
Spark 特性 | Apache Spark 3.2 正式发布,新特性详解
经过七轮投票, Apache Spark™ 3.2 终于在昨天正式发布了。Apache Spark™ 3.2 已经是 Databricks Runtime 10.0 的一部分,感兴趣的同学可以去试用一下。按照惯例,这个版本应该不是稳定版,所以建议大家不要在生产环境中使用。
Spark 的每月 Maven 下载数量迅速增长到 2000 万,与去年同期相比,Spark 的月下载量翻了一番。Spark 已成为在单节点机器或集群上执行数据工程、数据科学和机器学习的最广泛使用的引擎。

Spark 3.2 继续以使 Spark 更加统一、简单、快速和可扩展为目标,通过以下特性扩展其范围:
•在 Apache Spark 上引入 panda API,统一小数据API和大数据API(在这里了解更多)。•完成 ANSI SQL 兼容模式,简化 SQL 工作负载的迁移。•自适应查询执行产品化完成,以在运行时加速 Spark SQL。•引入 RocksDB 状态存储以使状态处理更具可扩展性。
在这篇博文中,我们总结了一些更高层次的特性和改进。请关注即将发布的深入研究这些特性的文章。有关所有 Spark 组件的主要功能和已解决的 JIRA 的完整列表,请参阅 Apache Spark 3.2.0 release notes
统一小数据 API 和大数据 API
Python 是 Spark 上使用最广泛的语言。为了使 Spark 更具 Python 风格,Pandas API 被引入到 Spark,作为 Project Zen 的一部分(另请参阅 Data + AI Summit 2021 会议中的 Project Zen: Making Data Science Easier in PySpark 议题)。现在 pandas 的现有用户可以通过一行更改来扩展他们的 pandas 应用程序。如下图所示,得益于 Spark 引擎中的复杂优化,单节点机器 [左] 和多节点 Spark 集群 [右] 的性能都可以得到极大提升。
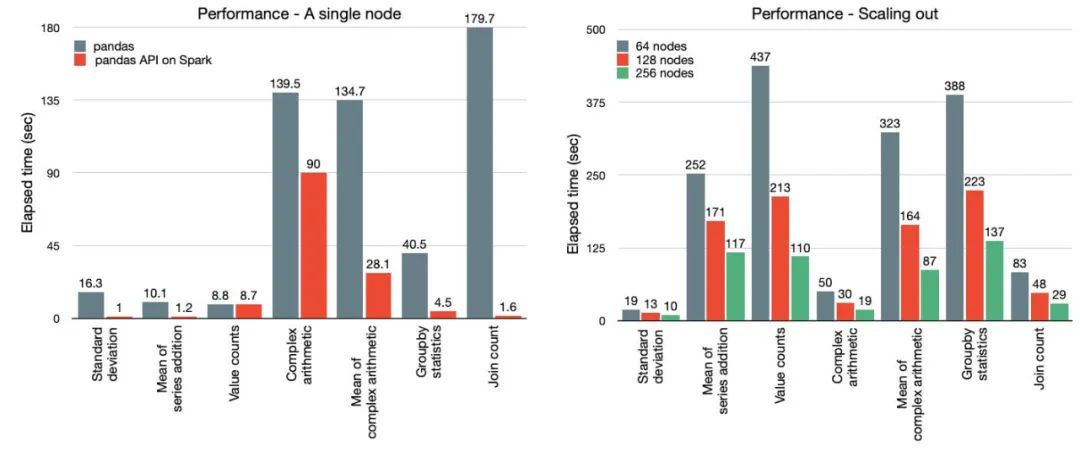
同时,Python 用户还可以无缝利用 Spark 提供的统一分析功能,包括通过 SQL 查询数据、流处理和可扩展机器学习 (ML)。新的 Pandas API 还提供了由 plotly 后端支持的交互式数据可视化。

更多详情请参见 即将发布的 Apache Spark 3.2 将内置 Pandas API
简化 SQL 迁移
添加了更多 ANSI SQL 功能(例如,支持 lateral join)。经过一年多的发展,本次发布的 ANSI SQL 兼容处于 GA 状态。为了避免大量破坏行为的更改,默认情况下 spark.sql.ansi.enabled 依然是未启用的。ANSI 模式包括以下主要行为更改:
•当 SQL 运算符/函数的输入无效时,会抛出运行时错误,而不是返回为 null (SPARK-33275)。例如,算术运算中的整数值溢出错误,或将字符串转换为数字/时间戳类型时的解析错误。•标准化类型强制语法规则 (SPARK-34246)。新规则定义了给定数据类型的值是否可以基于数据类型优先级列表隐式提升为另一种数据类型,这比默认的非 ANSI 模式更直接。•新的显式转换语法规则 (SPARK-33354)。当 Spark 查询包含非法类型转换(例如,日期/时间戳类型转换为数字类型)时,会抛出编译时错误,告知用户转换无效。
此版本还包括一些尚未完全完成的新计划。例如,标准化 Spark 中的异常消息(SPARK-33539);引入 ANSI interval type (SPARK-27790) 并提高相关子查询的覆盖范围 (SPARK-35553)。
在运行时加速 Spark SQL
此版本 (SPARK-33679) 中默认启用自适应查询执行 (AQE)。为了提高性能,AQE 可以根据在运行时收集的准确统计信息重新优化查询执行计划。在大数据中,维护和预先收集统计数据的成本很高。无论优化器有多先进,缺乏准确的统计信息通常会导致计划效率低下。在这个版本中,AQE 与所有现有的查询优化技术(例如,动态分区修剪,Dynamic Partition Pruning)完全兼容,以重新优化 JOIN 策略、倾斜 JOIN 和 shuffle分区合并。
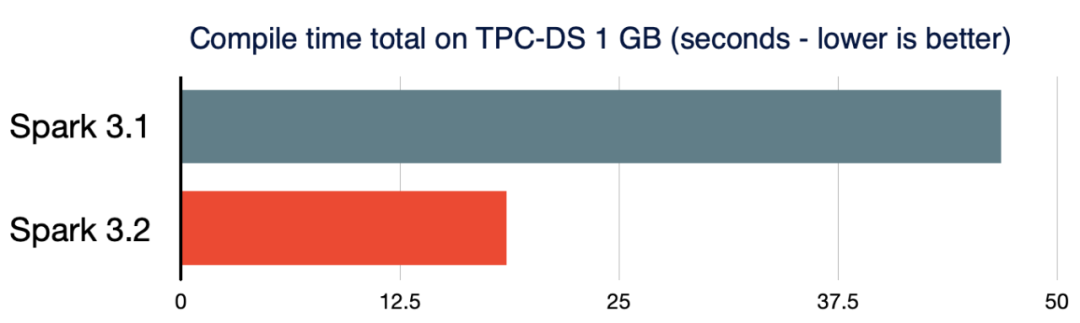
小数据和大数据都应该在统一的数据分析系统中以高效的方式处理。短查询性能也变得至关重要。当处理的数据量相当小时,在复杂查询中编译 Spark 查询的开销非常大。为了进一步降低查询编译延迟,Spark 3.2.0删除了分析器/优化器规则(SPARK-35042、SPARK-35103) 中不必要的查询计划遍历,并加快了新查询计划的构建 (SPARK-34989)。因此,与 Spark 3.1.2 相比,TPC-DS 查询的编译时间减少了 61%。
更可扩展的状态处理流
Structured Streaming 中状态存储的默认实现是不可伸缩的,因为可以维护的状态数量受执行器堆大小的限制。在此版本中,Databricks 为 Spark 社区基于 RocksDB 的状态存储实现做出了贡献,该实现已在 Databricks 生产中使用了四年多。这种状态存储可以通过对键进行排序来避免完全扫描,并在不依赖于执行器堆大小的情况下从磁盘提供数据。
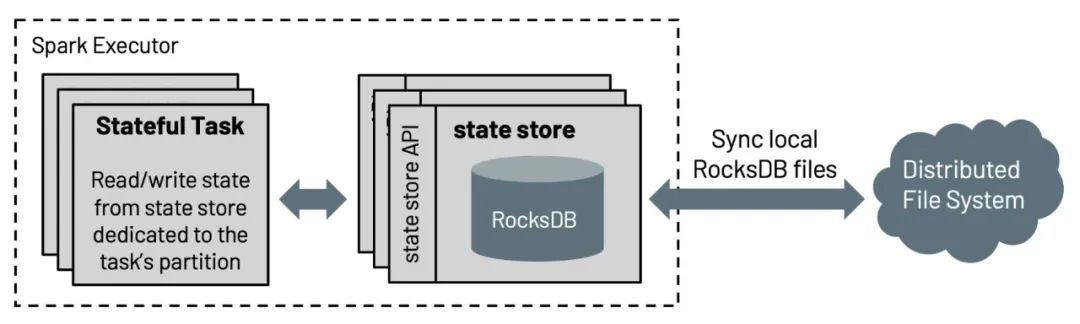
此外,状态存储 API 还包含用于前缀匹配扫描 (SPARK-35861) 的 API,以有效支持基于事件时间的会话 (SPARK-10816),允许用户在 eventTime 上对会话窗口进行聚合。更多细节,请阅读 Native support of session window in Apache Spark’s Structured Streaming 博文。
Spark 3.2 的其他更新
除了上面这些新功能外,这个版本还关注可用性、稳定性和功能加强,解决了大约 1700 个 JIRA tickets。这是 200 多名贡献者贡献的结果,包括个人和公司,如 Databricks,苹果,Linkedin, Facebook,微软,英特尔,阿里巴巴,英伟达,Netflix, Adobe 等。我们在这篇博文中重点介绍了 Spark 中的许多关键 SQL、Python 和流数据改进,但 3.2 里程碑中还有许多其他功能,包括代码生成覆盖率的改进和连接器的增强,您可以在版本中了解更多信息。

开始使用 Spark 3.2
如果您想在 Databricks Runtime 10.0 中试用 Apache Spark 3.2,请注册 Databricks 社区版或 Databricks 试用版,这两者都是免费的,并在几分钟内就可以使用。如果你想自己搭建的话,可以到 这里 下载。
本文翻译自 《Introducing Apache Spark™ 3.2》:https://databricks.com/blog/2021/10/19/introducing-apache-spark-3-2.html