
Apache Iceberg小文件处理和读数流程分析


第一部分:Spark读取Iceberg流程分析
这个部分我们分析常规数据读取流程,不涉及到数据更新,删除等场景下的读取。
数据读取大概可以分为两个步骤
通过 Iceberg 的元数据 snapshot, manifest file 等解析出包含数据文件信息的 DataFile 对象 读取数据文件内容,把每行数据封装成 Spark 的 InternalRow 返回给引擎层
Spark 引擎层和 Iceberg 对接
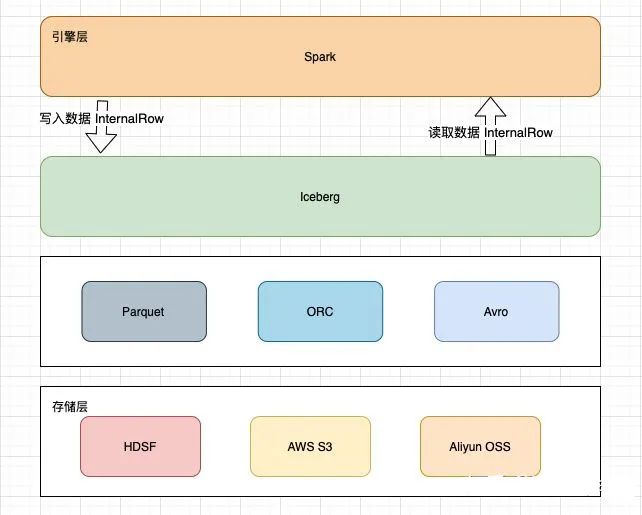
根据 Spark 规范,如果要让 Spark 读取数据,需要实现以下几个接口。
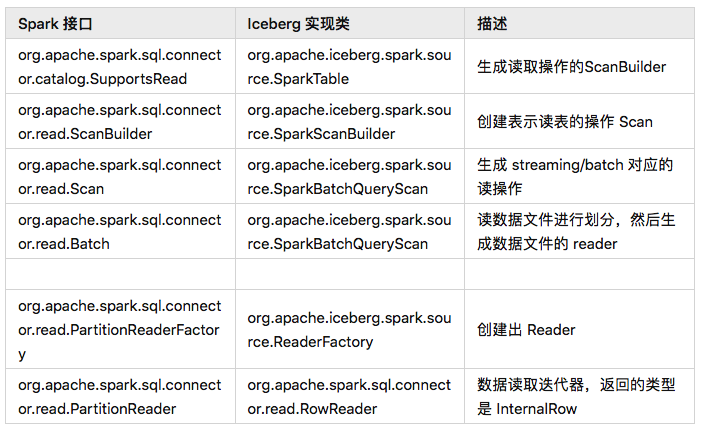
Spark 在读取数据之前,需要为每个 Executor 分配数据文件,然后通过 Reader 读取数据文件。这两个接口都是在 org.apache.spark.sql.connector.read.Batch 实现的,创建 Batch 的步骤如下
Iceberg 的 SparkTable 实现了 SupportsRead的newScanBuilder方法,创建出SparkScanBuilderSparkScanBuilder会创建出SparkBatchQueryScanSparkBatchQueryScan 的 toBatch 方法创建出表示 批操作 的Batch 对象 通过 SparkBatchQueryScan的 planInputPartitions 获取要读取的数据分片通过 SparkBatchQueryScan, 生成 Reader 读取数据
重点看一下 Batch 接口的定义
//org.apache.spark.sql.connector.read.Batch;
public interface Batch {
//表示一个输入分片
InputPartition[] planInputPartitions();
//为每个输入的文件创建 Reader
PartitionReaderFactory createReaderFactory();
}
生成数据分片
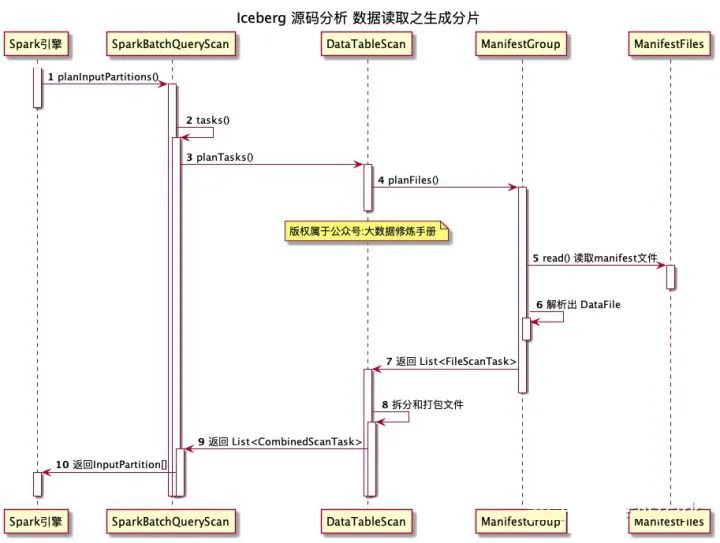
先通过流程图,看一下涉及到的类
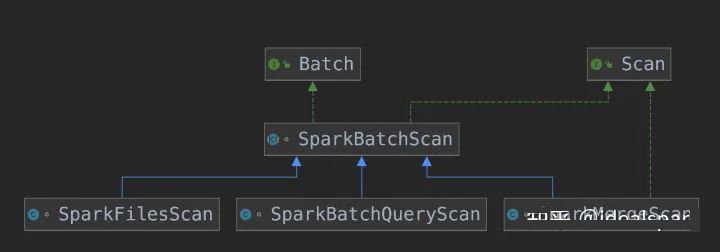
Iceberg 中的 SparkBatchQueryScan 同时实现了 Spark Scan 和 Batch 接口
首先 Spark 引擎会调用 SparkBatchQueryScan 的 planInputPartitions 方法, 获取输入分片。
SparkBatchQueryScan 表示普通的查询,SparkMergeScan 用在需要数据合并的场景下。
planInputPartitions方法先调用的 tasks() 方法获取到 CombinedScanTask,然后再封装成 ReadTask 返回给引擎。
ReadTask 实现了 InputPartition接口,但 InputPartition 接口没有定义有用的方法,具体封装什么数据由 ReadTask 决定。
ReadTask 实际上封装的是 每个数据文件的 元信息,最终作为 Spark Reader 的输入。
// org.apache.iceberg.spark.source.SparkBatchScan
@Override
public InputPartition[] planInputPartitions() {
//生成 CombinedScanTask
List<CombinedScanTask> scanTasks = tasks(); //task 由子类来实现
InputPartition[] readTasks = new InputPartition[scanTasks.size()];
//将 CombinedScanTask 封装成 ReadTask
Tasks.range(readTasks.length)
.stopOnFailure()
.executeWith(localityPreferred ? ThreadPools.getWorkerPool() : null)
.run(index -> readTasks[index] = new ReadTask(
scanTasks.get(index), tableBroadcast, expectedSchemaString,
caseSensitive, localityPreferred));
return readTasks;
}
在进行数据文件分片之前,已经由表名通过 Catalog 加载了表的 metadata.json 文件,生成BaseTable。
通过 BaseTable 创建出 TableScan,对应的实现类是 DataTableScan, 同时指定了一些过滤条件,snapshot 的时间范围等,通过 TableScan 的子类来查找数据文件。
protected List<CombinedScanTask> tasks() {
TableScan scan = table() // table() 返回的是BaseTable,参考元数据博客
.newScan()
.caseSensitive(caseSensitive())
.project(expectedSchema());
//如果单个文件大小超过 SPLIT_SIZE,默认128M,并且支持切分,会对文件进行切分
if (splitSize != null) {
scan = scan.option(TableProperties.SPLIT_SIZE, splitSize.toString());
}
//如果文件比较小,比如只有1KB, 会将多个文件打包成一个输入分片,如果文件大小小于 SPLIT_OPEN_FILE_COST 默认4M,会按照 SPLIT_OPEN_FILE_COST 来计算
if (splitOpenFileCost != null) {
scan = scan.option(TableProperties.SPLIT_OPEN_FILE_COST, splitOpenFileCost.toString());
}
//如果查询有where 过滤条件,会进行下推,进行文件级别的裁剪
for (Expression filter : filterExpressions()) {
scan = scan.filter(filter);
}
CloseableIterable<CombinedScanTask> tasksIterable = scan.planTasks());
return Lists.newArrayList(tasksIterable)
}
TableScan的继承结构如下,通过继承关系,也可以发现 Iceberg 是支持增量读取的

DataTableScan 通过以下流程来生成输入分片
由 planFiles() 获取所有需要读取的数据文件, 实际是委托给了 ManifestGroup 来操作 对大文件进行拆分,如果单个文件大小超过 SPLIT_SIZE,默认128M,并且文件格式支持切分,会对文件进行切分 将小文件打包在一起,如果文件比较小,比如只有1KB, 会将多个文件打包成一个输入分片,如果文件大小小于 SPLIT_OPEN_FILE_COST, 默认4M,会按照 SPLIT_OPEN_FILE_COST 来计算
//org.apache.iceberg.BaseTableScan
public CloseableIterable<CombinedScanTask> planTasks() {
//获取到所有数据文件
CloseableIterable<FileScanTask> fileScanTasks = planFiles();
//对大文件进行拆分
CloseableIterable<FileScanTask> splitFiles = TableScanUtil.splitFiles(fileScanTasks, splitSize);
//把多个小文件合并成在一个 CombinedScanTask 中
return TableScanUtil.planTasks(splitFiles, splitSize, lookback, openFileCost);
}
public CloseableIterable<FileScanTask> planFiles() {
//先确定好要读取的 snapshot
Snapshot snapshot = snapshot();
return planFiles(ops, snapshot,
context.rowFilter(), context.ignoreResiduals(), context.caseSensitive(), context.returnColumnStats());
}
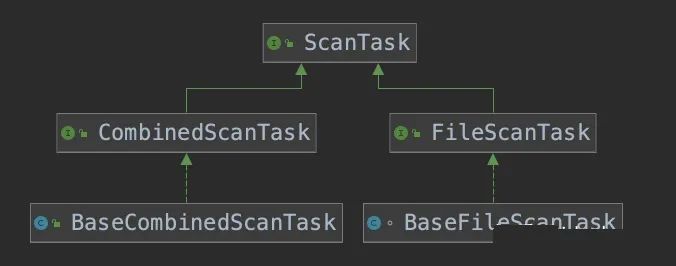
FileScanTask 的继承关系如下,
FileScanTask 表示一个输入文件或者一个文件的一部分,在这里实现类是 BaseFileScanTask
CombinedScanTask 表示多个 FileScanTask 组合在一起,实现类是 BaseCombinedScanTask
由于定位文件需要 Manifest 等信息,先通过 snapshot.dataManifests() 读取当前 snapshot 的 manifestlist 文件,
解析出表示 ManifestFile 的对象 。
再构造出一个 ManifestGroup ,让 ManifestGroup 根据 manifest file 来获取输入的文件
//org.apache.iceberg.ManifestGroup
@Override
public CloseableIterable<FileScanTask> planFiles(TableOperations ops, Snapshot snapshot,
Expression rowFilter, boolean ignoreResiduals,
boolean caseSensitive, boolean colStats) {
//此时会通过 snapshot.dataManifests() 读取当前 snapshot 的 manifestlist 文件,解析出表示 ManifestFile 的对象
ManifestGroup manifestGroup = new ManifestGroup(ops.io(), snapshot.dataManifests(), snapshot.deleteManifests())
.caseSensitive(caseSensitive)
.select(colStats ? SCAN_WITH_STATS_COLUMNS : SCAN_COLUMNS)
.filterData(rowFilter)
.specsById(ops.current().specsById())
.ignoreDeleted();
if (ignoreResiduals) {
manifestGroup = manifestGroup.ignoreResiduals();
}
return manifestGroup.planFiles();
}
由于不考虑删除等场景,所以获取 文件信息 的流程比较简单
通过 ManifestFile 对象 去读取所有的 ManifestFile 文件 通过 ManifestFile 解析出 DataFile 对象 如果有谓词下推,会对 DataFile 做过滤,进行文件级别裁剪 将符合条件的 DataFile 封装到 BaseFileScanTask 中
public CloseableIterable<FileScanTask> planFiles() {
//将返回的 DataFile 对象, 封装成 BaseFileScanTask
Iterable<CloseableIterable<FileScanTask>> tasks = entries((manifest, entries) -> {
return CloseableIterable.transform(entries, e -> new BaseFileScanTask(
e.file().copy(), deleteFiles.forEntry(e), schemaString, specString, residuals));
return CloseableIterable.concat(tasks);
}
private <T> Iterable<CloseableIterable<T>> entries(
BiFunction<ManifestFile, CloseableIterable<ManifestEntry<DataFile>>, CloseableIterable<T>> entryFn) {
//先通过表达是过滤 ManifestFile 文件
Iterable<ManifestFile> matchingManifests =
Iterables.filter(dataManifests, manifest -> evalCache.get(manifest.partitionSpecId()).eval(manifest));
return Iterables.transform(
matchingManifests,
manifest -> {
//读取 ManifestFile
ManifestReader<DataFile> reader = ManifestFiles.read(manifest, io, specsById)
.filterRows(dataFilter)
.filterPartitions(partitionFilter)
.caseSensitive(caseSensitive)
.select(columns);
//解析出 DataFile 对象
CloseableIterable<ManifestEntry<DataFile>> entries = reader.entries();
//对 DataFile 做裁剪
if (evaluator != null) {
entries = CloseableIterable.filter(entries,
entry -> evaluator.eval((GenericDataFile) entry.file()));
}
return entryFn.apply(manifest, entries);
});
}
通过一系列操作,我们获取到了包含数据文件信息的 DataFile 对象,将其封装在 CombinedScanTask 进行返回
数据读取
在获取到要读取的数据文件信息后,Spark 会为每个任务分配数据分片,由 Executor 进行读取。
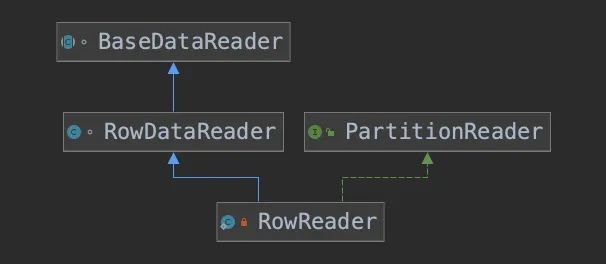
先看一下 Spark 定义的接口 org.apache.spark.sql.connector.read.PartitionReader ,很符合火山模型的定义,但 Spark 现在也支持向量化读取。
RowDataReader 实现了PartitionReader 接口 ,看一下 RowDataReader 继承关系。
整个数据读取的核心逻辑 就是读取 Parquet 中的数据。
//org.apache.spark.sql.connector.read.PartitionReader
public interface PartitionReader<T> extends Closeable {
/**
* Proceed to next record, returns false if there is no more records.
*/
boolean next() throws IOException;
/**
* Return the current record. This method should
return same value until `next` is called.
*/
T get();
}
通过 ReaderFactory 创建出 PartitionReader,比较简单,需要注意一下 RowReader 的输入是 ReadTask,可以把ReadTask 理解成 Iceberg DataFile 对象的封装
static class ReaderFactory implements PartitionReaderFactory {
@Override
public PartitionReader<InternalRow> createReader(InputPartition partition) {
if (partition instanceof ReadTask) {
return new RowReader((ReadTask) partition);
}
}
@Override //可以看到 Spark 也是支持向量化读取的
public PartitionReader<ColumnarBatch> createColumnarReader(InputPartition partition) {
if (partition instanceof ReadTask) {
return new BatchReader((ReadTask) partition, batchSize);
}
}
}
BaseDataReader 实现了PartitionReader 的 next 接口,之前讲过 CombinedScanTask 里面包含了多个文件,next 把具体的读操作再委托读每个文件
// 代码有简化
abstract class BaseDataReader<T> implements Closeable {
private T current = null;
private final Map<String, InputFile> inputFiles;
private CloseableIterator<T> currentIterator;
//代码有简化,去掉了加密逻辑,用输入分片的所有文件,生成一个 location 和 InputFile, FileIO 表示存储
BaseDataReader(CombinedScanTask task, FileIO io, EncryptionManager encryptionManager) {
this.tasks = task.files().iterator();
this.inputFiles files = Maps.newHashMapWithExpectedSize(task.files().size());
task.files().forEach(file -> files.putIfAbsent(file.location(), io.newInputFile(file.location())));
this.currentIterator = CloseableIterator.empty();
}
//next 委托给每个文件对应的 Iterator
public boolean next() throws IOException {
while (true) {
if (currentIterator.hasNext()) {
this.current = currentIterator.next();
return true;
} else if (tasks.hasNext()) {
this.currentIterator.close();
this.currentTask = tasks.next();
this.currentIterator = open(currentTask); // 读文件
} else {
this.currentIterator.close();
return false;
}
}
}
public T get() {
return current;
}
}
RowDataReader 会根据文件格式,使用对应的 Format Reader , 通过 newParquetIterable() 方法,这里返回的是 ParquetFileReade。
实际读取操作由Parquet 库提供的 org.apache.parquet.hadoop.ParquetFileReader 实现
//org.apache.iceberg.spark.source.RowDataReader
protected CloseableIterable<InternalRow> open(FileScanTask task, Schema readSchema,Map idToConstant) {
CloseableIterable<InternalRow> iter;
InputFile location = getInputFile(task);
switch (task.file().format()) {
case PARQUET:
iter = newParquetIterable(location, task, readSchema, idToConstant);
break;
}
}
return iter;
}
private CloseableIterable<InternalRow> newParquetIterable(
InputFile location,
FileScanTask task,
Schema readSchema,
Map<Integer, ?> idToConstant) {
Parquet.ReadBuilder builder = Parquet.read(location)
.reuseContainers()
.split(task.start(), task.length())
.project(readSchema)
.createReaderFunc(fileSchema -> SparkParquetReaders.buildReader(readSchema, fileSchema, idToConstant))
.filter(task.residual())
.caseSensitive(caseSensitive);
return builder.build(); //实际读取操作由Parquet 库提供的 ParquetFileReader 实现
}
至此 数据读取的逻辑就分析完毕,核心就是去读文件,把每行数据封装成 Spark 的 InternalRow,返回给 Spark 引擎。
第二部分:Iceberg 解决小文件问题概览
如下是我们使用 Spark 写两次数据到 Iceberg 表的数据目录布局:
/data/hive/warehouse/default.db/iteblog
├── data
│ └── ts_year=2020
│ ├── id_bucket=0
│ │ ├── 00000-0-19603f5a-d38a-4106-aeb9-47285d15a6bd-00001.parquet
│ │ ├── 00000-0-491c447b-e05f-40ac-8c32-44d5ef39353b-00001.parquet
│ │ ├── 00001-1-4181e872-94fa-4699-ab5d-81dffa92de0c-00002.parquet
│ │ └── 00001-1-9b5f5291-af3b-4edc-adff-fbddf3e53709-00002.parquet
│ └── id_bucket=1
│ ├── 00001-1-4181e872-94fa-4699-ab5d-81dffa92de0c-00001.parquet
│ └── 00001-1-9b5f5291-af3b-4edc-adff-fbddf3e53709-00001.parquet
└── metadata
├── 00000-0934ba0e-8ed9-48e3-9db2-25dca1f896f2.metadata.json
├── 00001-454ee707-dbc0-4fd8-8c64-0910d8d6315b.metadata.json
├── 00002-7bdd0e6b-ec2b-4b1a-b355-6a81a3f5a0ae.metadata.json
├── 2170dbc3-334e-41ad-ac2c-68dd7470f001-m0.avro
├── 22e1674c-71ea-4d84-8982-276c3370d5c0-m0.avro
├── snap-5353330338887146702-1-2170dbc3-334e-41ad-ac2c-68dd7470f001.avro
└── snap-6683043578305788250-1-22e1674c-71ea-4d84-8982-276c3370d5c0.avro
5 directories, 13 files
因为我们每次写入的数据就几条,Iceberg 每个分区写文件的时候都是产生新的文件,这就导致底层文件系统里面产生了很多大小才几KB的文件。如果我们是使用 Spark Streaming 的方式7*24小时不断地往 Apache Iceberg 里面写数据,这将产生大量的小文件。
使用 Iceberg 来压缩文件
值得高兴的是,Apache Iceberg 给我们提供了相关 Actions API 来合并这些小文件,具体如下:
Configuration conf = new Configuration();
conf.set(METASTOREURIS.varname, "thrift://localhost:9083");
Map<String, String> maps = Maps.newHashMap();
maps.put("path", "default.iteblog");
DataSourceOptions options = new DataSourceOptions(maps);
Table table = findTable(options, conf);
SparkSession.builder()
.master("local[2]")
.config(SQLConf.PARTITION_OVERWRITE_MODE().key(), "dynamic")
.config("spark.hadoop." + METASTOREURIS.varname, "thrift://localhost:9083")
.config("spark.executor.heartbeatInterval", "100000")
.config("spark.network.timeoutInterval", "100000")
.enableHiveSupport()
.getOrCreate();
Actions.forTable(table).rewriteDataFiles()
.targetSizeInBytes(10 * 1024) // 10KB
.execute();
运行完上面代码之后,可以将 Iceberg 的小文件进行合并,得到的新数据目录如下:
⇒ tree /data/hive/warehouse/default.db/iteblog
/data/hive/warehouse/default.db/iteblog
├── data
│ └── ts_year=2020
│ ├── id_bucket=0
│ │ ├── 00000-0-19603f5a-d38a-4106-aeb9-47285d15a6bd-00001.parquet
│ │ ├── 00000-0-491c447b-e05f-40ac-8c32-44d5ef39353b-00001.parquet
│ │ ├── 00001-1-4181e872-94fa-4699-ab5d-81dffa92de0c-00002.parquet
│ │ ├── 00001-1-9b5f5291-af3b-4edc-adff-fbddf3e53709-00002.parquet
│ │ └── 00001-1-da4e85fa-096d-4b74-9b3c-a260e425385d-00001.parquet
│ └── id_bucket=1
│ ├── 00000-0-1d5871d5-08ac-4e43-a589-70a5d50dd4d2-00001.parquet
│ ├── 00001-1-4181e872-94fa-4699-ab5d-81dffa92de0c-00001.parquet
│ └── 00001-1-9b5f5291-af3b-4edc-adff-fbddf3e53709-00001.parquet
└── metadata
├── 00000-0934ba0e-8ed9-48e3-9db2-25dca1f896f2.metadata.json
├── 00001-454ee707-dbc0-4fd8-8c64-0910d8d6315b.metadata.json
├── 00002-7bdd0e6b-ec2b-4b1a-b355-6a81a3f5a0ae.metadata.json
├── 00003-d987d15f-2c7c-427c-849e-b8842d77d28e.metadata.json
├── 2170dbc3-334e-41ad-ac2c-68dd7470f001-m0.avro
├── 22e1674c-71ea-4d84-8982-276c3370d5c0-m0.avro
├── 25126b97-5a87-42b7-b45a-499aa41e7359-m0.avro
├── 25126b97-5a87-42b7-b45a-499aa41e7359-m1.avro
├── 25126b97-5a87-42b7-b45a-499aa41e7359-m2.avro
├── snap-3634417817414108593-1-25126b97-5a87-42b7-b45a-499aa41e7359.avro
├── snap-5353330338887146702-1-2170dbc3-334e-41ad-ac2c-68dd7470f001.avro
└── snap-6683043578305788250-1-22e1674c-71ea-4d84-8982-276c3370d5c0.avro
5 directories, 20 files
对比最新的结果可以得出:
ts_year=2020/id_bucket=0 新增了名为 00001-1-da4e85fa-096d-4b74-9b3c-a260e425385d-00001.parquet 的数据文件,这个其实就是把之前四个文件进行和合并得到的新文件; ts_year=2020/id_bucket=1 新增了名为 00000-0-1d5871d5-08ac-4e43-a589-70a5d50dd4d2-00001.parquet 的数据文件,这个其实就是把之前两个文件进行和合并得到的新文件。
Iceberg 小文件合并原理
Iceberg 小文件合并是在 org.apache.iceberg.actions.RewriteDataFilesAction 类里面实现的。小文件合并其实是通过 Spark 并行计算的,这也就是上面 DEMO 初始化了一个 SparkSession 的原因。我们可以通过 RewriteDataFilesAction 类的 targetSizeInBytes 方法来设置输出的合并文件大小。
注意:合并最终的文件并不是都小于或等于 targetSizeInBytes,甚至会出现文件根本没合并的情况。
当我们调用了 execute() 方法,RewriteDataFilesAction 类会先创建出一个 org.apache.iceberg.DataTableScan,然后会把对应表的最新快照(Snapshot)拿出来,紧接着拿出这个快照对应的底层所有数据文件。然后按照分区 Key 进行分组(group),同一个分区的文件放到一起,并将这些信息放到 Map<StructLikeWrapper, Collection> groupedTasks 的结果里面,groupedTasks 的 Key 就是分区信息,如果表不是分区表,那就是空分区;groupedTasks 的 value 就是对应分区底下的文件列表。
由于分区里面可能存在一个文件,这时候就没必要去执行文件合并,这时候可以去掉这部分分区,得到了 Map<StructLikeWrapper, Collection<FileScanTask>> filteredGroupedTasks。如果 filteredGroupedTasks 里面没有需要合并的分区那就直接返回了。
如果 filteredGroupedTasks 不为空,则对每个分区里面的文件进行 split 和 combine 操作,如下:
// Split and combine tasks under each partition
List<CombinedScanTask> combinedScanTasks = filteredGroupedTasks.values().stream()
.map(scanTasks -> {
CloseableIterable<FileScanTask> splitTasks = TableScanUtil.splitFiles(
CloseableIterable.withNoopClose(scanTasks), targetSizeInBytes);
return TableScanUtil.planTasks(splitTasks, targetSizeInBytes, splitLookback, splitOpenFileCost);
})
.flatMap(Streams::stream)
.collect(Collectors.toList());
combinedScanTasks 结构如下:
Apache iceberg write path 如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop combinedScanTasks 里面其实就是封装了 BaseCombinedScanTask 类,这个类里面的 task 就是标识哪些 Iceberg 的数据文件需要合并到新文件里面。得到 combinedScanTasks 之后会构造出一个 RDD:
JavaRDD<CombinedScanTask> taskRDD = sparkContext.parallelize(combinedScanTasks, combinedScanTasks.size());
然后最终会调用 taskRDD 的 map 方法,遍历 combinedScanTasks 里面的 task,将 task 里面对应的 Iceberg 读出来,再写到新文件里面:
public List<DataFile> rewriteDataForTasks(JavaRDD<CombinedScanTask> taskRDD) {
JavaRDD<TaskResult> taskCommitRDD = taskRDD.map(this::rewriteDataForTask);
return taskCommitRDD.collect().stream()
.flatMap(taskCommit -> Arrays.stream(taskCommit.files()))
.collect(Collectors.toList());
}
rewriteDataForTask 的实现如下:
private TaskResult rewriteDataForTask(CombinedScanTask task) throws Exception {
TaskContext context = TaskContext.get();
int partitionId = context.partitionId();
long taskId = context.taskAttemptId();
RowDataReader dataReader = new RowDataReader(
task, schema, schema, nameMapping, io.value(), encryptionManager.value(), caseSensitive);
SparkAppenderFactory appenderFactory = new SparkAppenderFactory(
properties, schema, SparkSchemaUtil.convert(schema));
OutputFileFactory fileFactory = new OutputFileFactory(
spec, format, locations, io.value(), encryptionManager.value(), partitionId, taskId);
BaseWriter writer;
if (spec.fields().isEmpty()) {
writer = new UnpartitionedWriter(spec, format, appenderFactory, fileFactory, io.value(), Long.MAX_VALUE);
} else {
writer = new PartitionedWriter(spec, format, appenderFactory, fileFactory, io.value(), Long.MAX_VALUE, schema);
}
try {
while (dataReader.next()) {
InternalRow row = dataReader.get();
writer.write(row);
}
dataReader.close();
dataReader = null;
return writer.complete();
} catch (Throwable originalThrowable) {
......
}
}
rewriteDataForTasks 执行完会返回新创建文件的路径,最后会写到新的快照里面。在快照里面会将新建的文件表示为 org.apache.iceberg.ManifestEntry.Status#ADDED,上一个快照里面的文件标记为 org.apache.iceberg.ManifestEntry.Status#DELETED。
