
一次实战压测流程及问题梳理!

1、背景及目的
在动手之前,先要想清楚我们期望从压测中获取的价值是什么。
这次压测的背景,主要是为了应对旺季到来,避免旺季的大量流量和高并发造成服务不可用,提升稳定性。而在稳定性建设中,也会从事前、事中及事后来看,包含的维度包含风险识别、监控告警、应急流程及故障复盘等不同的维度。
而其中,我们关注的主要包含三个维度,风险识别、监控告警、熔断降级和容量规划。

2、压测流程
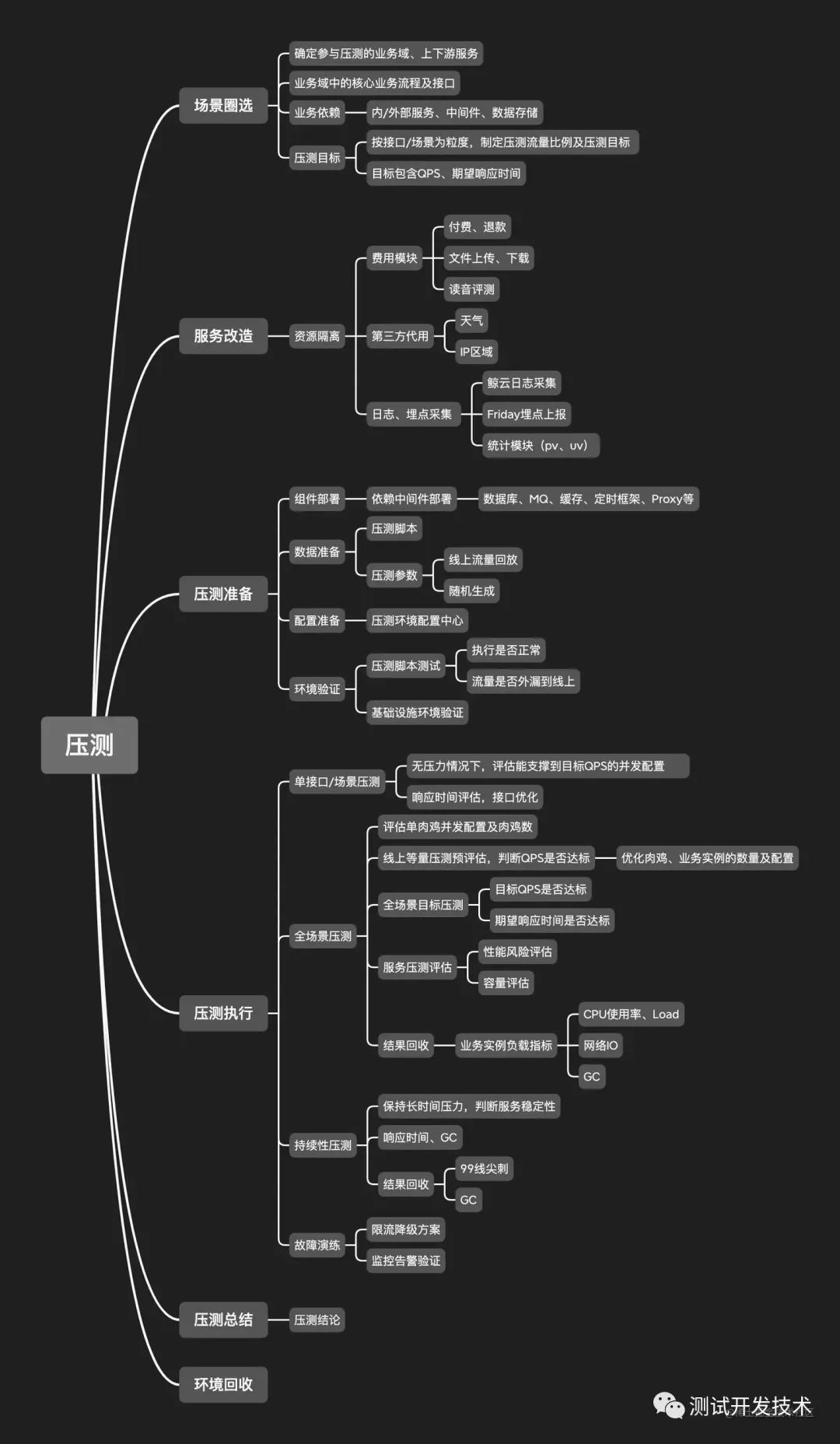
1 - 场景圈选
圈选参与压测的业务域、依赖服务及中间件、存储等,确定压测范围及边界,基于过往线上流量输出压测流量比例及目标。

在确定压测范围的同时,需要确定业务模块中场景/接口的压测目标,包括目标QPS及响应时间。
目标QPS,我们是按照往年的流量或活跃用户变化推算总目标QPS的,然后按照相同的增长率计算单个场景/接口的目标QPS值。其中,拆分出各个场景/接口的QPS值是很重要的,这样才能按线上接口的流量比例进行发压。
预期响应时间,以业务高峰时期正常的99线及平均响应时间作为目标值,这里不仅可以判断服务性能是否有比较大的影响,同时也能辅助做容量规划。
为什么和容量规划有关系?
根据排队论的思想,实际响应时间=队列等待时间+服务处理时间,队列等待时间则和服务器资源有关,资源少时就会处于队列等待(CPU资源等待、池等待),耗时就会上升。同时,在一些需要控制成本且对延时不那么敏感的场景下,就可以在保证服务正常且满足预期响应时间的情况下,减少服务实例。
2 - 服务改造
在压测前,需要判断圈选的压测场景中是否包含无法支持或需要单独适配、资源隔离等的场景,并提前做好改造。举个栗子,如果场景中涉及到第三方资源调用(语音识别、天气获取等)时,需要提前做好改造,否则压测过程中大量消耗购买的服务资源次数,就会导致费用突增。

改造的方式也有很多,可以mock数据、做挡板、动态配置开关、固定时延返回等等。
目前做的比较好的厂,可以通过流量打标识别压测流量,字节码注入改写做到无侵入的挡板,数据也可以该写入影子表中,实现线上环境的低成本压测。
3 - 压测准备
对压测过程需要的所有组件、数据、配置及环境进行准备,保证压测环境本身正确无影响,可以顺利执行压测任务。

其中,
组件部署,需要提前收集线上组件的配置,按相同配置或等比缩容的形式提前做好部署,准备好域名、账号等内容;
脚本及数据,我们使用的是基于JMeter自建的压测平台,会提前按全选场景准备好压测脚本,而压测数据则根据线上高峰时段的请求数据为基础进行生成,进行流量回放;
配置准备,服务使用了配置中心,需要新建一套与线上隔离的配置,避免压测过程中的参数调优影响到线上;
环境验证,验证压测脚本及数据,并对基础设施环境进行测试,包含检查流量外漏、基础设施状态等。
在环境验证上,我们也压测验证了基础环境的状态,在网关(APISIX)返回503时的链路情况。在压力较大的情况下3~3.5ms返回,压力小的时候1ms内就返回。
4 - 压测执行
接下来就是压测执行阶段了,我们除了对圈选的业务模块进行压测外,也对熔断、降级方案进行了验证。

压测过程中,除了服务本身的问题外(【记一次业务压测过程中发现的问题】),我们在压力评估及肉鸡配置上踩了不少坑。
压力评估
过往我们仅仅是通过CPU及内存使用率来判断容器压力,但是这是非常不准确的,一定要结合Load Average来看。
Load Average,描述系统处于RUNNABLE或UNINTERRUPTIBLE状态的进程,包含正在执行、等待执行以及不可中断状态的进程,当其大于CPU核数数,此时的CPU负载很可能就是有压力的。
关于
UNINTERRUPTIBLE状态的进程?表名进程阻塞在磁盘IO或一些锁上,因此Load Average也能侧面反应出磁盘IO负载,这种情况可以通过off-cpu火焰图进行分析。
一般我们通过top可以看到最近1分钟、5分钟及15分钟的负载,但是实际上这三个值并不是准确的Load Average,它计算是基于指数衰减的移动加权累加得到的,变化的速度会慢于真实的负载。

图中为跑1个Thread时的负载,可以看到要到5分钟后Load Average才跑到接近1左右。因此,想要观察真正的负载需要保持一段时间的压力,我们压测时是按保持5分钟压力后的结果来定的。
容器内的Load Average
top命令中的Load Average是读取/proc/loadavg中的值,而在容器中,该目录是挂载宿主机的/proc,因此top看到的是宿主机的负载,无法真正区分容器中的值。
这里推荐大佬张师傅基于topic修改的ctop来进行观察。
( github.com/arthur-zhan… )
肉鸡配置及数量的评估
在压测的发起端,底层是通过JMeter实现的,为了能够保持一段时间的服务压力,我们是通过控制并发数而非请求总数来进行肉鸡配置的,可以简单的理解为1并发数就是一个线程持续的发起请求。
那么,如何将压测目标QPS转化为并发数配置呢?一个线程持续的发起请求,那么QPS是未知的,要怎么找到最合适的并发数配置呢?
这里可以拆解两步来分析:
单场景/接口压测,找到单场景目标QPS达成所需要的并发数。

这里有一个容易踩的坑,并发数的配置一定要在肉鸡、服务实例均无压力的情况下进行评估,评估方法可以结合前面提到的Load Average及99线。如果肉鸡压力大,CPU资源紧张,线程等不到CPU资源分片,导致QPS上不去,99线也会高出很多。
全场景压测,评估单台肉鸡的并发数配置及肉鸡数。
由于单台肉鸡的配置有限,所能支撑的并发数也会太高,所以我们需要估算出单台肉鸡的并发数配置。
这里可能有一个误区,并发数并不是要小于等于CPU核数。实际能支撑的并发数和接口的响应时间有关系,请求发出并等待返回的这段时间内,线程阻塞等待结果,此时是不占用CPU的。占用CPU的只有组装和发送请求、解析和判断返回的阶段,中间的等待阶段可以调度处理不同线程的任务。
这里的肉鸡并发数配置也有两种方式:
(1)按照单个场景/接口,单独下发脚本和并发数。这样做意味着不同的肉鸡在执行不同的压测脚本,能更好的控制并发数和目标QPS,但是需要能比较好的单独控制脚本下发和并发数配置;
举个栗子,
肉鸡A,4C8GB,下发场景1和场景3脚本,按并发数9、14进行多线程执行;肉鸡B,8C16GB,下发场景2脚本,按并发数112进行多线程执行。

这样不同的肉鸡配置各不相同,各自执行特定的场景脚本,优点是压测中各场景的目标QPS比较准确,符合预期,但是无论是自动化或手动配置都比较繁琐,无法快速批量扩大压测规模。
(2)按各场景不同的的并发数比例,计算单肉鸡的并发配置,再按目标并发数计算肉鸡数量,批量下发脚本及并发数配置。
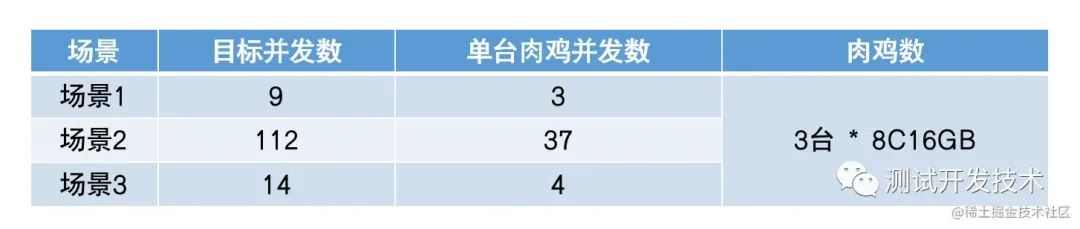
该方式下,每台肉鸡都会收到全部场景的脚本和并发数配置,只需批量下发即可,最终通过控制肉鸡数量来达到全场景目标QPS值,优点是可以快速扩大压测规模,缺点是最终各场景的QPS比例可能偏差较大。
比如图中的场景3,4并发*3肉鸡=12并发,小于目标并发数,此时无论增加单肉鸡并发数还是肉鸡数量,也都会导致实际并发数与目标不一致。
其他
持续性压测更多观关注GC、有效吞吐占比及99线尖刺。
故障演练核心验证熔断是否能按预期生效,限流降级方案演练及有效性验证,如果有应急处理流程的话也可以进行全流程的演练。
5 - 压测总结及资源回收
这个阶段没什么好说的,总结过程、描述问题及解决方案、后续的优化策略以及压测流程、平台的后续建设方向等都可以一起讨论总结、沉淀为团队知识。
最后,最最重要的,不要忘了回收压测资源,因为很贵。
3、总结
本文更多是对压测流程上的一些经验总结,帮助找到合适的流程及方法来进行压测,后续也能基于流程不断迭代更新。从过程上看,我们在压测流程以及基础设施的建设上还比较原始,依赖人工调整、评估,也能对未来的压测平台建设提供方向。
链接:https://juejin.cn/post/7141588790249783303
来源:稀土掘金