
Mybatis拦截器实现读写分离的思路和实践
说到这里,我们可以再思考一个问题,一般数据库都是主从,也就是很多都是一主多从,对应的就是一写多读,意思是写的时候写到主库,读的时候可以从从库的任意中读取。因此我们的插件要有写库的数据源已经多个读库的数据源。
上边说了那么多,如果没有读写识别的信号,那说的再多也没有价值。这块我们就需要解析SQL或者解析方法上边的特定注解了。前者为一般模式,后者是灵活配置。当然这块要注意的就是事务了,事务肯定要操作单库,也必然是主库,道理说了挺多哈。我们试着研究一下怎么做吧。
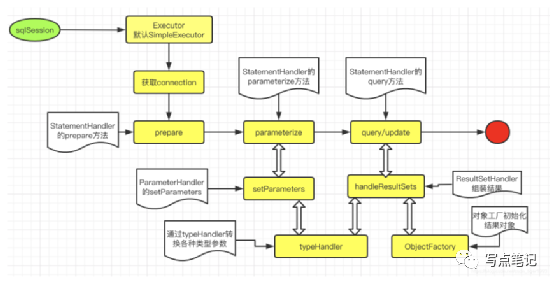
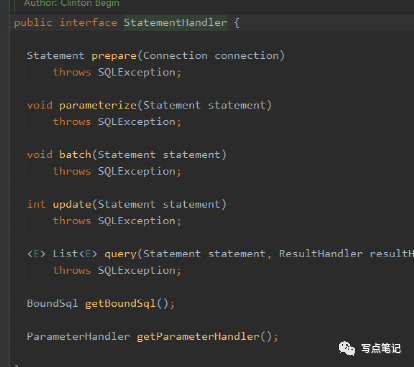
1.首先就是Mybatis插件了,记得之前我们说mybatis有4个阶段(Executor、ParameterHandler、ResultSetHandler 以及 StatementHandler),每个阶段的各个方法都可以被拦截,当然这块拦截器的拦截原理责任链模式,过程还是比较难的。然后通过jdk代理的方式植入到mybatis执行过程中。这块的笔记已经忘的差不多了。再此贴个笔记。
@Intercepts({@Signature(type = StatementHandler.class, method = "prepare", args = {Connection.class,Integer.class})})public class MybatisLanjieqi implements Interceptor {@Overridepublic Object intercept(Invocation invocation) throws Throwable {StatementHandler statementHandler = (StatementHandler) invocation.getTarget();System.out.println(statementHandler.toString());return invocation.proceed();}@Overridepublic Object plugin(Object target) {System.out.println("enter the plugin");if (target instanceof StatementHandler) {return Plugin.wrap(target, this);} else {return target;}}}
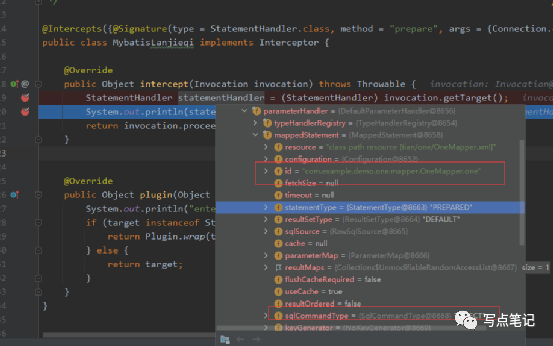
考虑到我们要在代码中灵活决定采用那种类型的数据源,因此我们需要需要将现场的一些东西传过来,比如调用类的信息。当然还有sql的类型什么的。这块我们debug一下。看看我们的StatementHandler中有什么值。

public class MyDataSource extends DruidDataSource {private static DruidDataSource write;private static Listreader;//模拟多库初始化....public static DruidDataSource getDruidDataSource(String url,String userName,String password) throws SQLException {DruidDataSource ds = new DruidDataSource();ds.setUrl(url);ds.setUsername(userName);ds.setPassword(password);try {ds.setFilters("stat,mergeStat,slf4j");} catch (Exception var18) {}ds.setMaxActive(50);ds.setInitialSize(1);ds.setMinIdle(1);ds.setMaxWait(60000);ds.setTimeBetweenEvictionRunsMillis(120000);ds.setMinEvictableIdleTimeMillis(300000);ds.setValidationQuery("SELECT 'x'");ds.setPoolPreparedStatements(true);ds.setMaxPoolPreparedStatementPerConnectionSize(30);ds.setTestWhileIdle(true);ds.setTestOnReturn(false);ds.setTestOnBorrow(false);ds.init();return ds;}static {//初始化write...try {write=getDruidDataSource("jdbc:mysql://127.0.0.1:3306/tianjl?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&transformedBitIsBoolean=true","root","tianjingle");} catch (SQLException throwables) {throwables.printStackTrace();}//初始化读库// reader.add(write);// reader.add(write);// reader.add(write);}public DruidPooledConnection getConnection() throws SQLException {//这块可以写具体得库选择逻辑,读库随机可以从用random方法。return write.getConnection();}}
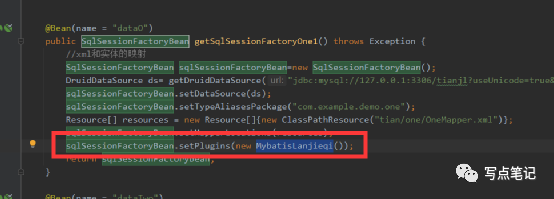
(name = "dataO")public SqlSessionFactoryBean getSqlSessionFactoryOne1() throws Exception {//xml和实体的映射SqlSessionFactoryBean sqlSessionFactoryBean=new SqlSessionFactoryBean();sqlSessionFactoryBean.setDataSource(new MyDataSource());sqlSessionFactoryBean.setTypeAliasesPackage("com.example.demo.one");Resource[] resources = new Resource[]{new ClassPathResource("tian/one/OneMapper.xml")};sqlSessionFactoryBean.setMapperLocations(resources);sqlSessionFactoryBean.setPlugins(new MybatisLanjieqi());return sqlSessionFactoryBean;}(name = "dataTwo")public MapperFactoryBean getSqlSessionFactoryTwo() throws Exception {//xml和实体的映射SqlSessionFactoryBean sqlSessionFactoryBean=new SqlSessionFactoryBean();sqlSessionFactoryBean.setDataSource(new MyDataSource());sqlSessionFactoryBean.setTypeAliasesPackage("com.example.demo.two");sqlSessionFactoryBean.setMapperLocations(new ClassPathResource("tian/two/TwoMapper.xml"));//单个数据源所有的数据库映射MapperFactoryBean mapperFactoryBean=new MapperFactoryBean();//设置sqlSessionTemplate,zhuru yong demapperFactoryBean.setMapperInterface(TwoMapper.class);mapperFactoryBean.setSqlSessionFactory(sqlSessionFactoryBean.getObject());return mapperFactoryBean;}
晚安~
评论