
Python实战破解『梨视频』反爬机制
 作者 | 李运辰
作者 | 李运辰来源 | Python爬虫数据分析挖掘
1
前言
前面讲了很多期的爬虫、数据分析、数据可视化。其中关键的一环就是爬虫,如果数据爬取不下来就无法进行分析和可视化。
因此本文分析『反爬机制』,讲解遇到这类反爬应该如何解决!
下面以『梨视频』为真实案例进行讲解!
2
获取视频列表
1.查看反爬类型
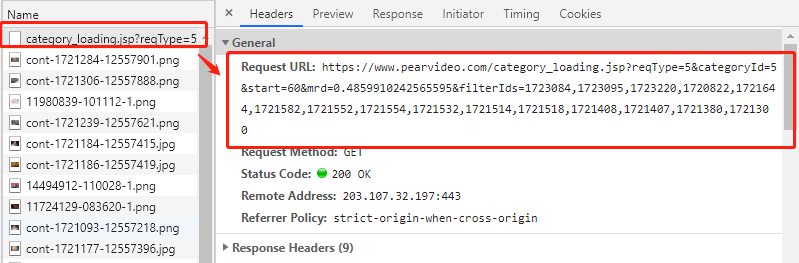
上图就是异步加载的链接,通过异步加载,将数据填充到网页!
2.分析异步加载链接

上面这两个链接的效果(返回的数据是一样的)
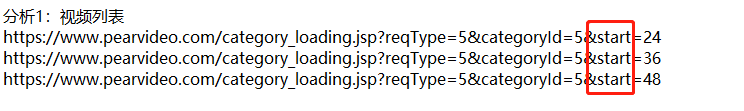
只需要更改start参数的值就可以获取更多的视频页面链接!
规律:start 以12递增
3.页面分析
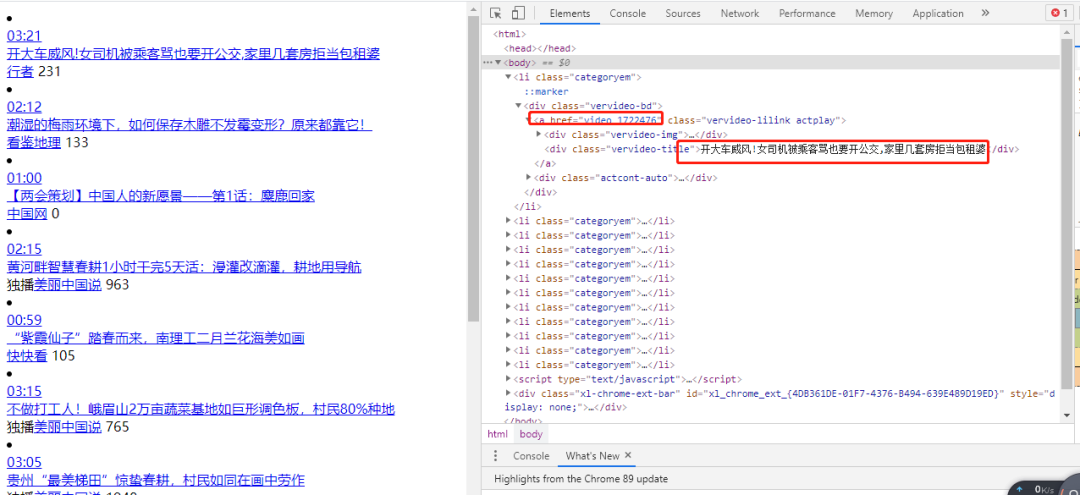
在网页中:
class=categoryem,对应的是列表。
class="vervideo-title"]/text(),对应视频的标题。
class="vervideo-bd"]/a/@href,对应视频网页链接(非真实播放链接)。
4.编程实现
###获取视频列表def getlist():url = "https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=5&start=36"res = requests.get(url, headers=headers)res.encoding = 'utf-8'text = res.textselector = etree.HTML(text)list = selector.xpath('//*[@class="categoryem"]')for i in list:href = i.xpath('.//div[@class="vervideo-bd"]/a/@href')[0]title = i.xpath('.//div[@class="vervideo-title"]/text()')[0]print(title)print(href)
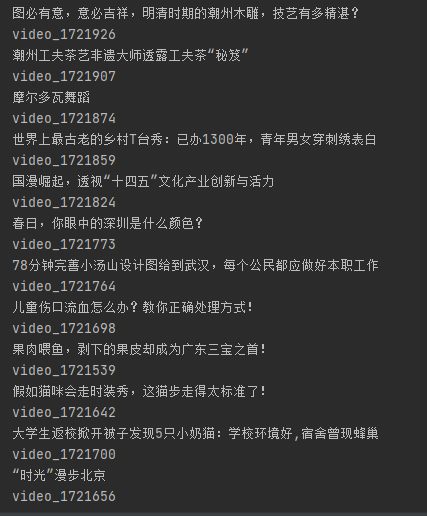
3
解析mp4播放地址
1.网页分析
下面将以这个视频网页链接为例进行分析
https://www.pearvideo.com/video_1721926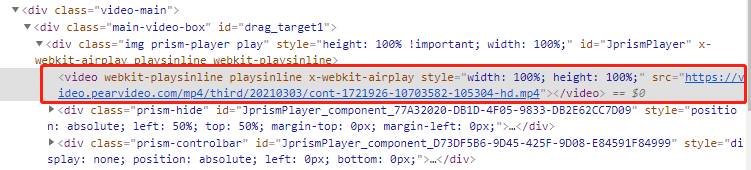
在class=main-video-box,标签内可以看到mp4地址,但这个是js加密过来的
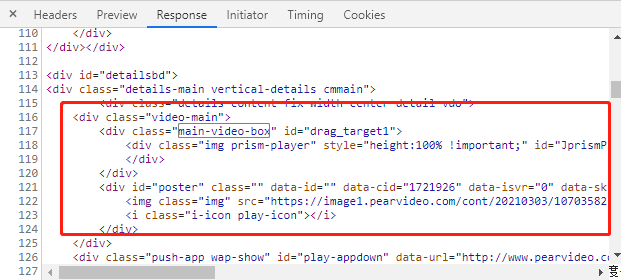
在原网页上是没有mp4播放地址的,因此我们需要去异步获取mp4播放地址!
2.分析数据包
https://www.pearvideo.com/videoStatus.jsp?contId=1721926&mrd=0.7353562335379842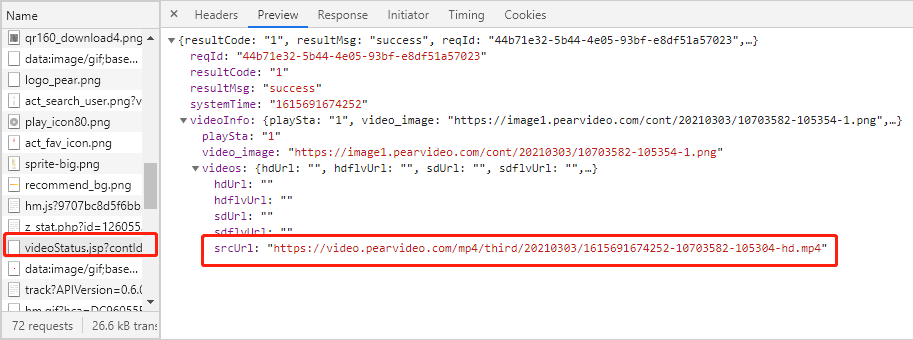
这个数据包可以看到mp4地址,但是访问时,发现又有反爬!
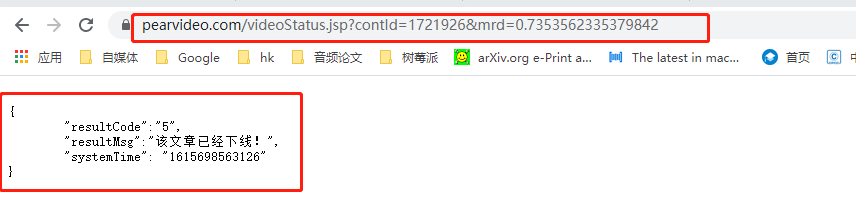
原因:
其中contid是视频的id
mrd是随机数(这才是反爬的限制)
因此我们需要去构造随机数。
3.构造随机数
url = "https://www.pearvideo.com/videoStatus.jsp?contId=" + str(countid) + "&mrd=" + str(random.random())headers_id = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36','cookie': '__secdyid=d95e39d0b5a512e1c35c5fdea59dcdd21b2758d39550e2c8021615635656; JSESSIONID=2DAE0DABD2DE9BB5D05335B2DE3AF8FF; PEAR_UUID=c32ee57d-4445-49f6-859a-a0a0fc054f1b; _uab_collina=161563565701204982722716; p_h5_u=C94D957E-E1CB-4130-9DF3-DDA387A42A8B; Hm_lvt_9707bc8d5f6bba210e7218b8496f076a=1615635658; UM_distinctid=1782b63b68f38-0331dcb7c2707d-5771133-100200-1782b63b690362; acw_tc=76b20f7116156407099735155e6bf791512b521ca0b97962f9cc398bc56d3a; CNZZDATA1260553744=1236015902-1615633517-%7C1615639181; Hm_lpvt_9707bc8d5f6bba210e7218b8496f076a=1615641462; SERVERID=ed8d5ad7d9b044d0dd5993c7c771ef48|1615641673|1615635656','Host': 'www.pearvideo.com','Referer': 'https://www.pearvideo.com/video_' + str(countid),}res = requests.get(url, headers=headers_id)res.encoding = 'utf-8'
通过random.random(),可以为mrd参数赋值随机数!
避坑:
Referer,请求头headers,中这个Referer可不能缺少!!!!!
countid = "1721926"url = "https://www.pearvideo.com/videoStatus.jsp?contId=" + str(countid) + "&mrd=" + str(random.random())headers_id = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36','cookie': '__secdyid=d95e39d0b5a512e1c35c5fdea59dcdd21b2758d39550e2c8021615635656; JSESSIONID=2DAE0DABD2DE9BB5D05335B2DE3AF8FF; PEAR_UUID=c32ee57d-4445-49f6-859a-a0a0fc054f1b; _uab_collina=161563565701204982722716; p_h5_u=C94D957E-E1CB-4130-9DF3-DDA387A42A8B; Hm_lvt_9707bc8d5f6bba210e7218b8496f076a=1615635658; UM_distinctid=1782b63b68f38-0331dcb7c2707d-5771133-100200-1782b63b690362; acw_tc=76b20f7116156407099735155e6bf791512b521ca0b97962f9cc398bc56d3a; CNZZDATA1260553744=1236015902-1615633517-%7C1615639181; Hm_lpvt_9707bc8d5f6bba210e7218b8496f076a=1615641462; SERVERID=ed8d5ad7d9b044d0dd5993c7c771ef48|1615641673|1615635656','Host': 'www.pearvideo.com','Referer': 'https://www.pearvideo.com/video_' + str(countid),}res = requests.get(url, headers=headers_id)res.encoding = 'utf-8'text = json.loads(res.text)

通过json解析可以取出mp4地址
videoInfo = text['videoInfo']['videos']['srcUrl']
这样就可以获取到视频的mp4地址!!!(可惜,这里的mp4地址只是一个虚拟的,需要进一步破解)
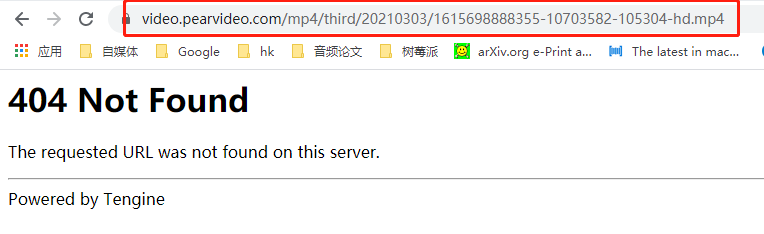
下面开始根据这个虚拟mp4地址去还原真实mp4地址!!!
4.还原真实mp4地址

真实mp4播放地址包含:cont-1721926(视频id)
因此需要将虚拟地址拼接成真实地址!!
s1 = videoInfo.split("-")[0][0:-13]s2 = "cont-" + str(countid) + "-"murl = videoInfo.split("-")s3 = murl[1] + "-" + murl[2] + "-hd.mp4"
最后为了方便使用,封装成一个函数,根据视频id就可以获取真实播放地址!
#获取到真实的MP4地址def getmp4(countid):#countid = "1721926"url = "https://www.pearvideo.com/videoStatus.jsp?contId=" + str(countid) + "&mrd=" + str(random.random())headers_id = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36','cookie': '__secdyid=d95e39d0b5a512e1c35c5fdea59dcdd21b2758d39550e2c8021615635656; JSESSIONID=2DAE0DABD2DE9BB5D05335B2DE3AF8FF; PEAR_UUID=c32ee57d-4445-49f6-859a-a0a0fc054f1b; _uab_collina=161563565701204982722716; p_h5_u=C94D957E-E1CB-4130-9DF3-DDA387A42A8B; Hm_lvt_9707bc8d5f6bba210e7218b8496f076a=1615635658; UM_distinctid=1782b63b68f38-0331dcb7c2707d-5771133-100200-1782b63b690362; acw_tc=76b20f7116156407099735155e6bf791512b521ca0b97962f9cc398bc56d3a; CNZZDATA1260553744=1236015902-1615633517-%7C1615639181; Hm_lpvt_9707bc8d5f6bba210e7218b8496f076a=1615641462; SERVERID=ed8d5ad7d9b044d0dd5993c7c771ef48|1615641673|1615635656','Host': 'www.pearvideo.com','Referer': 'https://www.pearvideo.com/video_' + str(countid),}res = requests.get(url, headers=headers_id)res.encoding = 'utf-8'text = json.loads(res.text)videoInfo = text['videoInfo']['videos']['srcUrl']s1 = videoInfo.split("-")[0][0:-13]s2 = "cont-" + str(countid) + "-"murl = videoInfo.split("-")s3 = murl[1] + "-" + murl[2] + "-hd.mp4"return s1+s2+s3
4
测试效果
for i in list:href = i.xpath('.//div[@class="vervideo-bd"]/a/@href')[0]title = i.xpath('.//div[@class="vervideo-title"]/text()')[0]mp4ulr = getmp4(href.replace("video_",""))print("标题="+str(title))print("mp4播放地址="+str(mp4ulr))

这样就可以获取到视频的1.标题和2.真实mp4链接。
5
下载视频
###下载视频def down(name,url):headers_down = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36','cookie': '__secdyid=d95e39d0b5a512e1c35c5fdea59dcdd21b2758d39550e2c8021615635656; JSESSIONID=2DAE0DABD2DE9BB5D05335B2DE3AF8FF; PEAR_UUID=c32ee57d-4445-49f6-859a-a0a0fc054f1b; _uab_collina=161563565701204982722716; p_h5_u=C94D957E-E1CB-4130-9DF3-DDA387A42A8B; Hm_lvt_9707bc8d5f6bba210e7218b8496f076a=1615635658; UM_distinctid=1782b63b68f38-0331dcb7c2707d-5771133-100200-1782b63b690362; acw_tc=76b20f7116156407099735155e6bf791512b521ca0b97962f9cc398bc56d3a; CNZZDATA1260553744=1236015902-1615633517-%7C1615639181; Hm_lpvt_9707bc8d5f6bba210e7218b8496f076a=1615641462; SERVERID=ed8d5ad7d9b044d0dd5993c7c771ef48|1615641673|1615635656','Host': 'video.pearvideo.com',}r = requests.get(url,headers=headers_down)with open("lyc/"+str(name)+".mp4", 'wb+') as f:f.write(r.content)
将下载代码封装成函数,通过视频名称和视频链接就可以将视频下载保存到本地!!
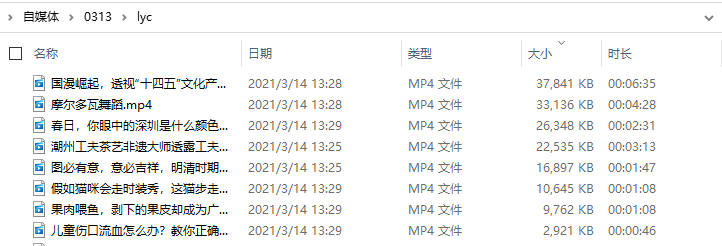
ok,这样就有可以破解『梨视频』反爬机制,轻松实现批量视频下载!
源码:https://gitee.com/lyc96/pear-video-anti-climbing
6
总结
1.获取视频列表(反爬1:异步加载)
2.解析真实的mp4播放链接(反爬2:根据视频id获取虚拟mp4地址,通过拼接方式获取真实mp4地址)
3.根据mp4地址去下载视频,实现批量下载。