
Apache Cassandra 4.0新特性介绍
点击上方蓝色字体,选择“标星公众号”
优质文章,第一时间送达
作者 | DataStax
来源 | urlify.cn/3YBnYj
引言
大家好,我是蔡一凡,是Cassandra的贡献者之一。(虽然我不便透露我的公司名称),但目前我们公司Cassandra的部署是全世界最大的之一,Cassandra在我们公司也有很多的应用。
Cassandra是一个拥有high-scalability(高伸缩性)、high-availability(高可用性)的数据库。接下来,我们来看一下Cassandra 4.0将会为我们带来什么新的令人激动的特性。
首先,不久之前,Cassandra 4.0-beta1已经发布了,在发布这个版本之前,总共有超过三年多的开发、修复、测试时间。在这一版本中,多了很多好用的功能,也修复了大量的bugs,并且添加了多个测试工具。这些测试工具会带来更多类型的测试用例,从而提高测试的覆盖谱。在Cassandra 4.0中,测试是一个重中之重。因为社区的共识是,Cassandra 4.0会被作为史上最稳定版本来推出。

截止4.0-beta1这个版本,我们共有571项代码变更, 这个可以在Cassandra Repository里面看到。这些变更主要包括新功能和bugs的修复,但是大量对于不稳定测试的修复是不包括在内的,所以如果从commits的数量来说其实变化的地方还要多很多。
新功能介绍
今天我主要带来的是Cassandra 4.0版本中作为亮点的新功能,包括了审核日志、零拷贝串流、Netty节点间通信、虚拟表、增量式修复、临时副本。
审核日志

审核日志的功能是将数据库所有活动记录到一个本地文件,这些活动包括authentication,还有所有的CQL请求,不论成功与否都会被记录下来。
审核日志的性能是很高的,因为它默认的格式是二进制,所以它有很快的写入性能。而且由于并非向Cassandra数据库中写入,所以运行审核日志对其它数据库操作的影响是比较小的,不太会影响数据库的性能。
审核日志这个功能有很多的用途,譬如利用记录来debug线上碰到的问题,也可以帮助做测试。比如在4.0中同步推出的full query logger就是用审核日志来实现的,这些由full query logger生成的记录可以在之后用来做回放测试。另外,审核日志也可以帮助企业做合规管理,因为所有的活动都可以被记录到文件,企业的审核也可以有所依据。
零拷贝串流
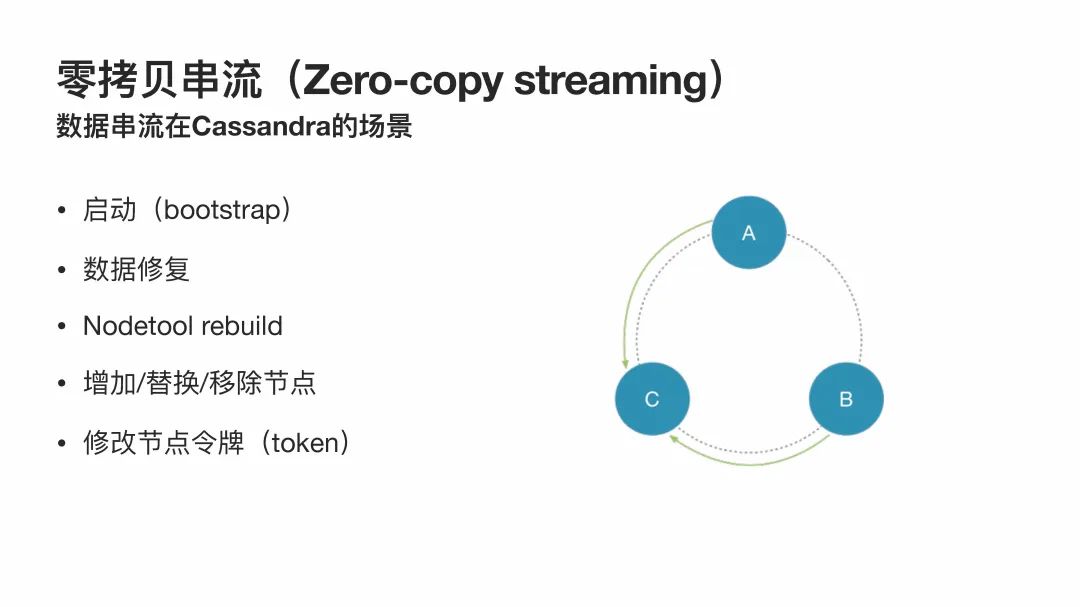
在介绍零拷贝串流之前,我想先介绍一下数据串流的场景。
用过Cassandra的同学应该都知道,在node(节点)启动(bootstrap)时,它会从副本节点将数据串流过来,数据修复时也会有数据串流的现象。另外,运行nodetool rebuild时节点也会跟其副本节点进行串流。除此之外,在现有集群中增加、替换、移除节点时,节点都会从别的副本节点或向别的副本节点串流数据。最后一个场景就是节点的token被修改时,不属于某个节点的token范围的数据,就会被串流到新的负责该数据的token的其它节点。总而言之,在Cassandra中,串流会被应用于很多场景。基本所有数据在集群中被复制时都会发生这个现象。
回过头看,零拷贝串流的“零拷贝”是指在串流时无需将数据读到内存后再写入到网络。零拷贝串流只需要发送方和接收方可以直接通过网络发送和接收数据。当然,这个功能其实是依赖于操作系统的。如果运行Cassandra的系统支持这个功能,那么可以大大提升传输速度。因为零拷贝串流不需要把数据读到内存中,所以也避免创建相关的对象,继而减少了对于GC的压力。
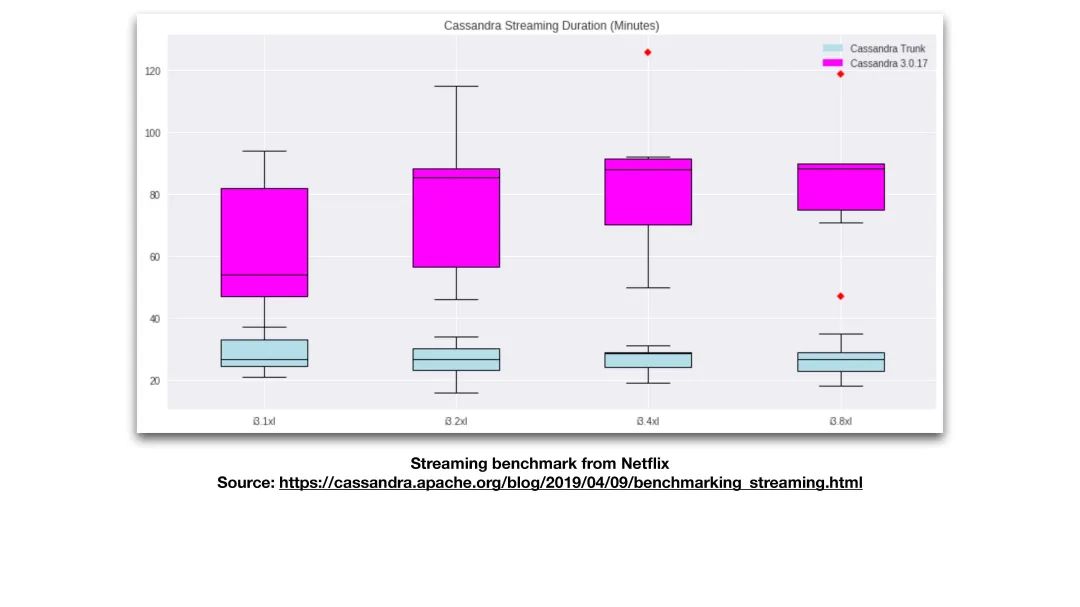
接下来,我们看一下Netflix做的一个测试。首先我先简单介绍他们的测试是怎么做的。Netflix在相同的硬件条件下,进行了多次的A/B测试,并得到一个结果的分布。A/B测试中主要是对比3.0版本和4.0版本串流所用的时间。其中,3.0版本使用的是普通串流,而4.0版本使用的是零拷贝串流。串流的时间是怎么获得的呢?在一个集群,测试人员将其中的一个节点替换掉,并统计新节点串流所用的时间。在四种不同的硬件条件下分别进行了同样的实验,以便于比较。
PPT中可以看到有四个箱型图,每个箱型图最上面的线是多次测试中的最长时间,最下面的线是多次测试中的最短时间。箱型图中间还有一条线,这是多次测试结果的中位数。箱子的上沿是多次测试结果中的75百分位;箱子的下沿则是多次测试结果中的25百分位。而图中洋红色的箱子则是普通串流得到的数据,而灰蓝色则是零拷贝串流得到的数据。
在图中,我们可以一目了然地看到,在不同的硬件条件下,零拷贝串流所需的时间都是远远小于普通串流所需的时间的。另外,零拷贝串流的箱子也会比较短一些,这表示在多次测试的基础上,可以发现其性能的稳定性是很高的。零拷贝串流在不同的硬件条件下运行,所需时间都比较相近。因为对于零拷贝串流来说,数据不需要被加载到内存中,CPU也不需要浪费时间去处理这些数据,所以零拷贝串流所需要的时间主要是与硬盘和网卡的速度有关,反而与CPU的关系不大。反观普通串流,我们可以看到在不同硬件下,它所需要的时间的分布是有很大波动的。相比之下,零拷贝串流比普通串流提高了3-5倍的速度。

前面说到,零拷贝串流是直接把数据通过网络端口发送出去,所以与CPU bound相对,零拷贝串流是一个I/O bound的功能。另外,由于零拷贝串流大大提升了串流速度,所以它帮助缩短了每一个节点的平均恢复时间。恢复时间是指,如果有一个节点出现故障了,在改节点被修复之后需要从别的副本节点中传输相应的数据。当数据修复传输的速度更快,节点所需的平均恢复时间就被缩短了,也就是说,节点处于“不可用(unavailable)”状态的时间会被缩短。这样也会相应减少多个节点可能同时处于不可用状态的概率。除此之外,零拷贝串流可以帮助降低运维成本。举例来说,当我们要把一个节点的数据迁移到一个新的节点,如果数据传输的过程可以更快完成,原来的节点就可以更早地被关闭,这样可以帮助减少一部分的开销。
Netty节点间通信
如果有读过Cassandra源代码的同学可能会知道,Cassandra在3.0、2.1、2.0这些版本是根据集群中的节点来分配线程的。一般来说,每个节点会被分配三个线程用来通信,这三个线程分别负责体积较小的信息、体积较大的信息以及较为紧急的信息。
在4.0版本中,我们把这个架构改成了Netty。I/O是非阻塞的,不再按节点分配线程。
接下来的这几个数据同样是来自Netflix,是通过在一个192个节点的Cassandra集群中进行测试得到的。在测试中,我们比较了4.0版本和3.0版本。我们发现4.0版本的延迟会更低(平均值减少40%,99分位的延迟减少了60%),且吞吐量更高(大约2倍的提升)。
另外,4.0版本的内存占用更少,原因是4.0版本中对inbound和outbound连接的实现进行了改进。对于outbound,Cassandra有自己的Frame Encoder。它不同于Netty的Frame Encoder的一点是它避免了多次的内存拷贝,也就是说,它在使用handler时不会先写入很多内存,只有Frame有的时候它才会写入。对于inbound,Cassandra也有自己的Frame Decoder的实现。当接收到足够多的数据之后,Cassandra的Frame Decoder才会做解压缩的处理,并且对于未处理消息的个数也做了限制。如果inbound的消息太多,就会被block,相当于对别的节点实现了back pressure的功能。
最后一点是节点间加密通信扩展性更高,主要是得益于Netty的tcnative。它跟JDK自带的的加密性能相比,大概提升了有4倍。
总而言之,通过改进到使用Netty节点间通信,Cassandra集群中各个节点间的通信变得更有效率。
虚拟表

虚拟表之所以被叫做虚拟表,是因为并没有硬盘上的数据与之对应。虚拟表是虚拟的,它其实是基于Cassandra内部的一些API实现的,所以我们可以把虚拟表当作Cassandra的一个接口。
目前来说,虚拟表是只读性质的。也就是说,我们只可以对Cassandra的一些状态进行查询,但是并不能通过虚拟表对系统状态和配置做出改变。每一个虚拟表都是每个节点所特有的,也就是说虚拟表是local的。
怎么操作虚拟表呢?我们可以通过CQL来进行查询,从而获取Cassandra的系统状态和当前配置。另外,因为有了虚拟表,我们可以不用JMX,CQL Clients也可以通过CQL接口方便地进行查询。
接下来我们来看一下虚拟表大概的样子。
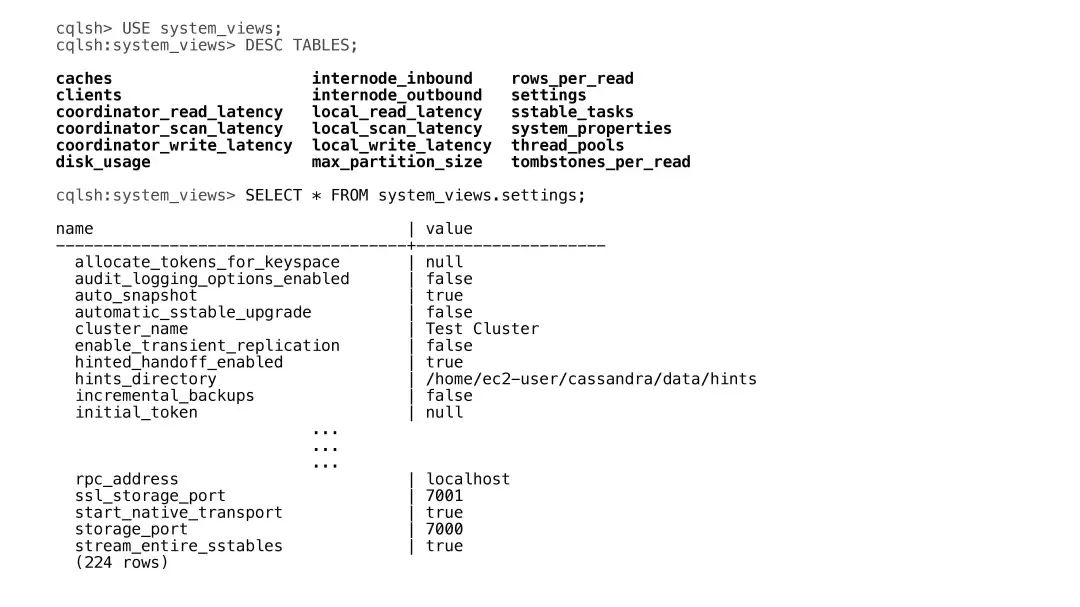
所有的虚拟表都是位于system_views这个keyspace下面,PPT中加粗的部分就是目前有的虚拟表。比如其中有一个是settings,这个表中列出了当前Cassandra的配置。
欢迎大家下载Cassandra 4.0 Docker image来体验更多其它的虚拟表,这里就不一一展示了。
增量式修复

首先,增量式修复并不是4.0中的新功能,在Cassandra 2.1中这个功能就已经被推出了。但是在当时的版本中,这个功能存在一些问题,所以并不适用于在生产环境中使用。Cassandra 4.0所做的主要工作就是把之前的很多问题修复了。
在我们更多地介绍增量式修复之前,我们先简单介绍一下什么是“修复”。在Cassandra运行时,节点间数据随着时间的推移会出现不一致的情况。“修复”功能就是用来解决节点间数据不一致的问题。粗略地说,每个节点都会比较本地和副本节点的数据,如果发现数据有差别,“修复”功能就会帮助同步这些节点的数据,从而达到整个集群中数据一致的效果。但是普通的修复有一个问题,就是这个操作是比较昂贵的——运行时间较长,且运行期间会增加query的延迟。
在此基础上,增量式修复的意思就是不再修复已经修复过的数据。它的实现大概是将数据分为“已修复”和“未修复”两个部分,每次修复时只修复“未修复”的部分。这样,每次修复的时间就会减少。因此,我们可以更频繁地使用增量式修复,而每次修复只需要几分钟时间即可完成。
在4.0之前,增量式修复的问题到底是什么呢?其实主要是overstreaming(过度传输)的问题。过度传输的意思是,某一份数据因为之前的修复在某一节点已经存在,但是增量式修复出于某些原因无法识别该数据已经在节点被修复,所以这份数据又被重新串流到别的节点。比如说现在正在修复一个SSTable,这时有一个后台例行的Compaction task(压缩任务)把这个SSTable压缩之后又产生一个新的SSTable。这个时候,这个新产生的SSTable不会被标记成已修复,在下一次增量修复时,这个新的SSTable会被认为数据和别的节点不一致,所以数据又会被重新发送一次。这也就导致了overstreaming的问题。
新的增量式修复把这个过程做成了一个可以被回撤的transaction。也就是说如果发生了前面说的问题,所有当前repair的sessions都会被标记为失败,相关的SSTable也会回滚到“未被修复的SSTable”的池里面。
临时副本
临时副本是4.0版本的试验性功能,还有很多的限制,所以并不推荐用在生产环境中,但是有兴趣的同学可以先提前尝鲜。
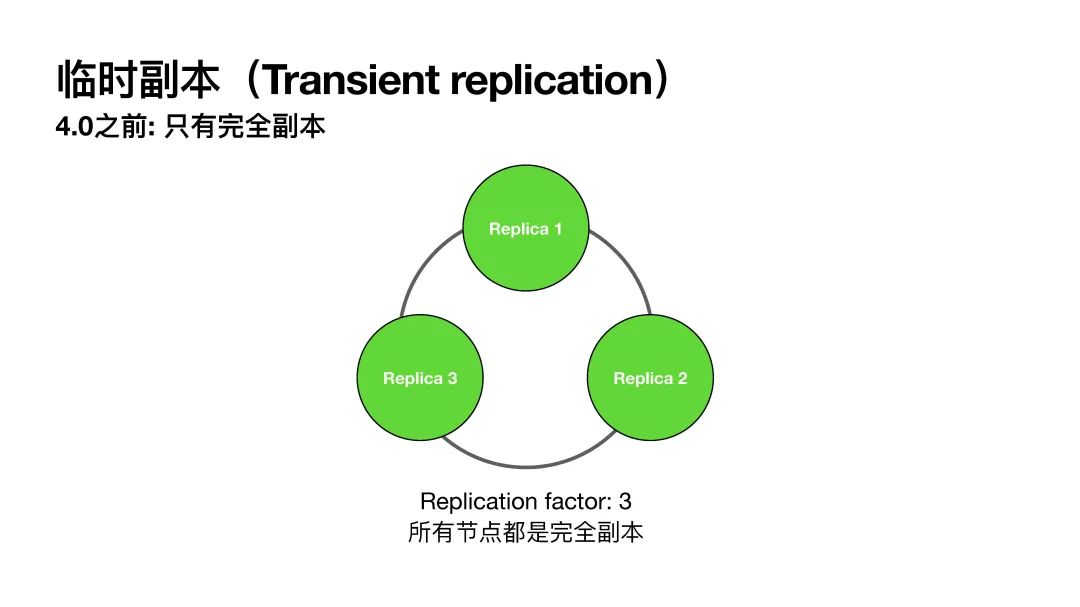
在临时副本之前,我先介绍一下什么是完全副本。在4.0之前的replica就是完全副本,因为4.0多了临时副本,所以讲以前的replica起了个新的名字以区别两种副本。
在PPT的图中有一个由三个节点组成的集群,这三个节点都是完全副本。当replication factor等于3时,每个节点负责的数据都会有三个备份。也就是说,假设一个集群共有3TB的数据,刨去副本之后其实只有1TB数据,即三分之二的存储空间是被浪费掉的。
临时副本主要就是用来解决这个问题的。临时副本节点只保存没有修复的数据,在修复之后,这些数据就会被临时副本节点删除。也就是说这些数据是临时的,这也是为什么我们管它叫“临时副本”。
这个功能最好是和增量式修复一起使用,因为这样我们可以很快地从临时副本节点中将未修复的数据修复,之后再删除掉。这样一来,我们可以认为临时节点并不占用存储空间。依旧使用前面的例子:当replication factor为3,其中一个节点作为临时节点。这样一来,我们减少使用了三分之一的存储空间。在大规模集群中,如果可以减少三分之一的存储空间,这将会是一大进步。
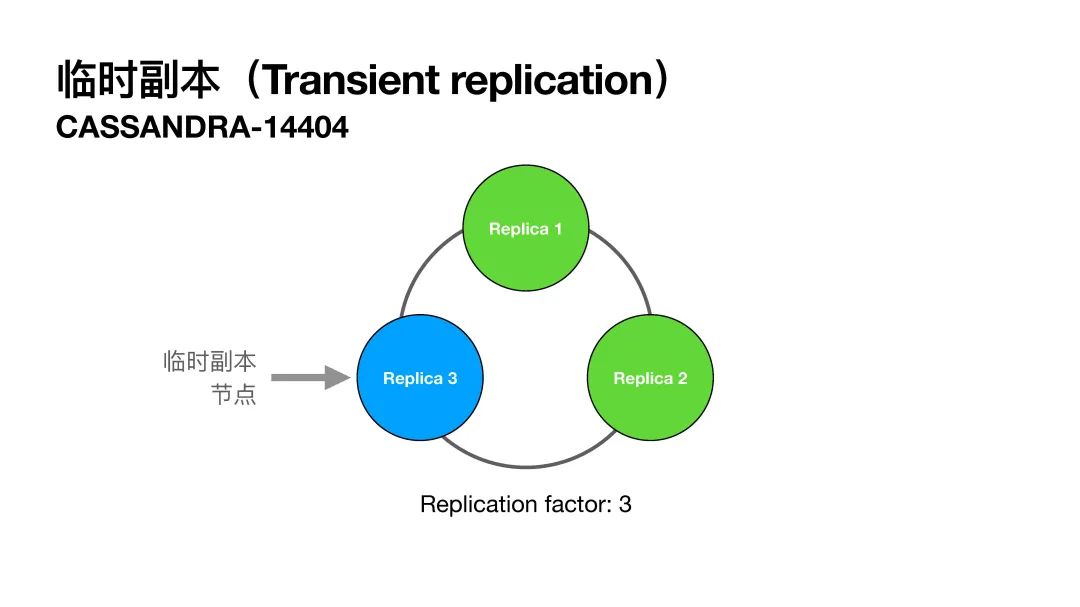 临时节点是这样工作的:当有写入操作时,写操作会优先考虑完全副本;当完全副本出现故障或下线时,写操作才会写到临时副本节点。关于读操作,我们只要保证当前副本集里面有一个完全副本就可以,因为只要增量式修复一直在运行,完全副本就肯定会被修复。拿PPT中的图举例,如果节点1变成不可用状态,只有节点2和3也还是可以保证读操作能满足Quorum的read query。当然,如果读操作要求consistency level = ALL的话,这种情况就不能满足要求了,原来也是不行的。
临时节点是这样工作的:当有写入操作时,写操作会优先考虑完全副本;当完全副本出现故障或下线时,写操作才会写到临时副本节点。关于读操作,我们只要保证当前副本集里面有一个完全副本就可以,因为只要增量式修复一直在运行,完全副本就肯定会被修复。拿PPT中的图举例,如果节点1变成不可用状态,只有节点2和3也还是可以保证读操作能满足Quorum的read query。当然,如果读操作要求consistency level = ALL的话,这种情况就不能满足要求了,原来也是不行的。
另外,临时节点的增加依然可以保证原有的可用性的承诺,相同consistency level的query在有临时副本节点的集群中与只有完全副本节点的集群是可以等效的。当一个有临时副本节点的Cassandra集群变成不可用的状态时,它所失去的节点数目和只有完全副本节点的集群也是一致的。所以从这一点来说,加入临时副本节点对于使用Cassandra的应用来说是完全透明的,也就是说应用是完全不会察觉到临时副本节点的使用的。

临时副本节点带来的好处包括上面提到的,当RF = 3时,使用一个临时节点可以减少33%的存储。另外,因为临时节点只保留临时数据,数据量比较小,修复完就删除,所以这个节点会使用更少的CPU和I/O。除此之外,临时副本还保留了持久性的保证。也就是说,在只有完全副本节点时能满足什么consistency level的query,使用了临时副本节点之后还是有这样的保证。
结束语
以上就是Cassandra 4.0中比较重要的新功能。
最后总结一下,Cassandra 4.0增加了多项新功能,带来了增强的性能、更快的串流速度以及更高的可靠性。整个社区也花费了最长的时间来测试Cassandra 4.0,以确保Cassandra 4.0是Cassandra史上最稳定的版本。
欢迎大家有时间时体验一下Cassandra 4.0。



感谢点赞支持下哈 