
股票亏惨了,用Python来做一个投资计划
大家好,我是阳哥。
我也是一个坚持在股市投资的小韭菜,这不,这个星期,可以说是连续遭遇几次暴击。
阳哥今年的收益,在7月份不仅全部抹平,还亏了好几个点。
这几天,在进一步研究各个品种的投资配置计划,类似如下表格:
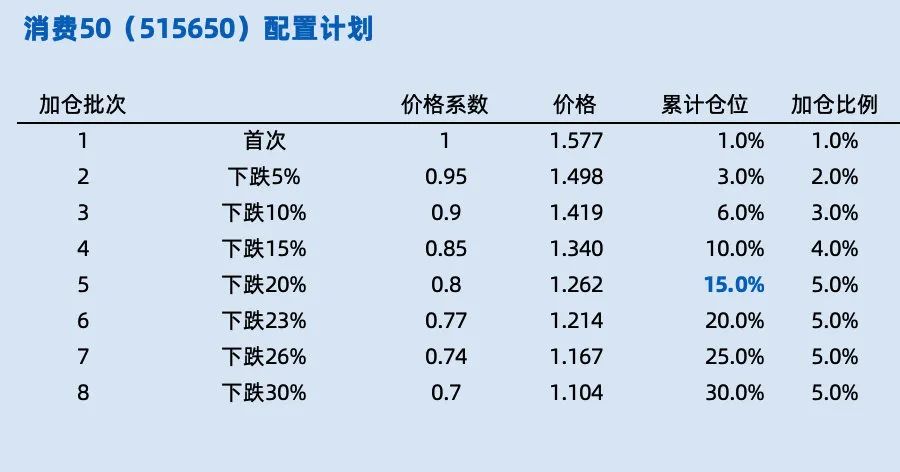
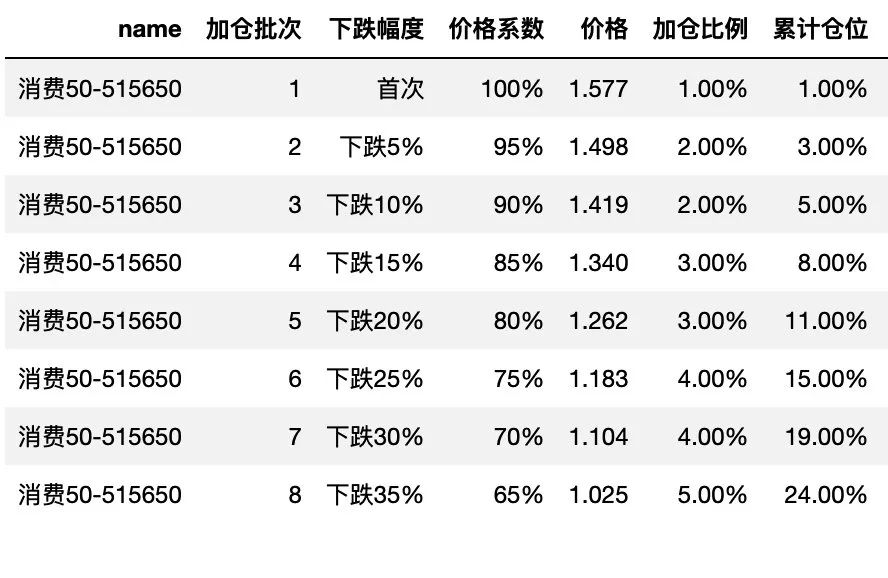
对于单个股票或ETF或基金,我以前用的是 Excel 表格,但最近发现,如果同时计算多个品种的投资计划时,Excel 的粘贴复制并不好用,原因是 Excel 表格中有许多表格单元格需要按F4固定,在复制使用时需要逐个修改,表格多了后,经常会忘记修改,这对投资而言,就很不严谨,如果数据计算错误,就很有问题了。
于是,就想着用 Python 来制作上述表格,并尽量将数据简化,将计算过程进行封装。
表格制作过程
在 Python 中制作上述表格,咱们可以用 Pandas 来实现。
Pandas是一种高效的数据处理库,它以 dataframe 和 series 为基本数据类型,呈现出类似excel的二维数据。
我们先来观察上面的Excel表格,在表格中,价格系数以及仓位比例这两列数据,是由咱们主观来控制的;此外,首次开始购买时的价格,也是主观控制的;首次购买份数,是由咱们总资金情况,根据仓位比例计算出来的,在这里,首次购买数量,也可以由咱们来主观控制输入。
因此,在Python中制作这个表格,可以先将主观控制的内容定义为变量。
import pandas as pd
# 标的名称
name = '中概互联-513050'
# 首次购入价格
price_init = 2.0
# 首次加仓比例
rate_init = 0.01
# 首次购入份额数量
shares_init = 2000
data = {
'价格系数':[1,0.95,0.9,0.85,0.8,0.75,0.7,0.65],
'加仓比例':[rate_init,0.02,0.03,0.04,0.05,0.05,0.05,0.05],
}
df = pd.DataFrame(data=data)
df
将已有变量输入到 DataFrame 中后,得到下面的表格:
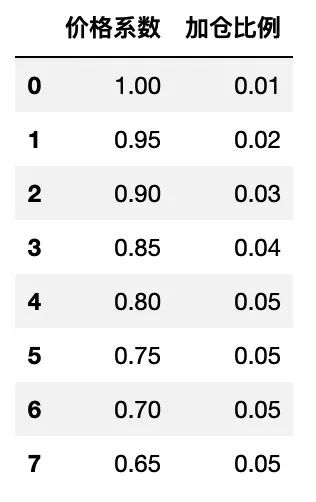
基于已有数据和变量来计算其他数据,包括 加仓批次 、品种名称 name 和 价格 列,同时设置其他列为空值( shares 为加仓数量,money 为 加仓金额)
df['加仓批次'] = list(range(1,len(df)+1))
df['name'] = name
df['价格'] = df['价格系数'] * price_init
df['shares'] = ''
df['money'] = ''
df
计算后,得到的表格如下:
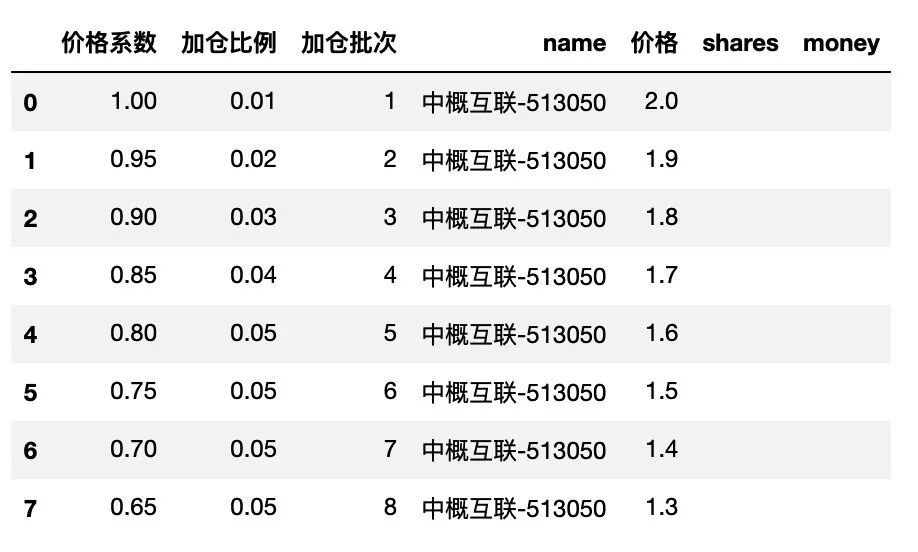
由于首次买入份额数量是由咱们自己控制的,可以先将首次购买的数量输入,如下:
df.loc[df['加仓批次']==1, 'shares'] = shares_init
df

同时计算首次购买的金额,如下:
df.loc[df['加仓批次']==1, 'money'] = df.loc[df['加仓批次']==1, '价格'] * df.loc[df['加仓批次']==1, 'shares']
df
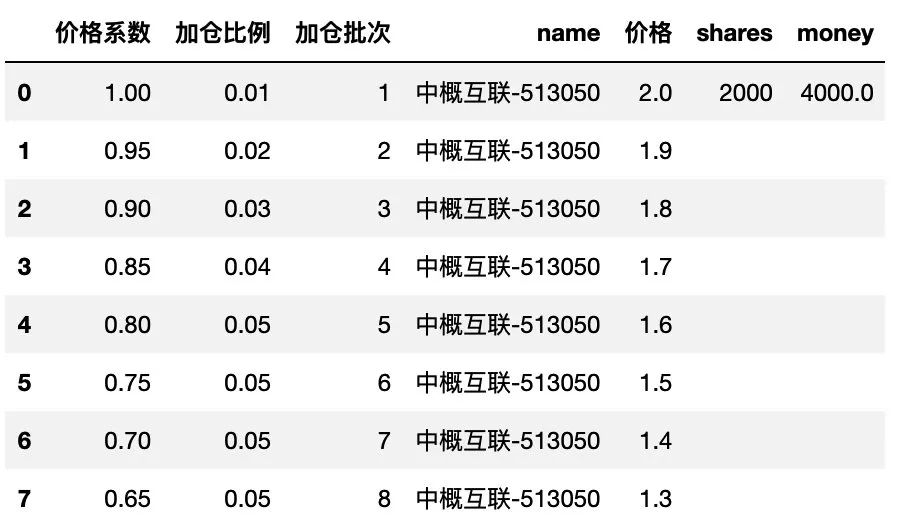
这里,在Pandas 中,是通过 .loc 筛选出具体的行,通过控制单个单元格来实现的。
接下来,需要计算 加仓批次 2到8 的每一行的份额数量以及金额,每一行的计算方法都是一样的,咱们以第2行为例来说明。
第2行的份额数量的计算公式为:
(第1行的金额 * 第2行的加仓比例 )/(第1行的加仓比例 * 第2行的价格)
由于交易数量是 100 的整数倍,因此还需要稍微调整下实际的份额数量,如下:
round((第1行的金额 * 第2行的加仓比例 )/(第1行的加仓比例 * 第2行的价格*100),0) * 100
Python代码如下:
money_init = df.loc[df['加仓批次']==1, 'money'].values[0]
df.loc[df['加仓批次']==2, 'shares'] = round(money_init*df.loc[df['加仓批次']==2, '加仓比例']/\
(rate_init * df.loc[df['加仓批次']==2, '价格']*100),0)*100
df
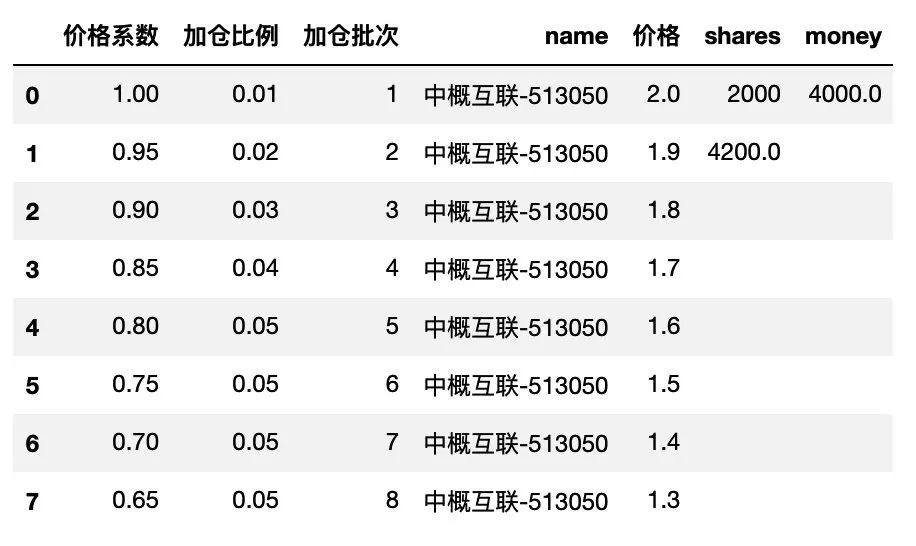
第2行的金额的计算如下:
df.loc[df['加仓批次']==2, 'money'] = df.loc[df['加仓批次']==2, '价格'] * df.loc[df['加仓批次']==2, 'shares']
df
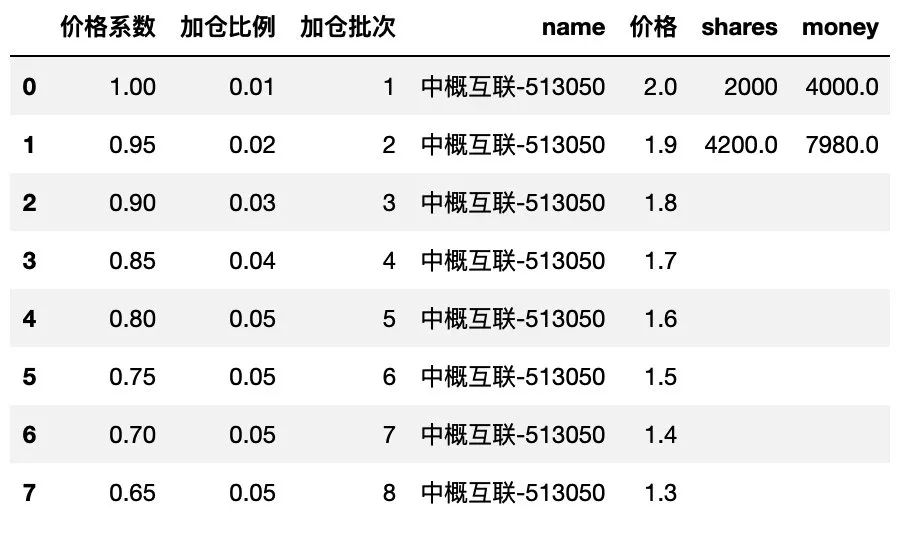
其他行的计算也是类似的,咱们可以用 for 循环来实现,如下:
for i in range(len(df)-1):
n = i+2
df.loc[df['加仓批次']==n, 'shares'] = round(money_init*df.loc[df['加仓批次']==n, '加仓比例']/\
(rate_init * df.loc[df['加仓批次']==n, '价格']*100),0)*100
df.loc[df['加仓批次']==n, 'money'] = df.loc[df['加仓批次']==n, '价格'] * df.loc[df['加仓批次']==n, 'shares']
df
这样,就可以计算出其他行的购买数量以及购买金额的数据了,得到的表格如下:
在上面表格的基础上,咱们还会经常要知道一些累计的数据,比如累计仓位,累计购买份额数量,累计购买金额,以及计算当前的投资成本等,在pandas中,累计求和使用 cumsum()函数,实现如下:
df['累计仓位'] = df['加仓比例'].cumsum()
df['累计份额'] = df['shares'].cumsum()
df['累计金额'] = df['money'].cumsum()
df['成本'] = df['累计金额']/df['累计份额']
df
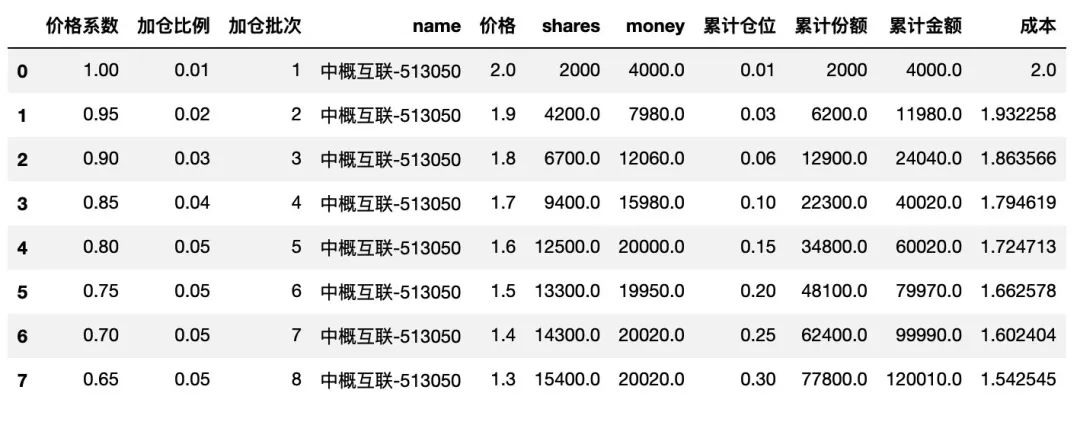
在 Excel 表格中,还有一列 下跌幅度 ,其数据类型为字符串型,在 Python 中,这个也是可以根据价格系数来计算出来的,比 Excel 中的手动修改还要方便些,如下:
df['下跌幅度'] = 1- df['价格系数']
df['下跌幅度'] = df['下跌幅度'].apply(lambda x:f'下跌{int(round(x*100,0))}%')
df.loc[df['加仓批次']==1, '下跌幅度'] = '首次'
df
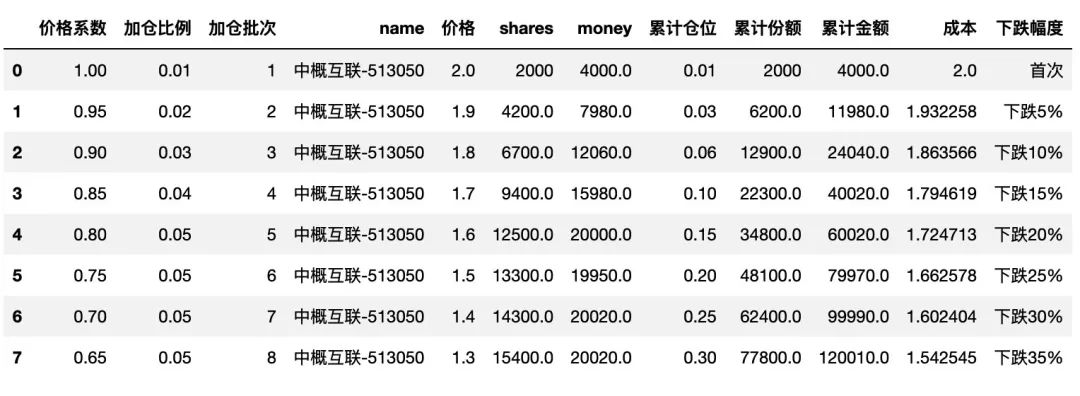
最后,就是调整显示的顺序,以及数据格式,如下:
df = df[['name','加仓批次', '下跌幅度', '价格系数','价格', '加仓比例', '累计仓位',
'shares', 'money','累计份额', '累计金额','成本']]
format_dict = {'money': '¥{0:.0f}',
'累计金额': '¥{0:.0f}',
'价格': '{0:.3f}',
'成本': '{0:.3f}',
'shares': '{0:.0f}',
'累计份额': '{0:.0f}',
'价格系数': '{0:.0%}',
'加仓比例': '{0:.2%}',
'累计仓位': '{0:.2%}',
}
df.style.hide_index().format(format_dict)
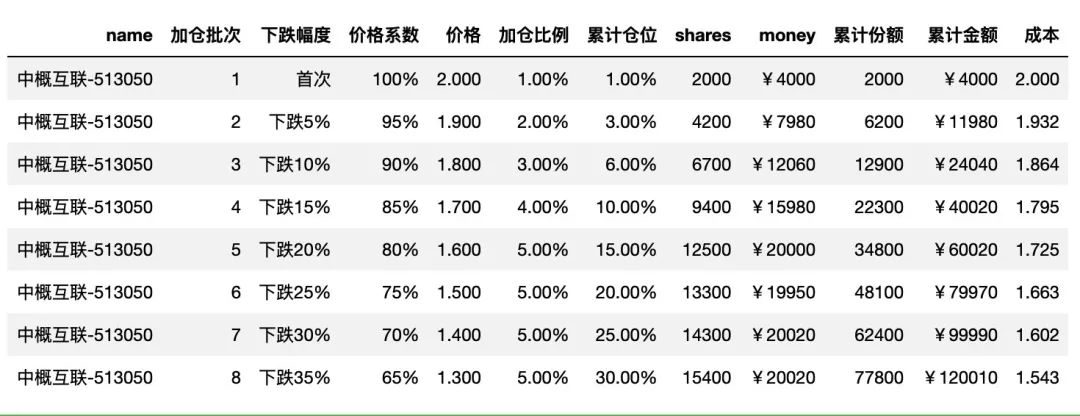
关于 Pandas 中表格样式设置的更多详细内容,可以前往下面的链接:
至此,针对单一品种的投资计划表格就出来了。
函数封装
上面是详细的分步骤的介绍,在实际使用过程中,咱们会针对多个品种进行核算,不同品种计划投资的仓位比例,价格间隔区间,可能都不一样,咱们可以通过将上面的实现过程封装成函数的形式,来适应各种需求,函数封装如下:
def plan(name,price_init,rate_init,shares_init,data):
df = pd.DataFrame(data=data)
df['加仓批次'] = list(range(1,len(df)+1))
df['name'] = name
df['价格'] = df['价格系数'] * price_init
df['shares'] = ''
df['money'] = ''
df.loc[df['加仓批次']==1, 'shares'] = shares_init
df.loc[df['加仓批次']==1, 'money'] = df.loc[df['加仓批次']==1, '价格'] * df.loc[df['加仓批次']==1, 'shares']
money_init = df.loc[df['加仓批次']==1, 'money'].values[0]
for i in range(len(df)-1):
n = i+2
df.loc[df['加仓批次']==n, 'shares'] = round(money_init*df.loc[df['加仓批次']==n, '加仓比例']/\
(rate_init * df.loc[df['加仓批次']==n, '价格']*100),0)*100
df.loc[df['加仓批次']==n, 'money'] = df.loc[df['加仓批次']==n, '价格'] * df.loc[df['加仓批次']==n, 'shares']
df['累计仓位'] = df['加仓比例'].cumsum()
df['累计份额'] = df['shares'].cumsum()
df['累计金额'] = df['money'].cumsum()
df['成本'] = df['累计金额']/df['累计份额']
df['下跌幅度'] = 1- df['价格系数']
df['下跌幅度'] = df['下跌幅度'].apply(lambda x:f'下跌{int(round(x*100,0))}%')
df.loc[df['加仓批次']==1, '下跌幅度'] = '首次'
df = df[['name','加仓批次', '下跌幅度', '价格系数','价格', '加仓比例', '累计仓位',
'shares', 'money','累计份额', '累计金额','成本']]
return df
上面的自定义函数涉及五个变量:
name,price_init,rate_init,shares_init,data对应的是:品种名称,初始买入价格,初始买入持仓比例,初始买入份额,列表数据(由价格系数和加仓比例组成)
对于咱们计划投资的品种,设置好变量的初始值后,就可以通过上述的自定义函数来计算出投资计划表了,如下:
# 标的名称
name = '中概互联-513050'
# 首次购入价格
price_init = 2.0
# 首次加仓比例
rate_init = 0.01
# 首次购入份额数量
shares_init = 2000
data = {
'价格系数':[1,0.95,0.9,0.85,0.8,0.75,0.7,0.65],
'加仓比例':[rate_init,0.02,0.03,0.04,0.05,0.05,0.05,0.05],
}
df = plan(name,price_init,rate_init,shares_init,data)
format_dict = {'money': '¥{0:.0f}',
'累计金额': '¥{0:.0f}',
'价格': '{0:.3f}',
'成本': '{0:.3f}',
'shares': '{0:.0f}',
'累计份额': '{0:.0f}',
'价格系数': '{0:.0%}',
'加仓比例': '{0:.2%}',
'累计仓位': '{0:.2%}',
}
df.style.hide_index().format(format_dict)
假设你要投资的是其他品种,比如万科,可以修改初始变量,快捷的得到投资计划,如下:
# 标的名称
name = '万科'
# 首次购入价格
price_init = 22
# 首次加仓比例
rate_init = 0.01
# 首次购入份额数量
shares_init = 300
data = {
'价格系数':[1,0.95,0.9,0.85,0.8,0.75,0.7,0.65],
'加仓比例':[rate_init,0.02,0.03,0.04,0.05,0.05,0.05,0.05],
}
df = plan(name,price_init,rate_init,shares_init,data)
format_dict = {'money': '¥{0:.0f}',
'累计金额': '¥{0:.0f}',
'价格': '{0:.3f}',
'成本': '{0:.3f}',
'shares': '{0:.0f}',
'累计份额': '{0:.0f}',
'价格系数': '{0:.0%}',
'加仓比例': '{0:.2%}',
'累计仓位': '{0:.2%}',
}
df.style.hide_index().format(format_dict)
得到的表格如下:
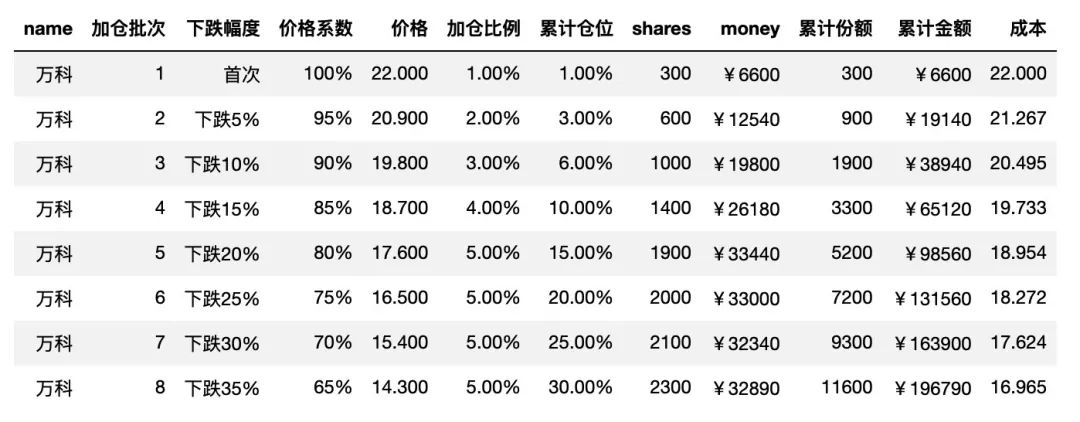
表格有什么用?
这个表格的实现,其实还是比较简洁的,用 Excel 也是可以较为方便的实现的,只是如果同时实现多个的话,会要麻烦一些,并且可能经常没有注意到个别单元格内容而出现错误。
这个投资计划表格,在实际投资中,还是有些作用的,看似很简单,但就是这种常识性的内容,往往很多人没有在投资之前就做好计划和设想。导致在实际投资过程中,买的比较随意,并且经常追高被套。
此外,由于事前没有做好计划,在投资组合的资产配置以及仓位管理方面,也是一片空白。经常会遇到下跌时发现没钱继续买了,这也是很尴尬的。
比如,上面的万科,如果按计划走的话,第一次买入300股,花费 6600元,钱也不多,但如果市场真要大幅度下跌,下跌达到 35% 以后,按计划投资,这个品种需要投资将近 20万,持仓占比 30% ,估计是很多人都没有想过的。
阳哥也是经过最近这几天的大跌,才开始反思自己投资计划的情况(发现没钱来大规模加仓了),之前有些品种买的也是有些随意。
如果能够事先做好功课,在下跌时泰然处之,不慌乱的清仓,估计投资结果会好很多。
PS:公号内回复「Python」即可进入Python 新手学习交流群,一起 100 天计划!
老规矩,兄弟们还记得么,右下角的 “在看” 点一下,如果感觉文章内容不错的话,记得分享朋友圈让更多的人知道!


【神秘礼包获取方式】