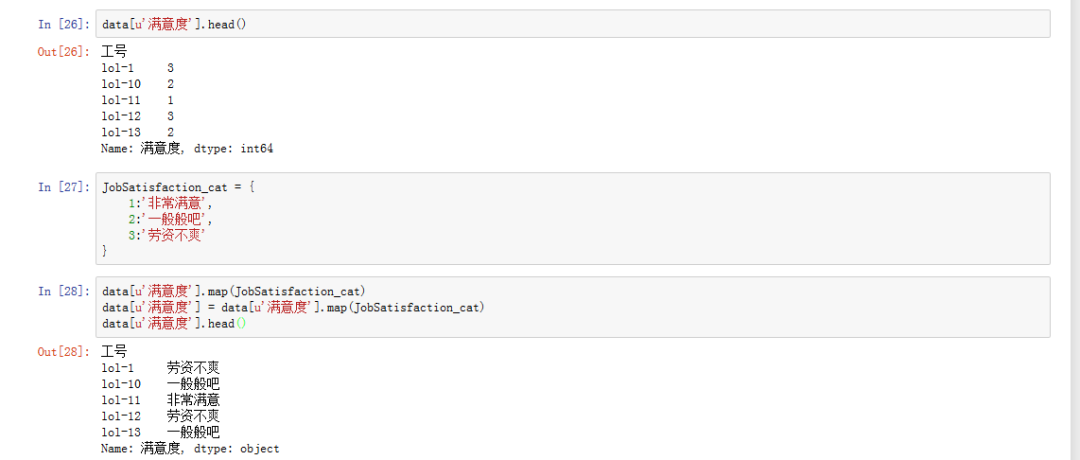
(单击查看大图)
接下来,进行员工整体满意度分析。通过计算可以得出:70%员工都比较认可公司,但仍有30%员工对公司不满意。人力主管以及部门主管需要进一步探究清楚这30%员工的情况,因为不满意是否已经离职?还是存在隐患?是否处于核心岗位等等问题值得我们进一步探究。
data.head()# 频数统计data['满意度'].value_counts()# 获得标准化计数结果,考虑到百分比更能说明满意度情况,所以乘100展示100*data['满意度'].value_counts(normalize=True)

(单击查看大图)
_往期文章推荐_
评论