
CNN网络结构发展最全整理

来源:人工智能AI技术 本文约2500字,建议阅读9分钟
本文为你整理CNN网络结构发展史。
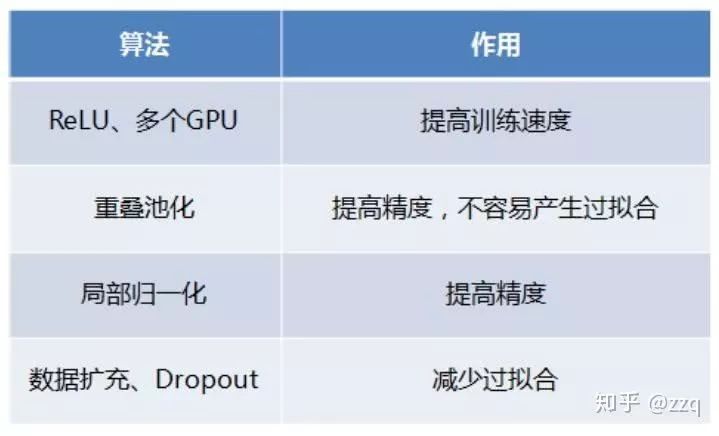
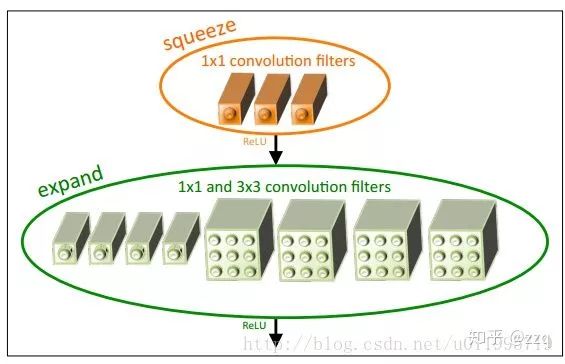
CNN基本部件介绍
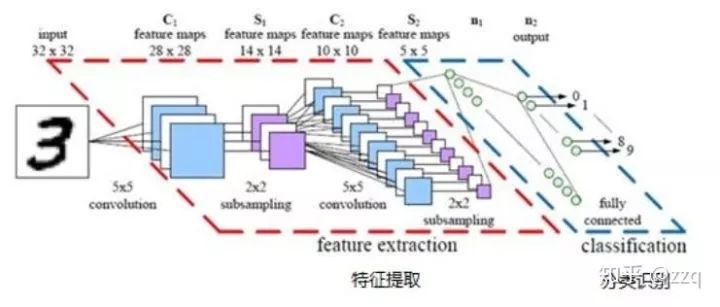
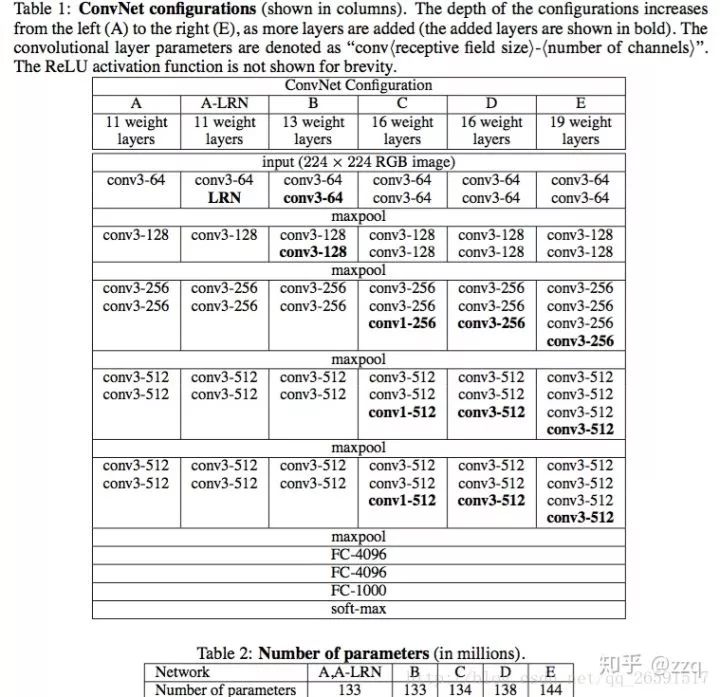
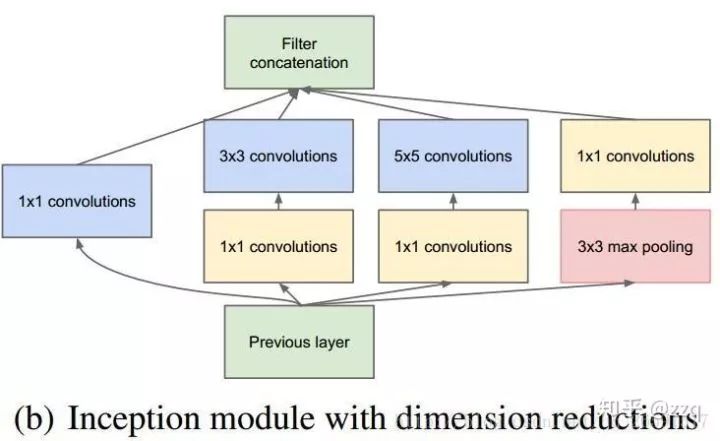
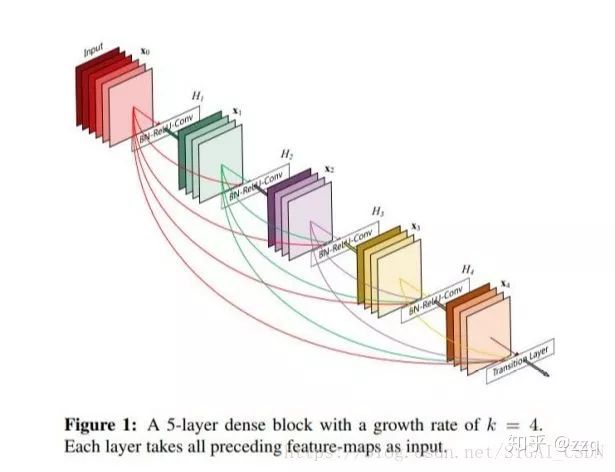
经典网络结构

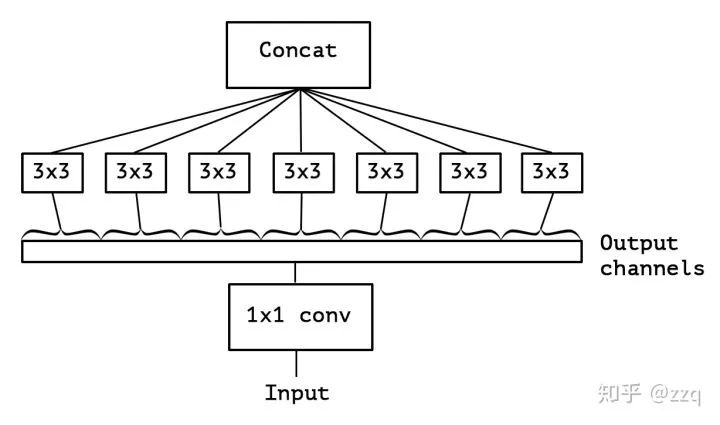
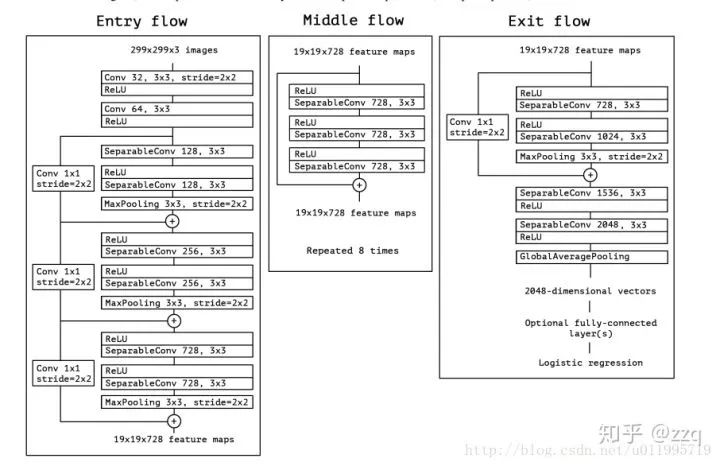

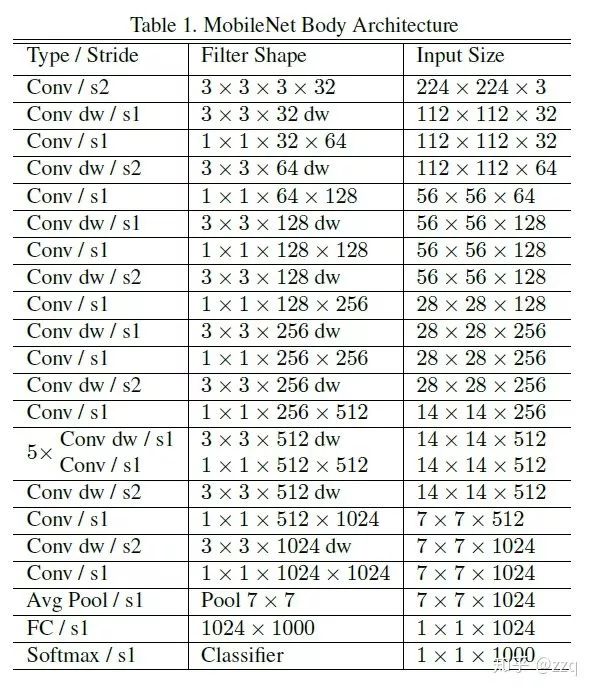
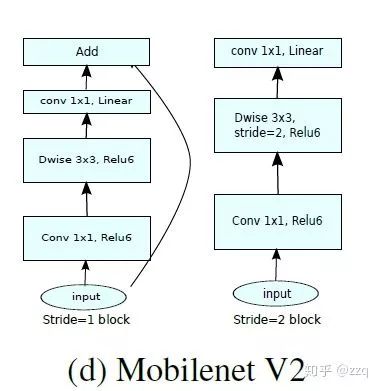
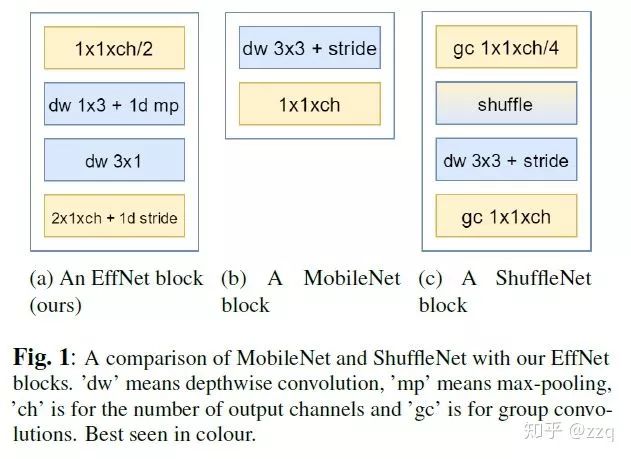
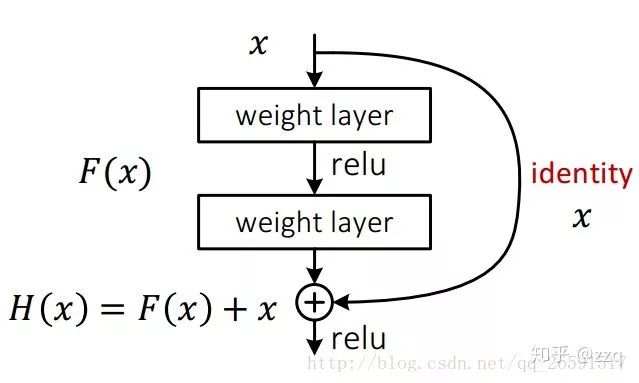
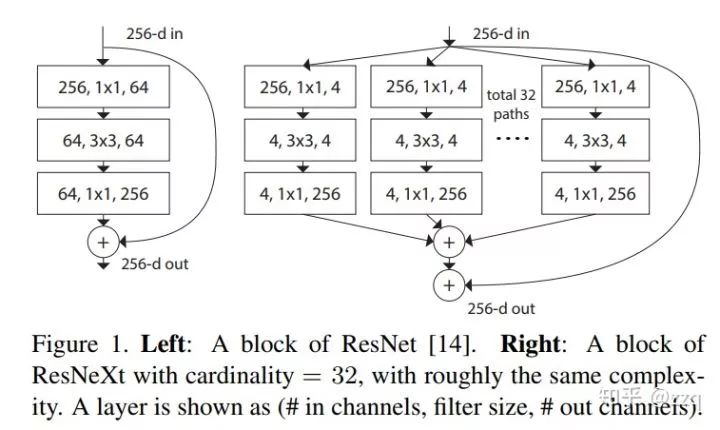
引入了残差结构;
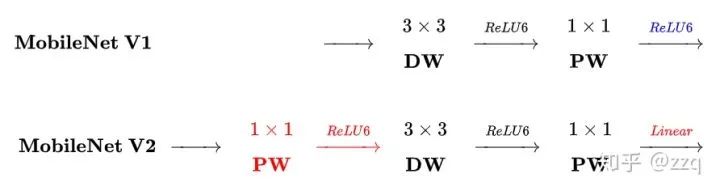
在dw之前先进行1×1卷积增加feature map通道数,与一般的residual block是不同的;
pointwise结束之后弃用ReLU,改为linear激活函数,来防止ReLU对特征的破坏。
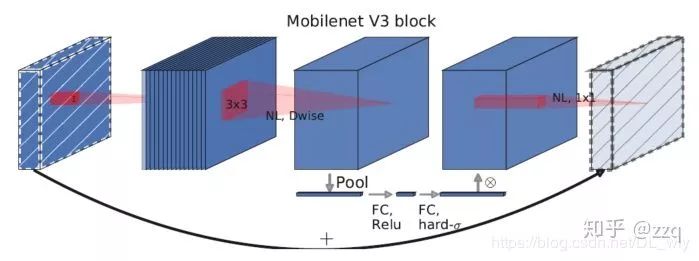
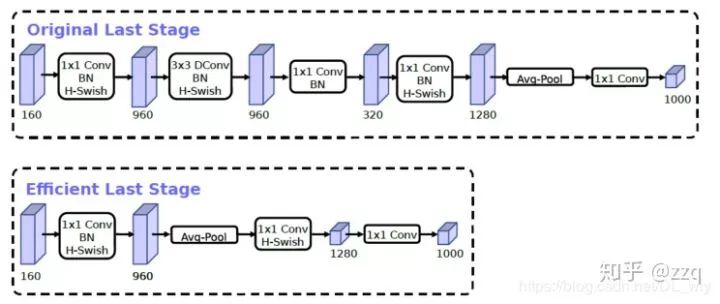
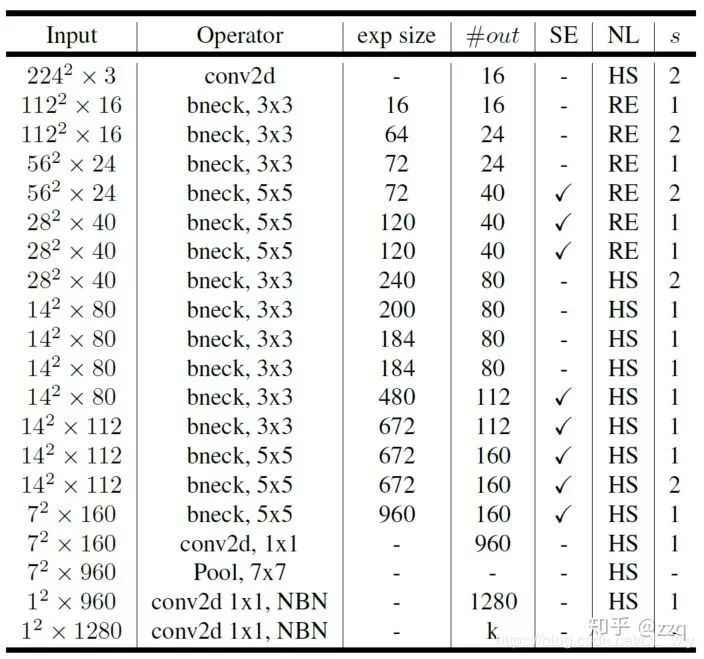
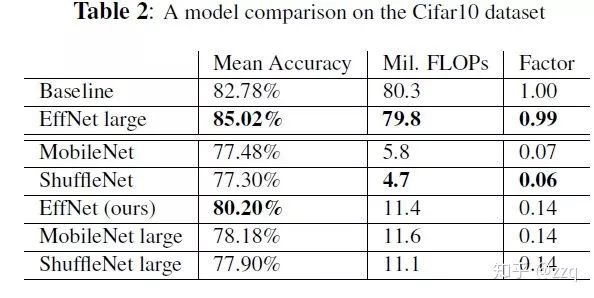
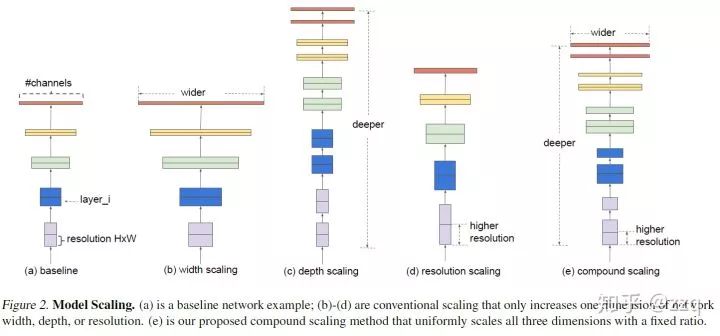
增加网络深度,如从AlexNet到ResNet,但是实验结果表明由网络深度带来的提升越来越小;
增加网络模块的宽度,但是宽度的增加必然带来指数级的参数规模提升,也非主流CNN设计;
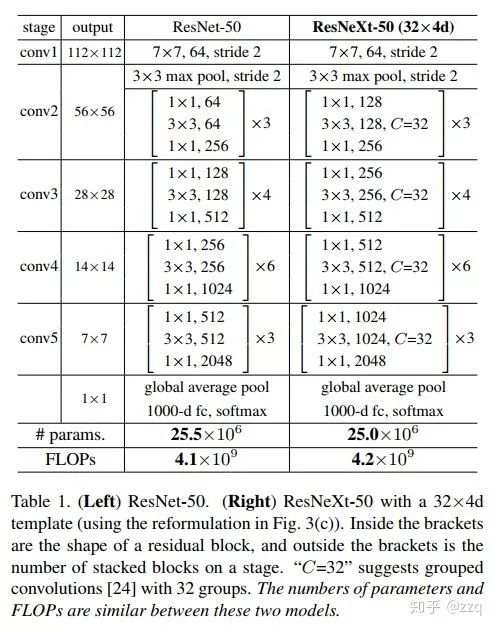
改善CNN网络结构设计,如Inception系列和ResNeXt等。且实验发现增加Cardinatity即一个block中所具有的相同分支的数目可以更好地提升模型表达能力。
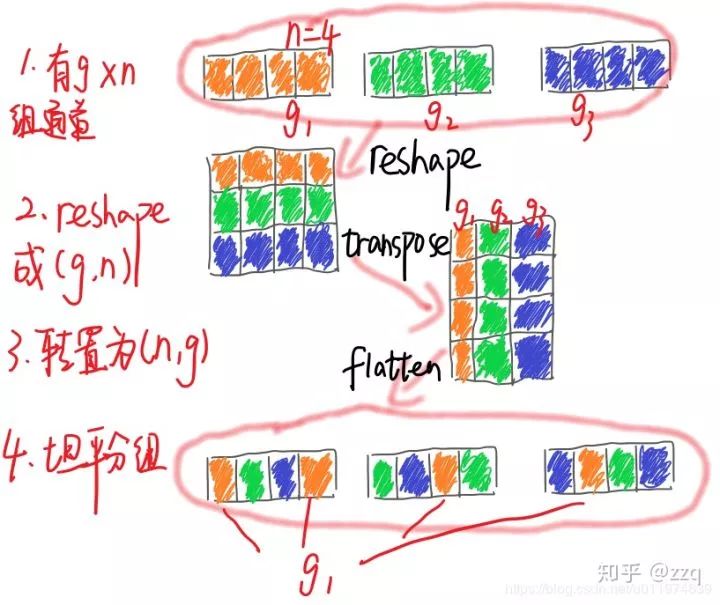
输入通道数与输出通道数保持相等可以最小化内存访问成本;
分组卷积中使用过多的分组会增加内存访问成本;
网络结构太复杂(分支和基本单元过多)会降低网络的并行程度;
element-wise的操作消耗也不可忽略。
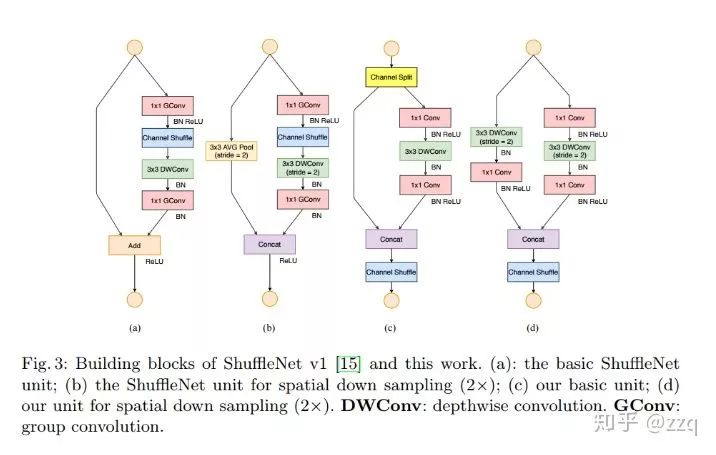
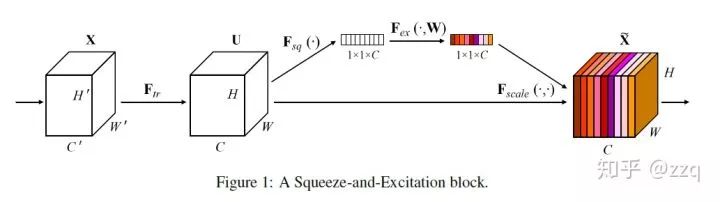
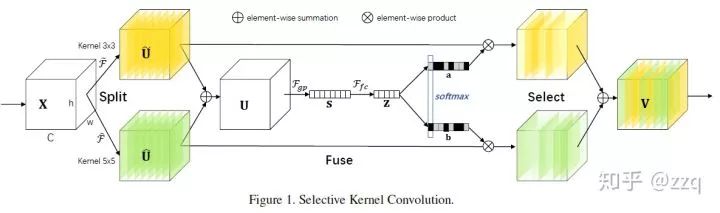
评论