压测暴露的OpenJDK Bug排查实战
点击上方“服务端思维”,选择“设为星标”
回复”669“获取独家整理的精选资料集
回复”加群“加入全国服务端高端社群「后端圈」
为了持续保障前台业务的服务稳定、性能稳定,京东零售-平台业务中心建设了线上流量录制能力,要求测试、研发团队对于前台业务进行常态化流量回放压测,常态化压测任务以周、日为周期。京东主站日历模块SOA服务是京东主APP活动日历的服务端,测试同学反馈用于常态化压测机器的压测性能出现了大幅度衰减,而且这个衰减过程是突然发生的,在3月30日还是正常的,但是3月31日在同等压测设置情况下CPU使用率达到了90%以上,且QPS大幅度下降,可用率也出现了下降的情况。
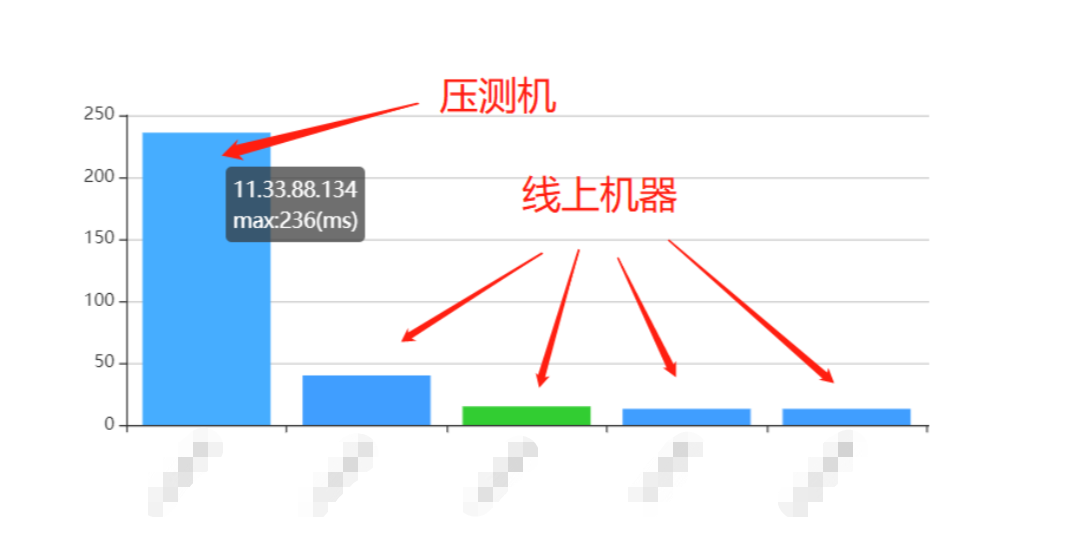
3月30日到3月31日的压测情况具体情况可以看下图:
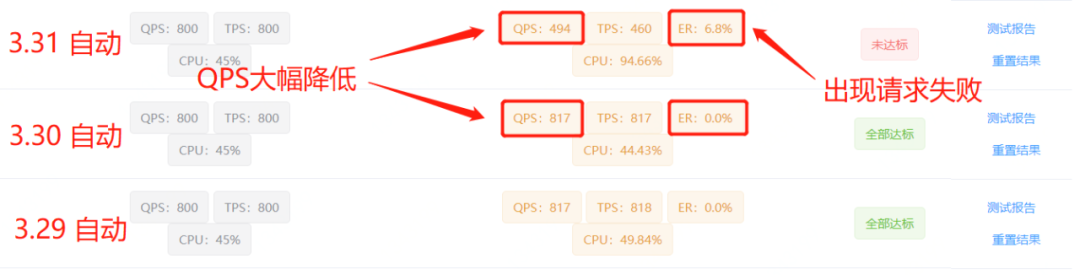
出现这个问题后,测试同学在3月31日进行了反馈,由于线上其他机器没有任何异常现象,且我们在这段时间内没有进行上线、配置修改等,因此我们认为本次可能是偶发的问题,简单排查UMP监控后发现并无异常现象,并没有进行深入排查。
在4月1日愚人节这天,又收到测试同学反馈常态化压测未达标,这时我们意识到问题并没有想象中的简单,但是由于压测机只有压测时才会有请求,压测的时间只会持续5分钟,因此无法直接复现问题现场,因此我们决定手动触发常态化压测,进行问题现场的复现。
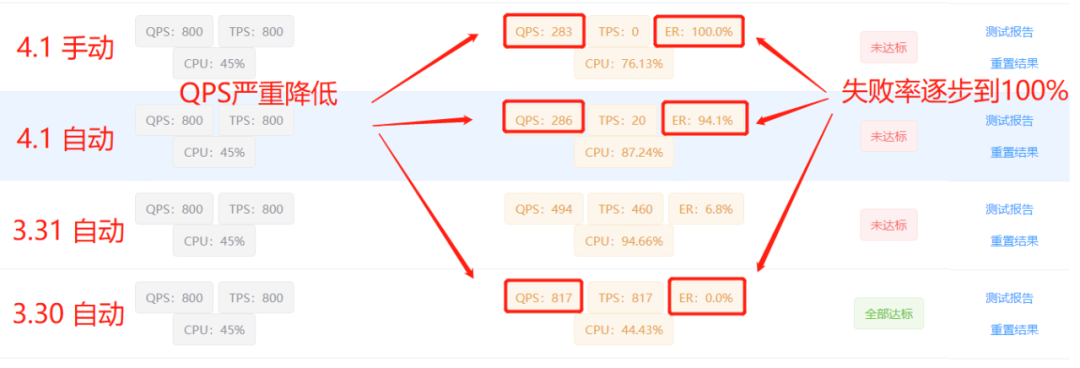
手动触发流量回放压测任务以后,发现本次失败了达到了100%,这说明此时服务已经进入了不可用状态,由此推断出这并不是一个偶现的问题,而是一个存在于线上的问题。但是此时又出现了一个问题,为什么线上其他机器并没有出现任何问题,而只有单独拿出来的压测机出现了问题?
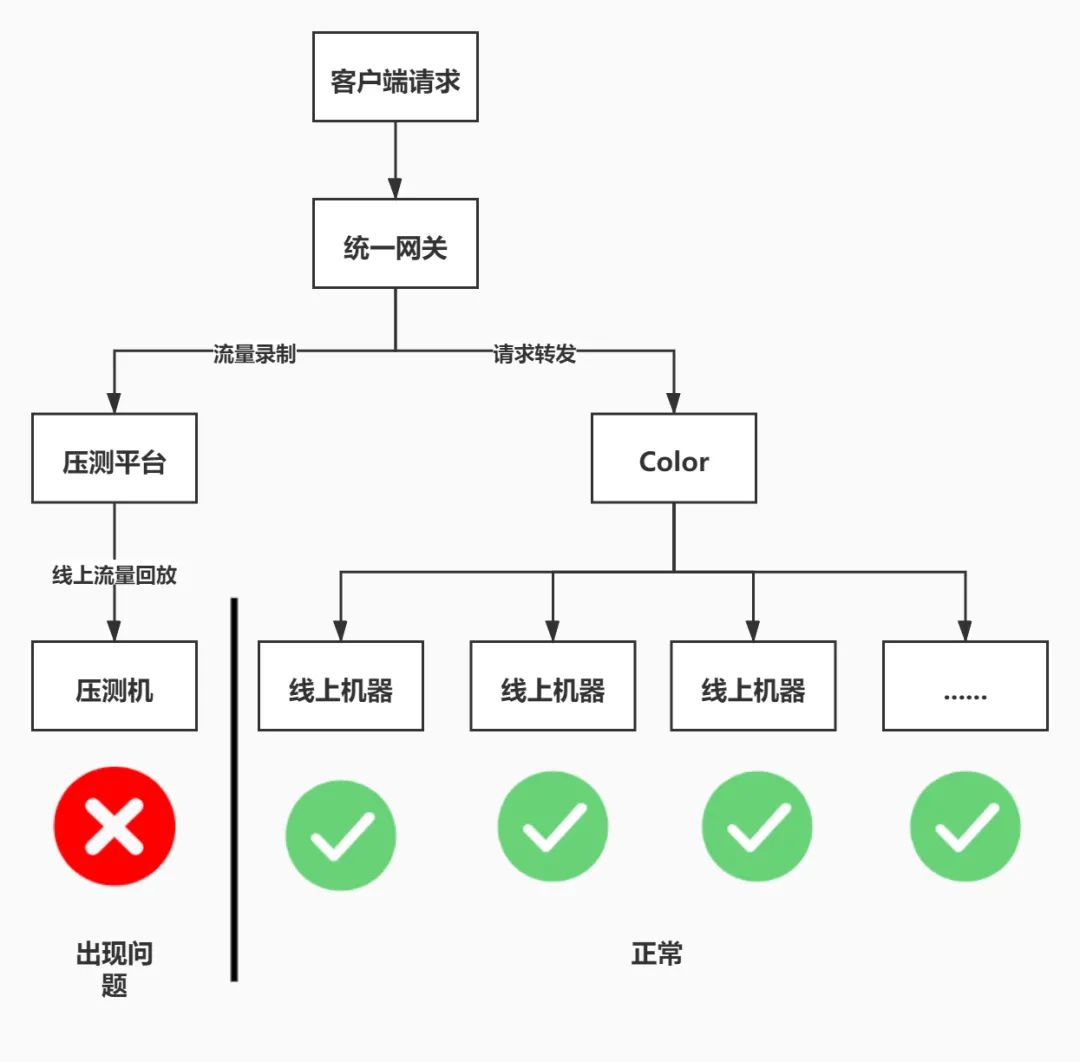
首先我们分析了常态化压测的四个接口,其中接口A、B几乎没有业务逻辑,只是单纯的取了配置平台的配置项,而DUCC平台的配置项可以视为JVM内部的本地缓存,而且DUCC也是我们长期使用的配置平台,在稳定性和性能方面非常的优秀,因此排除怀疑这两个接口。而对于接口C和D,则是直接调用了上游接口,这里我们首先怀疑是因为上游接口性能出现了问题,导致了接口C和D出现了性能问题。
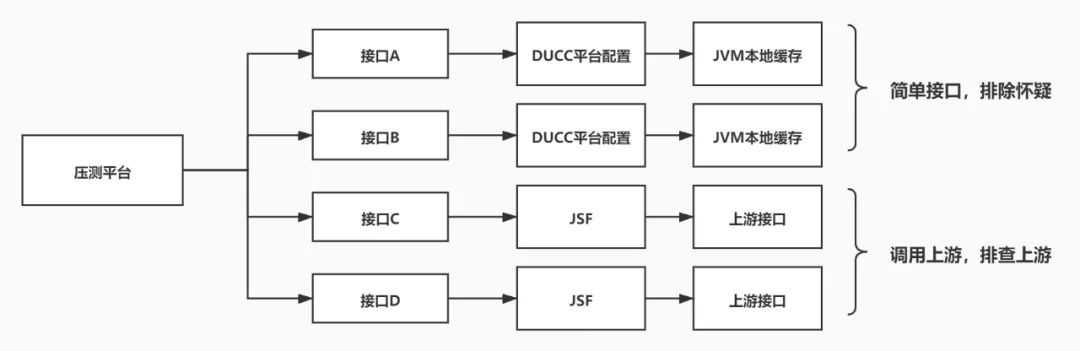
因此我们对接口C和D的UMP监控点进行了排查,项目中按照传统的分层模式分为了Controller层、Service层和Rpc层,每一层级都有单独的监控点,但是经过排查三层监控点,发现可用率是100%且请求得TP999也只有236ms。
这个现象让我们很诧异,为什么系统内监控点可用率100%且接口请求耗时Max只有236ms,HTTP接口却进入了一种不可用状态?
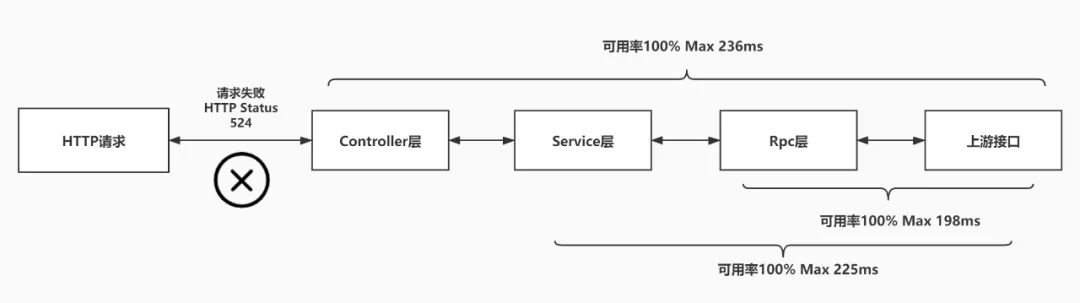
这里HTTP请求返回了99%以上的错误码是524,HTTP错误码524代表TCP握手完成但是却没有及时收到HTTP响应。
排查到这里,似乎进入了一个僵局,项目内部的监控点并没有出现问题,但是服务器却不能响应请求。这时我们怀疑是这台机器的Tomcat服务器出现了问题,因此产生了重启服务器的想法(幸亏没有这样做),但是当时考虑到如果重启问题可能就不能复现,因此决定继续在问题现场进行排查。
这时想到了UMP-Pfinder提供的调用链监控能力,通过查找压测机器的请求找到了当时的调用链详情。
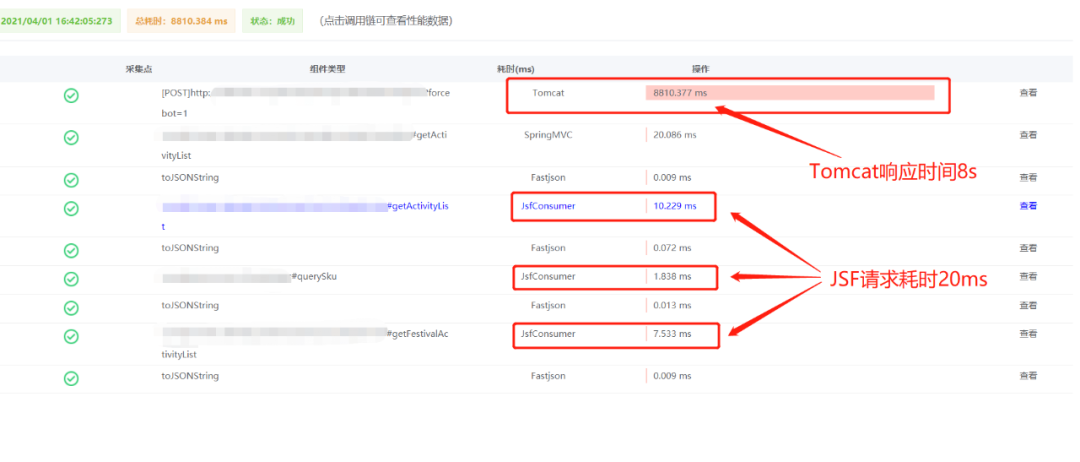
可以看到,接口调用JSF接口耗时总共只有20ms,但是Tomcat处理这次HTTP请求却耗时8s。这时候事情好像有了一些眉目,因为我们项目内的监控点,只能监控到Controller层的请求耗时,但实际上,Controller层的方法完成调用返回后,是交给SpringMVC框架处理,SpringMVC框架会进行一些HTTP报文的数据封装,而SpringMVC框架也是继承实现了Servlet-API,最终完成收发HTTP报文的则是被称为container(容器)的软件,就比如我们常用的Tomcat、Jetty等,实际上的调用路径如下图:
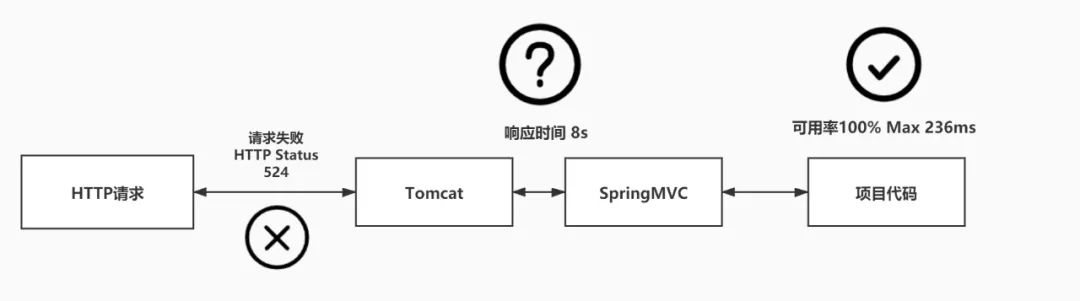
既然系统内监控点没有异常,而本次HTTP请求出现了问题,那么是不是有可能SpringMVC框架或者Tomcat出现了Bug呢?
虽然怀疑是SpringMVC或者Tomcat出了问题,但是也并没有太好的切入点去排查,因此还是需要从压测机器的JVM状况排查,首先我们通过UMP提供的JVM监控能力,发现最后一次手动触发压测任务时,JVM的GC情况、堆内存情况一切正常,CPU使用率也只有75%左右。
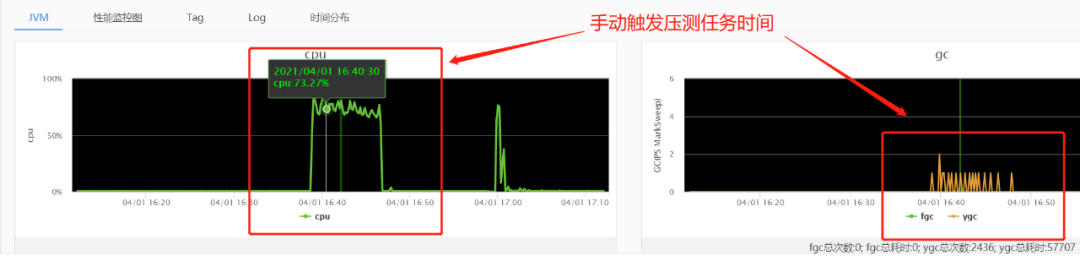
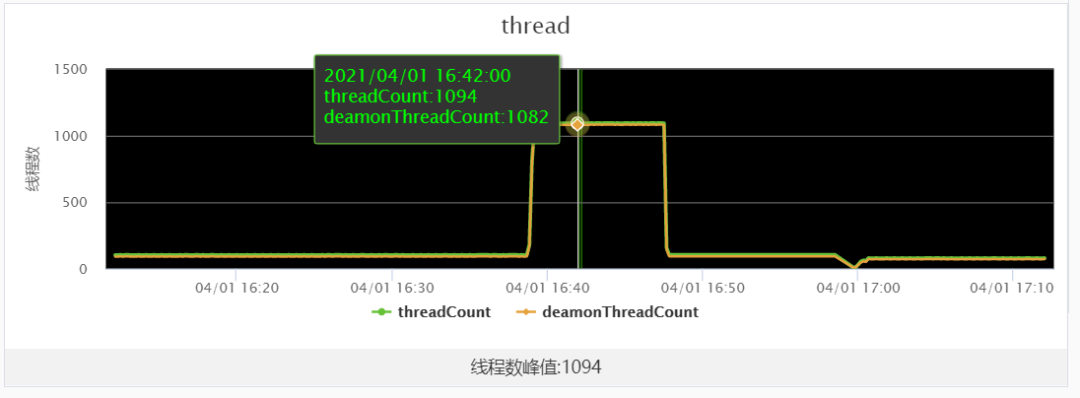
但是同比之前压测时间段内,我们发现VM的线程数由200个以内激增到了1000多个,因此我们重启了压测任务,在任务执行期间对压测机使用jstack工具dump了线程堆栈。
有了线程堆栈Dump样本以后,我们开始对线程进行分析,分析线程堆栈的工具有很多,这里我们选用了perfma提供的社区产品分析线程状态。
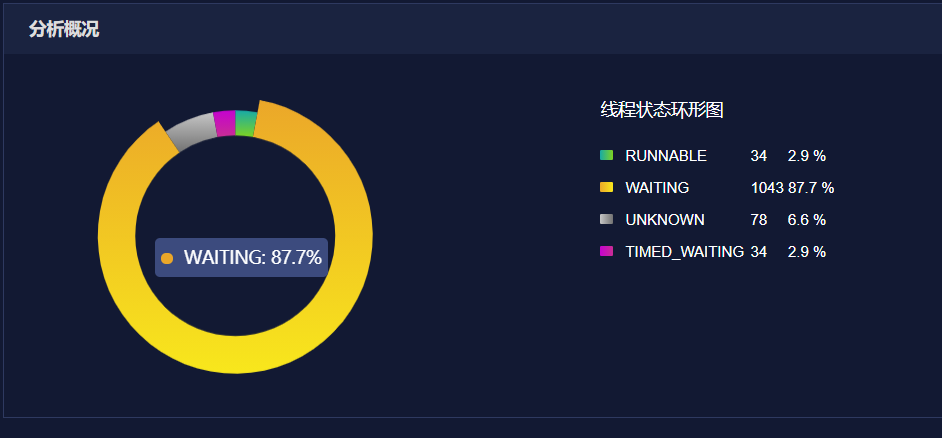
经过分析发现有1043个线程处于WAITING状态,这种现象是很反常的,按照经验,这种现象说明VM内部可能存在死锁或者存在存在竞争激烈且持锁时间比较长的线程,通过进一步分析发现,http-nio-1601-exec-*线程池中包含1000个线程,且有999个都处于WAITING状态。
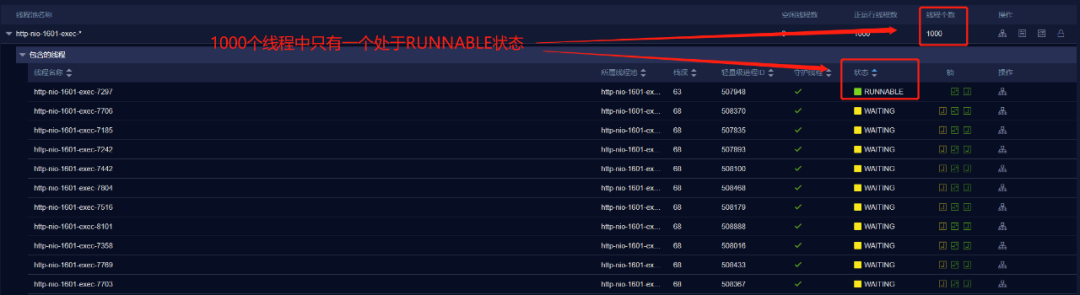
http-nio-1601-exec-xxx 线程是Tomcat在1601端口的的工作线程。我们知道,Tomcat的工作线程数量可以通过max-threads配置项配置,这里我们配置了max-threads为1000,所以Tomcat的工作线程最大也只能有1000个,但是对于正常负载的服务器来说,线程池中的线程数会低于最大值的一半,也就是说会在500个以内,且处于WAITING状态的工作线程,一般都会处于等待数据库IO、RPC方法调用的状态,而对于较低负载的服务器来说,线程数甚至只有min-SpareThreads配置的最小值,而且大部分线程会处于等待线程池中任务队列的状态。
继续追查WAITING状态的线程,发现999个线程全部阻塞在org.springframework.util.MimeTypeUtils$ConcurrentLruCache.get 方法内部的读写锁上。
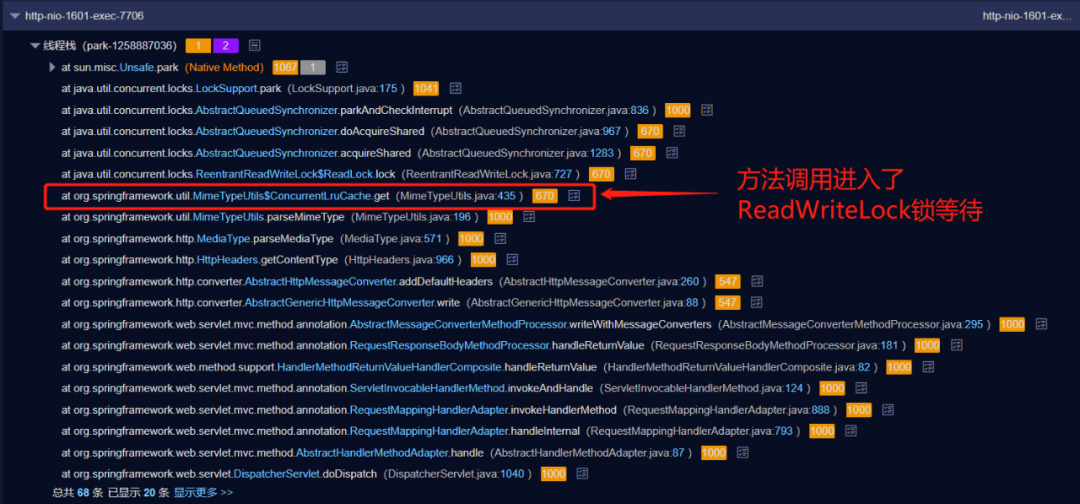
而唯一运行中的线程,也在执行org.springframework.util.MimeTypeUtils$ConcurrentLruCache.get方法,且堆栈在ConcurrentLinkedQueue的remove方法。
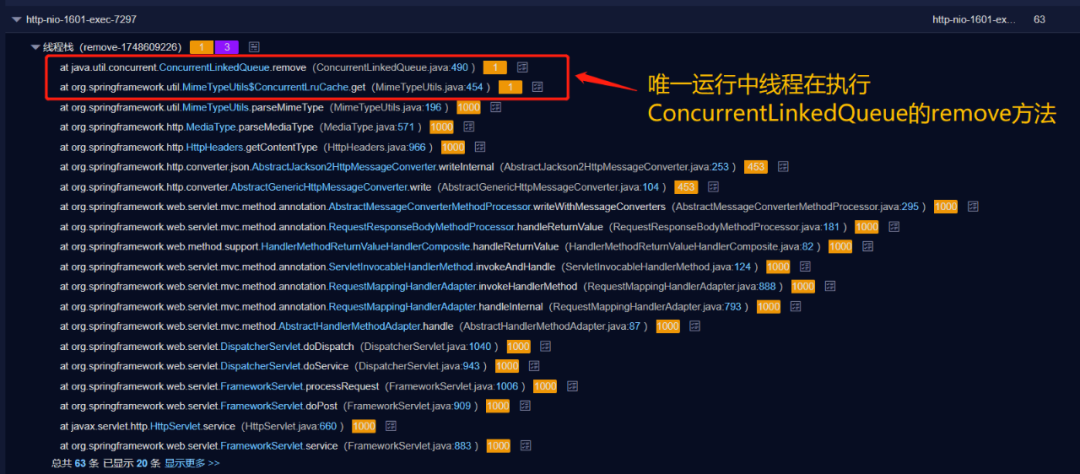
排查到这里,我们开始怀疑是org.springframework.util.MimeTypeUtils类中ConcurrentLruCache内部类的get方法存在问题。
查看Spring框架源码,发现这块逻辑就是实现了一个LRU缓存,通过ConcurrentLinkedQueue保证线程安全的同时,实现了淘汰最近最久未使用的缓存key(这里缓存value其实就是HTTP MIME类型),因此在搜索引擎上进行搜索,发现 spring-framework 工程Github上有多个Issues,反馈MimeTypeUtils类出现性能衰减问题,导致CPU占用率飙升问题。最终Spring开发者认定了这些问题源自同一个Bug。
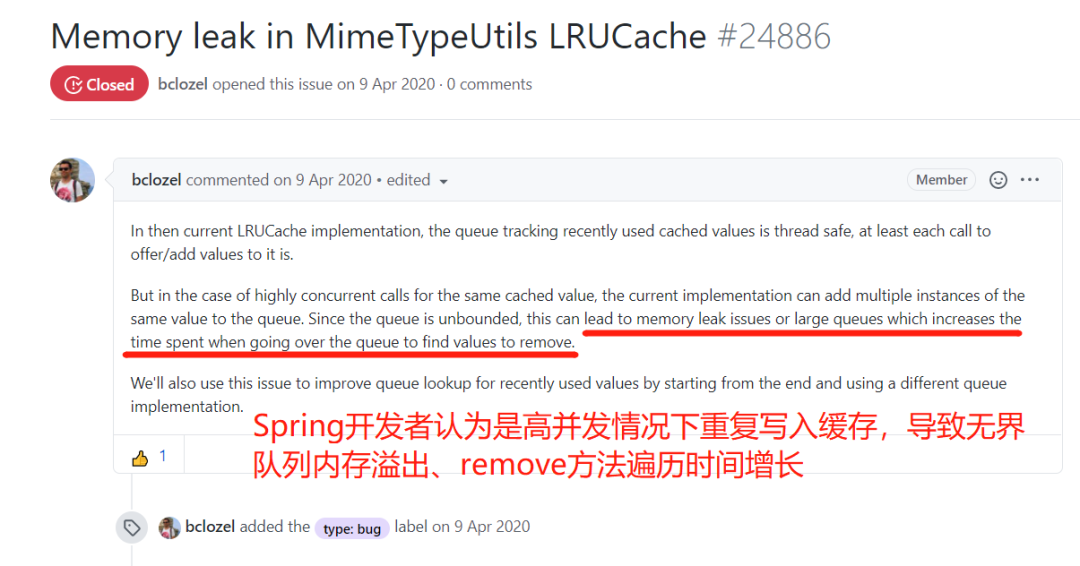
后续Spring开发者修复了这个问题,修复方式是将ConcurrentLinkedQueue换为了ConcurrentLinkedDeque。
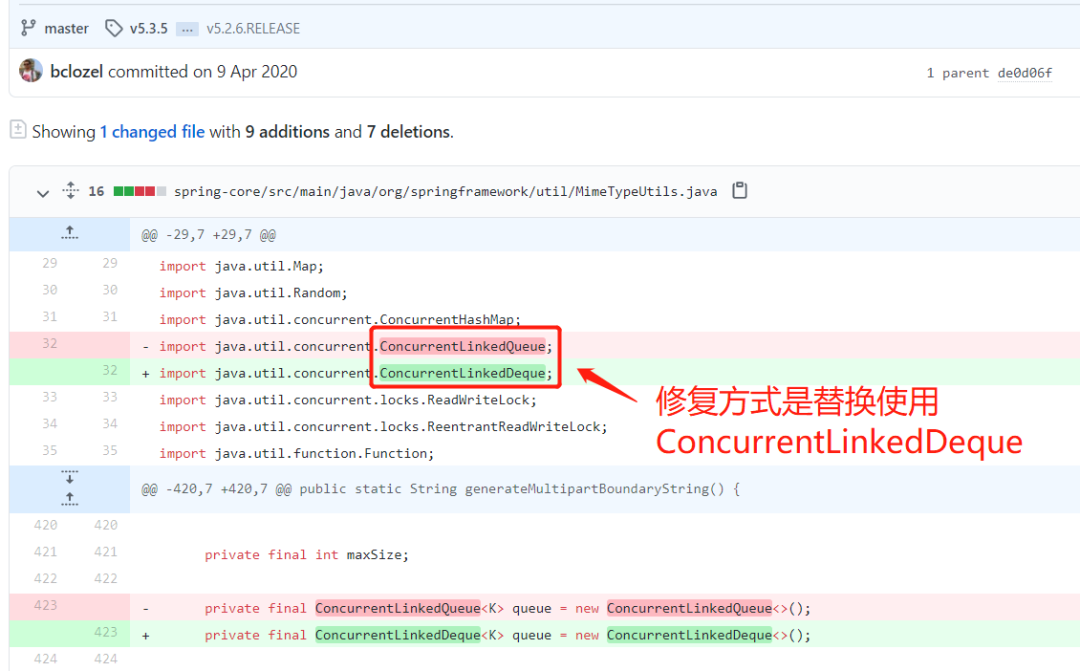
到这里我们已经可以解决这个问题,只需要升级Spring框架版本号就可以避开这个Bug,但是有个问题始终萦绕在我心中,因为查看源码,作者对于这个LRU缓存做了一个最大长度的限制,超过这个maxSize就会淘汰缓存remove元素,为什么会出现Spring开发者说的内存泄漏和队列无限增长的问题呢?
带着好奇心继续查找相关资料,发现JDK-8137184汇报了一个ConcurrentLinkedQueue#remove(Object)导致内存溢出的Bug,但是这个Bug在2015年9月已经被解决了,难道说和这个Bug没有关系?
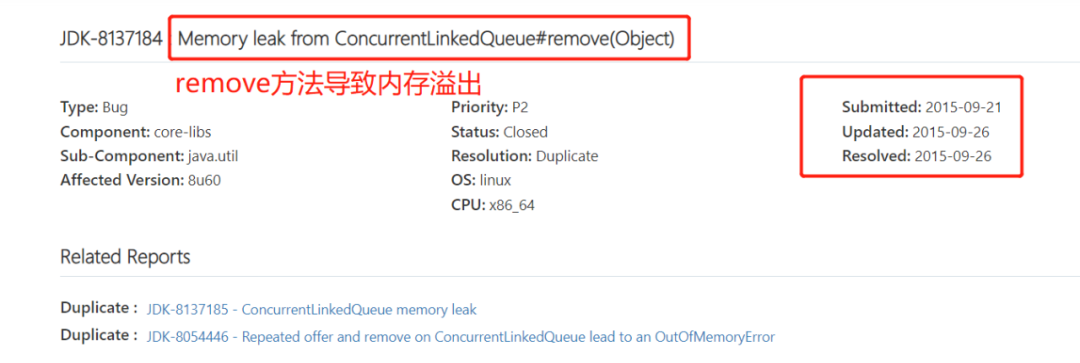
因此我去下载了我们使用的JDK源码压缩包,找到ConcurrentLinkedQueue类的源码后,发现其其中remove方法的Bug依旧是存在的。
为什么会这样呢?原来服务器上使用的是开源的Open JDK,Open JDK修复这个Bug时间较晚,在8u102版本才合并修复,这样就能解释我们所使用的Open JDK版本为什么依然存在这个Bug了。

这个Bug具体会造成什么现象呢?这里我找到了JDK的Bug报告:

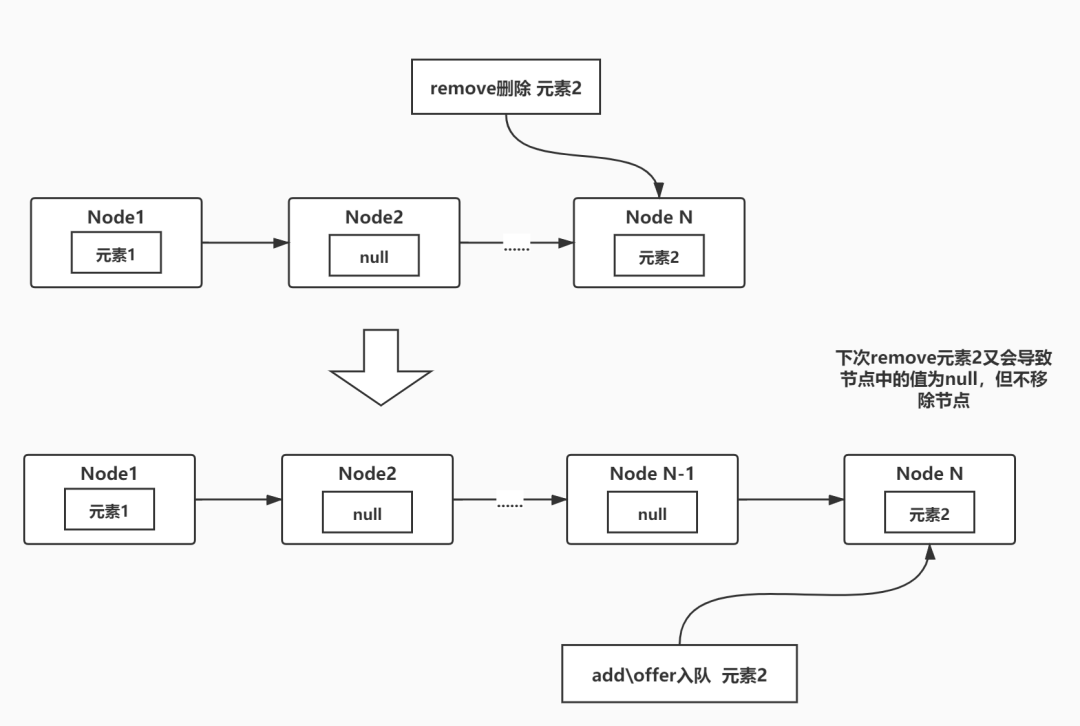
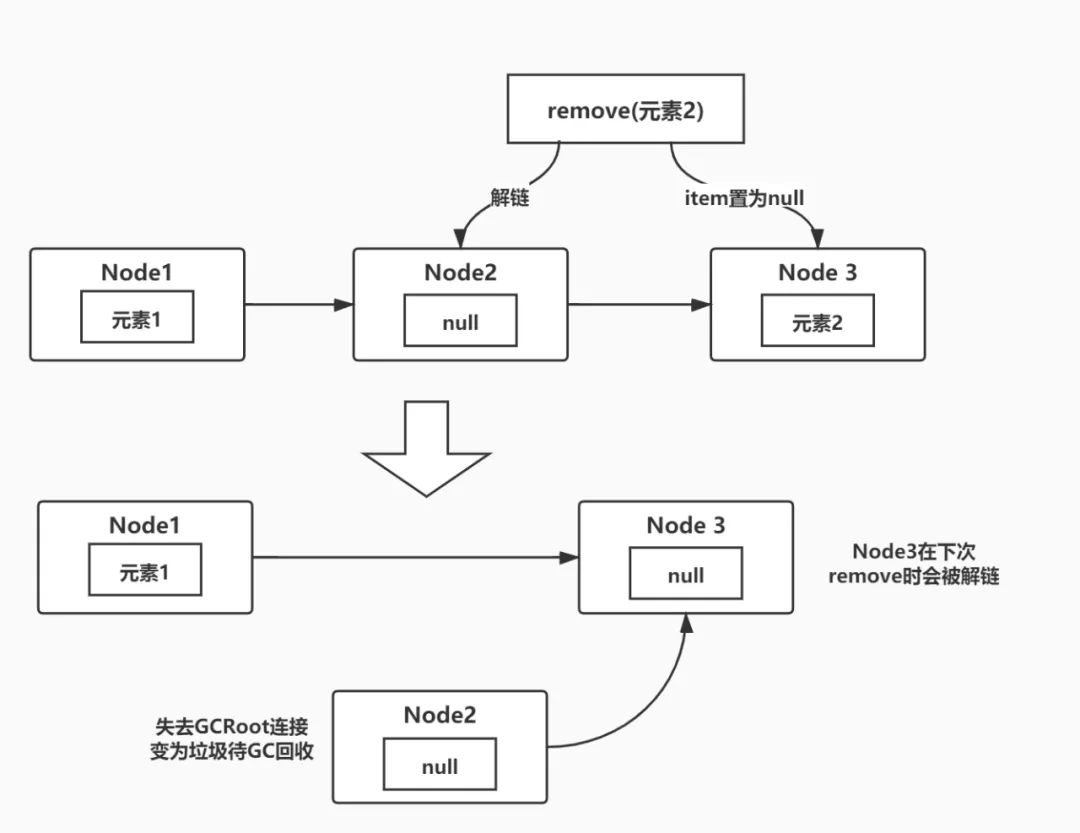
根据Bug报告,remove方法应该把队列中需要删除的元素所在的节点值置为null,同时将节点从队列中delink(解链),这个很好理解,我们都知道链表在删除元素时需要解链(参考最简单的LinkedList),但是当这里的remove方法需要移除的元素位于链表中最后一个节点时,并不会移除最后一个节点,从而导致了链表的无限增长。
这里我们拿从服务器上下载的JDK源码,找到存在Bug的ConcurrentLinkedQueue类的源码来看下:
// ConcurrentLinkedQueue类有Bug的remove方法public boolean remove(Object o) {if (o == null) return false;Node<E> pred = null;for (Node<E> p = first(); p != null; p = succ(p)) { // 遍历链表E item = p.item;if (item != null &&o.equals(item) &&p.casItem(item, null)) {Node<E> next = succ(p);// 这里出现了问题,p为最后一个元素时,succ(p)返回null// next=null,就导致下面这一行if判断永远为false// 也就是说永远都不会移除这个节点if (pred != null && next != null)pred.casNext(p, next); // 删除节点return true;}pred = p;}return false;}
根据源码,可以很清晰的看明白这个Bug的成因,当需要remove的元素在链表的最后时,确实不会移除这个节点。
举个例子来说,如果先add或者offer元素2到链表中,下一步又直接remove这个元素2,重复这个过程,就会导致这个链表无限增长,又因为remove会遍历列表,这就可能导致remove遍历的时间越来越长,从而产生了之前我们服务器上999个线程都在等待1个线程remove方法执行。
理论上来说,这个Bug一定会导致JVM堆内存泄漏,使用jmap工具Dump线上机器堆内存以后,导入MAT分析后,发现确实存在内存泄漏的问题,线上机器并没有出现这个问题可能是因为这个列表还不够大,remove遍历时间还不至于导致服务不可用。
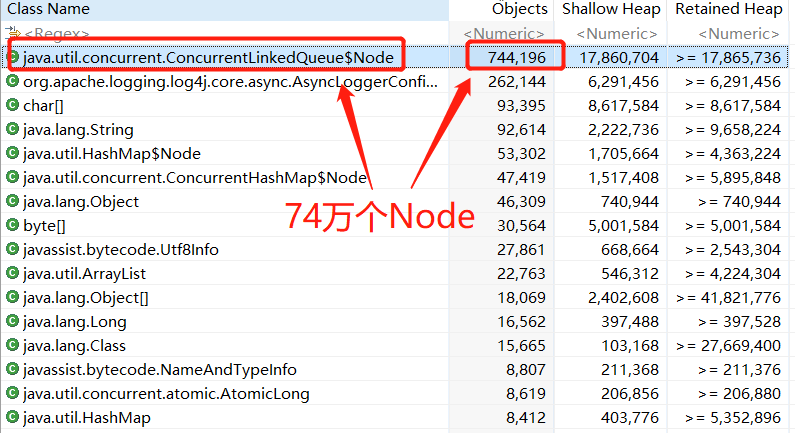
分析Dump文件以后,发现ConcurrentLinkedQueue的Node节点对象有74万个,而Spring框架MimeTypeUtils内的LRU缓存列表queue变量RetainedHeap大小几乎等于全部74万个Node对象的大小,也就是说明确实是MimeTypeUtils类内LRU缓存列表发生了内存泄漏。

JDK修复这个Bug的方式也比较简单,之前Bug产生的原因是因为remove方法删除最后一个元素时只把item值置为null,但是却并不能解链,导致在不断地add\remove中这个链表越来越长,既然这样,就在下次remove时把之前item为null的节点解链,JDK开发者就是这样修复了这个Bug。
// 修复Bug后的remove方法public boolean remove(Object o) {if (o != null) {Node<E> next, pred = null;for (Node<E> p = first(); p != null; pred = p, p = next) {boolean removed = false;E item = p.item;// 这里if判断item是否为null// item为null说明是上次删除遗留的空节点,进入后续解链逻辑// item不为null则进入判断是否需要删除逻辑if (item != null) {if (!o.equals(item)) {// 不是要删除元素,则继续向后遍历next = succ(p);continue;}// 要删除元素item值置为nullremoved = p.casItem(item, null);}next = succ(p);// 这里判断逻辑和之前一样,本次remove最后一个元素,依旧不会解链// 但是上次remove最后一个元素后遗留的null节点,会在本次被解链if (pred != null && next != null) // unlinkpred.casNext(p, next);if (removed)return true;}}return false;}
举个简单例子来说,如果我们依旧一直add\remove 元素2,那么就会出现下图这个情况,本次remove只把队尾的元素2所在的节点item置为null,而下次remove时就会把这个item=null的节点从链表中真正的移除,被移除的节点会失去和GCRoot连接,最终在下次GC中被回收,从而保证不会出现内存泄漏的问题。
本次问题排查过程中,遇到了一些超出平常接触到的问题,也出现了想重启服务器尝试“解决”问题的错误思路,同时也因为这些障碍,我萌发了更多思路、借助了更多的新工具,比如说UMP平台新提供的链路追踪功能,就是我破局的一个重要倚赖。
出现了匪夷所思的问题,首先要保留好问题现场,比如说将VM堆和线程堆栈Dump保存,保存线上日志和GC信息等,特别是一些不能必现的问题,更需要问题现场才能进行排查,盲目的尝试重启解决问题,反而会掩盖存在的问题。
* spring-framework Issues#24886:https://github.com/spring-projects/spring-framework/issues/24886
* JDK-8137184:https://bugs.java.com/bugdatabase/view_bug.do?bug_id=8137184
* JDK-8150780:https://bugs.openjdk.java.net/browse/JDK-8150780
* PerfMa线程Dump分析工具:https://thread.console.perfma.com
* 堆内存分析工具 Memory Analyzer (MAT):https://www.eclipse.org/mat/
— 本文结束 —

关注我,回复 「加群」 加入各种主题讨论群。
对「服务端思维」有期待,请在文末点个在看
喜欢这篇文章,欢迎转发、分享朋友圈