
认识数据结构之【链表】
认识数据结构之【链表】
认识数据结构系列往期文章:
回顾数组元素的访问
name 的第5个元素,我们可以使用下标来获取,例如 name[4]。#include <stdio.h>int main(){unsigned int numbers[] = {100, 200, 300, 400, 500};printf("单个unsigned int所占字节数:%d\n", sizeof(unsigned int));printf("numbers数组所占字节数:%d\n", sizeof(numbers));printf("数组numbers的元素个数:%d\n\n", sizeof(numbers) / sizeof(unsigned int));printf("numbers的指针地址:0x%x\n\n", &numbers);printf("元素numbers[0]的指针地址:0x%x\n", &numbers[0]);printf("元素numbers[1]的指针地址:0x%x\n", &numbers[1]);printf("元素numbers[2]的指针地址:0x%x\n", &numbers[2]);printf("元素numbers[3]的指针地址:0x%x\n", &numbers[3]);printf("元素numbers[4]的指针地址:0x%x\n", &numbers[4]);return 0;}
单个unsigned int所占字节数:4numbers数组所占字节数:20数组numbers的元素个数:5numbers的指针地址:0xc48df320元素numbers[0]的指针地址:0xc48df320元素numbers[1]的指针地址:0xc48df324元素numbers[2]的指针地址:0xc48df328元素numbers[3]的指针地址:0xc48df32c元素numbers[4]的指针地址:0xc48df330
注:您自己运行的结果地址应该和上面是不一样的。
•每个 unsigned int 占四个字节•numbers 数组所占字节数 = 单个 unsigned int 所占字节 * numbers 数组元素个数•数组 numbers 的内存地址和 其第一个元素 numbers[0] 的地址相同•numbers 每两个相邻元素的地址相差一个 unsigned int 的长度
numbers 数组在内存中应该是如下图的样子:
numbers[2] 的值,则可以通过如下方式获取:numbers指针地址0xc48df320 + 单个unsigned int的长度4 * 2 = 0xc48df320 + 8 = 0xc48df328
内存 [0xc48df328 , 0xc48df32c) 之间的数据就是 number[2] 的值
链表
链表的定义
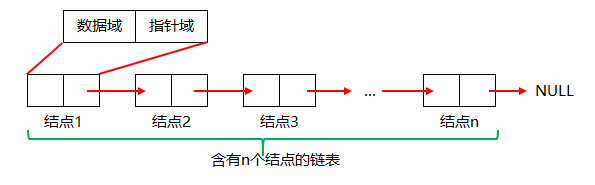
链表的特点
链表的分类
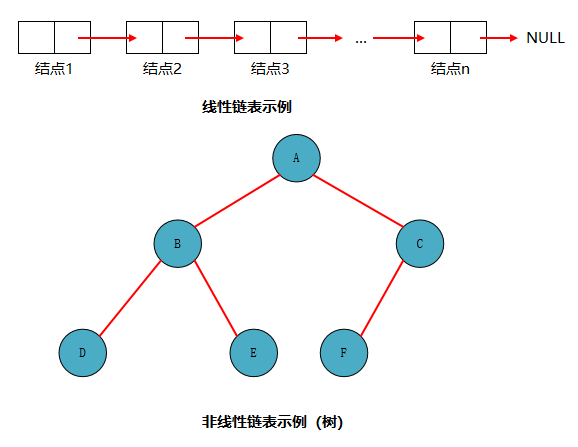
线性链表(单链表)和非线性链表
•由分别表示 结点1,结点2,…,结点N的N个结点依次相链构成的链表,称为线性表的链式存储表示。由于此类链表的每个结点中只包含一个指针域,故又称单链表或线性链表。•非线性的链表,可以参见相关的其他数据结构,例如树、图。对比线性链表的定义可知,非线性链表的每个结点可能会包含多个指针域。
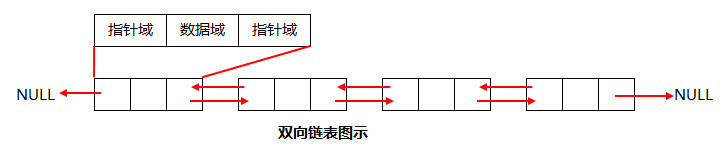
双向链表
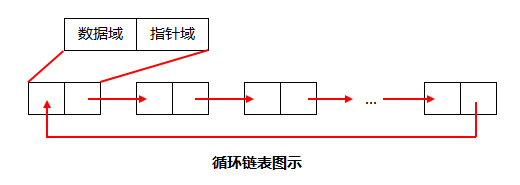
循环链表
1.在建立一个循环链表时,必须使其最后一个结点的指针指向表头结点,而不是象单链表那样置为NULL。此种情况还使用于在最后一个结点后插入一个新的结点。2.在判断是否到表尾时,是判断该结点链域的值是否是表头结点,当链域值等于表头指针时,说明已到表尾。而非象单链表那样判断链域值是否为NULL。
循环链表的举例:约瑟夫还问题,感兴趣的朋友可以自己查找相关资料了解一下。
问题来源:
据说著名犹太历史学家Josephus有过以下的故事:在罗马人占领乔塔帕特后,39 个犹太人与Josephus及他的朋友躲到一个洞中,39个犹太人决定宁愿死也不要被敌人抓到,于是决定了一个自杀方式,41个人排成一个圆圈,由第1个人开始报数,每报数到第3人该人就必须自杀,然后再由下一个重新报数,直到所有人都自杀身亡为止。然而Josephus 和他的朋友并不想遵从。首先从一个人开始,越过k-2个人(因为第一个人已经被越过),并杀掉第k个人。接着,再越过k-1个人,并杀掉第k个人。这个过程沿着圆圈一直进行,直到最终只剩下一个人留下,这个人就可以继续活着。问题是,给定了和,一开始要站在什么地方才能避免被处决。Josephus要他的朋友先假装遵从,他将朋友与自己安排在第16个与第31个位置,于是逃过了这场死亡游戏。
链表的操作
遍历
•对于线性链表的遍历很容易。因为每个结点上有指向下一个结点的指针域,通过指针可以很容易的遍历完整个链表。•对于非线性链表的遍历稍微复杂一些,因为每个结点指向下一个结点的指针域有多个,这些多个指针域的遍历顺序不一样则遍历出来的结果也不一样。此处不多说了,关于树的遍历可以点击文末关于树的文章链接查看•对于循环链表来说,需要注意的是如何决定终止条件,而使遍历不会变成一个死循环
插入结点
结点A 和 结点C 之间插入 结点B,则仅仅需要把 结点A 的指针域指向 结点B,并且把 结点B 的指针域指向 结点C 即可。
删除结点
A -> B -> C 这样的链表中的 结点B 删除仅仅需要将 结点A 的指针域指向 结点C 即可。结点B 指向 结点C 的指针域可以根据你的需要来决定是否删除,不管删除与否这都不影响在原来的链表中已经移除了结点B。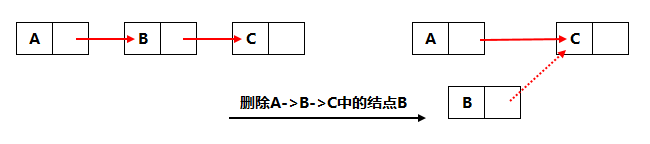
最后
大家下期见~(●ˇ∀ˇ●)
往期文章:
欢迎关注我的公众号“须弥零一”,原创技术文章第一时间推送。