自动驾驶中多模态三维目标检测研究综述 关注 共
6163字,需浏览
13分钟
·
2021-07-09 22:49
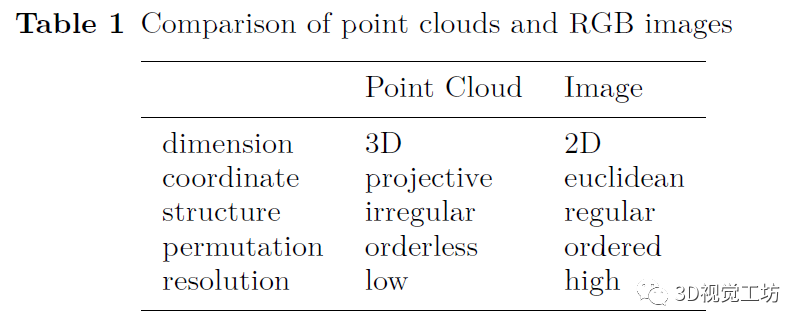
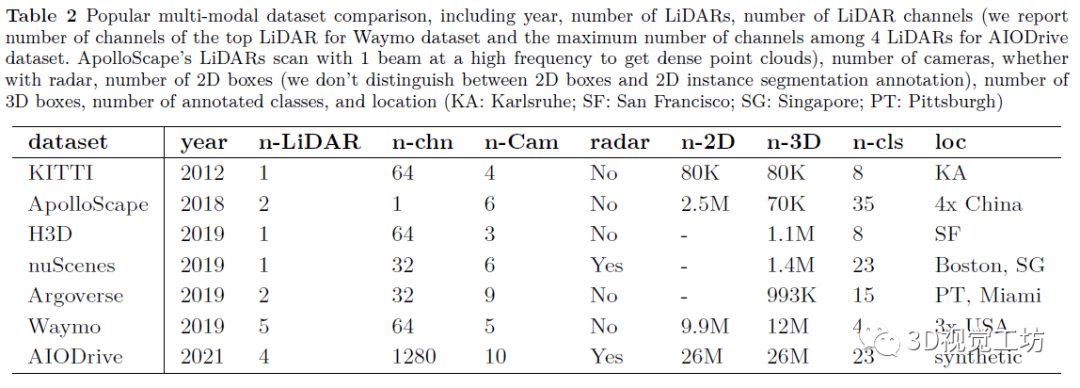
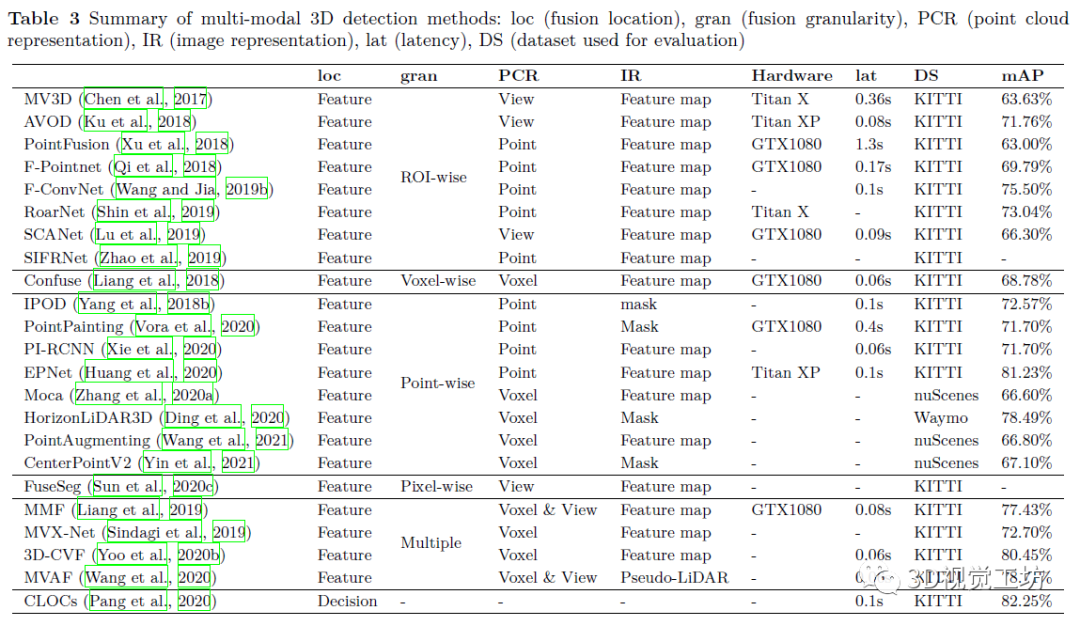
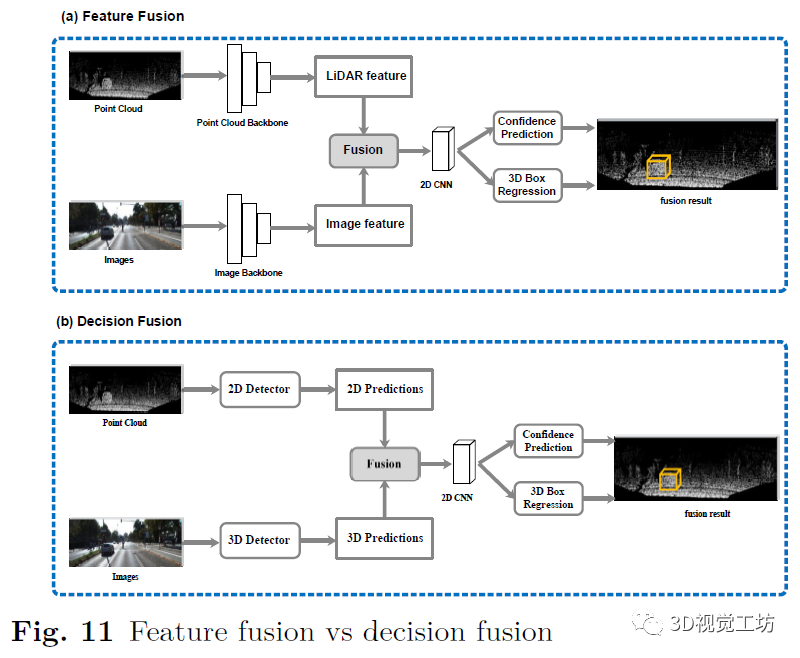
摘要: 过去几年,我们见证了自动驾驶的快速发展。然而,由于复杂和动态的驾驶环境,目前实现完全自动驾驶仍然是一项艰巨的任务。因此,自动驾驶汽车配备了一套传感器来进行强大而准确的环境感知。随着传感器的数量和类型不断增加,将它们融合来更好地感知环境正在成为一种趋势。到目前为止,还没有文章对基于多传感器融合的3D目标检测进行深入调研。为了弥合这一差距并推动未来的研究,本文致力于回顾最近利用多个传感器数据源(尤其是相机和 LiDAR)的基于融合的 3D 检测深度学习模型。首先,本文介绍了自动驾驶汽车中常用的传感器,包括它们的通用数据表示以及基于每种类型的传感器数据的3D目标检测网络。接下来,我们讨论一些多模态3D目标检测中流行的数据集,重点介绍每个数据集中包含的传感器数据。然后我们从三个方面来深入回顾最近的多模态3D检测融合网络:融合位置 、融合数据表示 和融合粒度 。最后,本文总结了现有的开放式挑战并指出可能的解决方案。 1. 引言 如图1,自动驾驶汽车(AV)通常配备一个感知子系统来实时检测和跟踪运动目标。感知子系统是将来自一组传感器的数据作为输入,经过一系列的处理步骤后,输出关于环境、其他物体(如汽车)以及自动驾驶汽车本身的知识。如图2所示,AV上的传感器通常包括摄像头、激光雷达(Light Detection And Ranging sensor,LiDAR)、雷达(Radio detection and ranging,Radar)、GPS(Global Positioning System)、惯性测量单元(inertial measurement units)等。 首先,它需要是准确 的,并给出了驾驶环境的准确描述。 其次,具有鲁棒性。 能在恶劣天气下、甚至当一些传感器退化甚至失效时保证AV的稳定与安全。 为了满足上述需求,感知子系统同时执行多个重要任务,如3D目标检测、跟踪、同步定位与映射(SLAM)等。 3D目标检测是感知子系统的一项重要任务,其目的是在传感器数据中识别出所有感兴趣的物体,并确定它们的位置和类别(如车辆、自行车、行人等)。在3D目标检测任务中,需要输出参数来指定物体周围的面向3d的边界框。如图3所示,为了绘制红色的三维包围盒,我们需要预测中心三维坐标c,长度l,宽度w,高度h,物体偏转角度θ。显然,2D目标检测无法满足自动驾驶环境感知的需求,因为缺少现实三维空间下的目标位置。接下来介绍自动驾驶的3D目标检测任务,根据传感器的使用类型,包括使用相机、使用LiDAR以及使用Radar等一些单模态方法。在第二章中会详细介绍。 在现实的自动驾驶情况下,通过单一类型的传感器进行目标检测是远远不够的。首先,每种传感器都有其固有的缺点。例如,Camera only方法易遭受物体遮挡;LiDAR only方法的缺点是输入数据的分辨率比图像低,特别是在远距离时点过于稀疏。图4清楚地展示了两种单模态检测失效的情况。其次,要实现真正的自动驾驶,我们需要考虑广泛的天气、道路和交通条件。感知子系统必须在所有不同的条件下都能提供良好的感知结果,这是依靠单一类型的传感器难以实现的。 图4:单模态探测器典型问题的说明。对于场景#1,(a)表示Camera only无法避免遮挡问题,(b)中LiDAR only检测器检测结果正确;而在场景2中,(c)中Camera only的检测器表现良好,而(d)中LiDAR only检测器显示了远处点云稀疏时检测的难度。请注意,虚线红框表示未探测目标 为了解决这些挑战,多模态融合的3D检测方法被提出。虽然传感器融合带来了可观的好处,但如何进行高效的融合对底层系统的设计提出了严峻的挑战。一方面,不同类型的传感器在时间和空间上不同步;在时域上,由于不同传感器的采集周期是相互独立的,很难保证同时采集数据。在空间领域,传感器在部署时具有不同的视角。另一方面,在设计融合方法时,我们需要密切关注几个问题。下面我们列举了一些问题作为例子。 多传感器校准和数据对齐 信息丢失: 跨模态数据增强: 数据集与评价指标: 我们对最近基于深度学习的多模态融合3D目标检测方法进行了系统的总结。特别地,由于摄像头和LiDAR是自动驾驶中最常见的传感器,我们的综述重点关注这两种传感器数据的融合。 根据输入传感器数据的不同组合,对基于多模态的3D目标检测方法进行分类。特别是range image(点云的一种信息完整形式)、pseudo-LiDARs (由相机图像生成),在过去的综述文章中没有进行讨论。 从多个角度仔细研究了基于多模态的3D目标检测方法的发展。重点关注这些方法如何实现跨模态数据对齐,如何减少信息损失等关键问题。 对基于深度学习的相机-LiDAR融合的方法进行详细对比总结。同时,我们还介绍了近年来可用于3D目标检测的多模态数据集。 仔细探讨具有挑战性的问题,以及可能的解决方案,希望能够启发一些未来的研究。 2. 背景 在本节中,我们将提供自动驾驶中使用的典型传感器的背景概述,包括基于于每种传感器的数据表示和3D目标检测方法。其中,我们主要讨论相机和激光雷达传感器。最后,介绍了其他的一些传感器。 相机的得到的数据是图像。在多模态融合方法中,对于图像的处理形式,有以下几种表示。 图5:RGB图像及其典型数据表示。原始图像来自KITTI训练集。对于(b),使用预先训练的AlexNet获取64个通道的特征图。对于(d),我们采用伪点云的BEV来更好的显示 由于点云数据是不规则的和稀疏的,找到一个合适的点云表示对于高效的处理是很重要的。大多数现有的处理形式可以分为三大类:体素、点和视图。 图6:原始点云及其典型数据表示。我们从KITTI训练集中得到原始点云 AV其他的传感器包括如Radar,红外相机等等。这里我们主要介绍毫米波雷达(mmRadar)。我们使用原始收集的雷达数据进行可视化。如图7所示,对原始数据进行两次快速傅里叶变换,得到图像对应的距离-方位热图。(b)中的亮度表示该位置的信号强度,也表明物体出现的概率很高。 图7:同一场景上的RGB图像(a)和毫米波雷达热图(b)。数据是在中国科学技术大学西校区北门收集的。 3. 数据集与评价指标 数据集是有效进行深度学习研究的关键。特别是,像3D目标检测这样的任务需要精细标记的数据。在这一部分,我们讨论了一些广泛使用的自动驾驶3D目标检测数据集。并且进行了详细地比较,包括年份,激光雷达数量,激光雷达通道数量、摄像头的数量,是否带有雷达,2D盒子的数量(不区分2D盒子和2D实例分割注释),3D盒子的数量,标注的类的数量,以及位置。具体如表2所展示。 另外,大多数基于深度学习的多模态融合方法都是在KITTI、nuSecenes、Waymo上进行实验的。从图8,我们观察到三个流行的数据集的大小从只有15,000帧到超过230,000帧。与图像数据集相比,这里的数据集仍然相对较小,对象类别有限且不平衡。图8也比较了汽车类、人类和自行车类的百分比。有更多的物体被标记为“汽车”比“行人”或“自行车”。 图8:KITTI、nuScenes和Waymo开放数据集的比较 4. 基于深度学习的多模态3D检测网络 在本节中,我们介绍了基于多模态融合的3D检测网络。我们通过考虑以下三个融合策略中的重要因素来组织我们的文章:(1)融合位置 ,即多模态融合在整个网络结构中发生的位置;(2)融合输入 ,即每个传感器使用什么数据表示进行融合;(3)融合粒度 ,即多个传感器的数据在什么粒度进行融合检测。 其中,融合位置是区分融合方法的最重要因素。一般来说,我们有两种可能的融合位置,如图9所示:特征融合 和决策融合 。特征融合是将不同模态的特征组合起来得到检测结果,而决策融合则是将每个单独的检测结果组合起来。下面,我们首先回顾了特征融合方法,然后讨论了决策融合方法。注意,由于融合方法的设计与数据集的选择是正交的,因此我们将一起讨论KITTI、Waymo和nuScenes数据集的融合方法。其中,大多数多模态三维检测方法都是在KITTI上进行评价的。从表3的评价总结中,可以清楚地看出该方法适用于哪些数据集。 特征融合在神经网络层中分层混合模态。它允许来自不同模式的特性在层上相互交互。特征融合方法需要特征层之间的相互作用,如图9 (a)所示。这些方法首先对每个模态分别采用特征提取器,然后结合这些特征实现多尺度信息融合。最后,将融合后的特征输入神经网络层,得到检测结果。 许多融合方法都属于这一类。我们基于传感器数据的不同组合,将这些方法分成以下几类。 Point cloud view & image feature map point cloud voxels & image feature map LiDAR points & image feature map LiDAR points & image mask: point cloud voxels & image mask point cloud voxels & point cloud view & image feature map point cloud voxels & image feature map & image pseudo-LiDAR 此外,在特征融合方法中,我们还需要关注融合粒度。具体来说,特征融合可以在不同粒度上进行,即RoI-wise、voxel-wise、point-wise和pixel-wise。图10总结了基于深度学习的多模态三维检测方法出现的年份,并对每种方法的融合粒度进行了标记。我们观察到,早期方法融合粒度比较粗糙,主要使用RoI和voxel。随着多模态目标检测技术的快速发展,融合粒度越来越细,融合种类越来越多,检测性能不断提高。 图10:特征融合3D目标检测方法的时间轴。用不同的颜色来标记它们的融合粒度。 在决策融合中,多模态数据被单独、独立地处理,融合发生在最后的决策阶段。这种方法的思想通常是利用神经网络对传感器数据进行并行处理,然后将得到的所有决策输出进行融合,得到最终结果。与特征融合相比,决策融合可以更好地利用现有网络对每个模态的影响,并且我们可以很容易地知道每个模态的结果是否正确。然而,从表4可以看出,一个不能忽视的严重缺点是不能使用丰富的中间层特征。因此,决策融合直到最近才受到人们的重视。 综上所述,大多数融合方法都是基于KITTI 3D基准,但在KITTI 3D目标检测排行榜上排名靠前的方法主要是LiDAR-only方法。在KITTI数据集上,多模态方法的效果并不好。相反,在最新数据集如nuScenes和Waymo Open Dataset上,排名靠前的方法主要是多模态融合的方法。一个可能的原因是这些数据集中使用的LiDAR传感器具有不同的分辨率。KITTI使用一个64通道的LiDAR,nuScenes使用一个32光束的LiDAR。因此,当点云相对稀疏时,多模态方法更有用。更重要的是,最近的融合方法有一些共同的特点。一方面,它们都采用point-wise的融合粒度来有效地建立激光雷达点与图像像素之间的精确映射;另一方面,在训练融合网络的过程中,都进行了精心设计的跨模态数据增强,不仅加快了网络的收敛速度,而且缓解了类间的不平衡问题 我们还简单讨论了针对其他类型传感器的融合方法,如Radar-相机,LiDAR-Radar等。 5. 开放式挑战与可能的解决方案 在本节中,我们将讨论多模态3D目标检测的开放式挑战和可能的解决方案。我们重点讨论了如何提高多传感器感知系统的准确性和鲁棒性,并同时实现系统的实时性。表6总结了我们的讨论。包括以下几个关键问题。 6. 总结 由于3D视觉在自动驾驶等应用中的重要性日益增加,本文综述了近年来的多模态3D目标检测网络,特别是相机图像和激光雷达点云的融合。我们首先仔细比较了常用的传感器,讨论了它们的优缺点,总结了单模态方法的常见问题。然后,我们提供了几个常用的自动驾驶数据集的深入总结。为了给出一个系统的回顾,我们考虑以下三个维度对多模态融合方法进行分类:(1)融合在管道中发生的位置;(2)每个融合输入使用什么数据表示;(3)融合算法的粒度是什么。最后,我们讨论了在多模态3D目标检测中的开放式挑战和潜在的解决方案。 文章链接:https://arxiv.org/abs/2106.12735 初衷 优质原创文章 的自媒体平台,创始人和合伙人致力于发布3D视觉领域最干货的文章,然而少数人的力量毕竟有限,知识盲区和领域漏洞依然存在。为了能够更好地展示领域知识,现向全体粉丝以及阅读者征稿,如果您的文章是3D视觉 、CV&深度学习 、SLAM 、三维重建 、点云后处理 、自动驾驶、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、硬件选型、求职分享等方向, 欢迎砸稿过来~文章内容可以为paper reading、资源总结、项目实战总结 等形式,公众号将会对每一个投稿者提供相应的稿费 ,我们支持知识有价!投稿方式 邮箱:vision3d@yeah.net 或者加下方的小助理微信,另请注明原创投稿。 浏览
173
分享
手机扫一扫分享
分享
手机扫一扫分享