
蚂蚁二面:MQ消费端遇到瓶颈除了横向扩容外还有其他解决办法?
面试场景与面试技巧
一位朋友最近在蚂蚁金服第二轮面试时遇到这样一个问题:如果MQ消费遇到瓶颈时该如何处理?。
横向扩容,相比很多读者与我这位朋友一样会脱口而出,面试官显然不会满意这样的回答,然后追问道:横向扩容是堆机器,还有没有其他办法呢?
在面试过程中,个人建议大家在听到问题后稍作思考,不要立马给出太直接的答案,而是应该与面试官进行探讨,一方面可更深刻的理解面试官的出题初衷,同时可以给自己梳理一下思路。
消费端遇到瓶颈,这是一个结果,但引起这个结果的原因是什么呢?在没有弄清楚原因之前谈优化、解决方案都会显得很苍白。
在这样的面试场景中,我们该如何探讨交流呢?我的思路如下:
尝试与面试官探讨如何判断消费端遇到瓶颈 如何查找根因 提出解决方案
温馨提示:为了本文观点的严谨性,本文主要以RocketMQ为例进行剖析。
如何判断消费端遇到瓶颈
在RocketMQ消费领域中判断消费端遇到瓶颈通常有两个重要的指标:
消息积压数量(延迟数量) lastConsumeTime
在开源版本的控制台rocketmq-console界面中,可以查阅一个消费端上述两个指标,如下图所示:
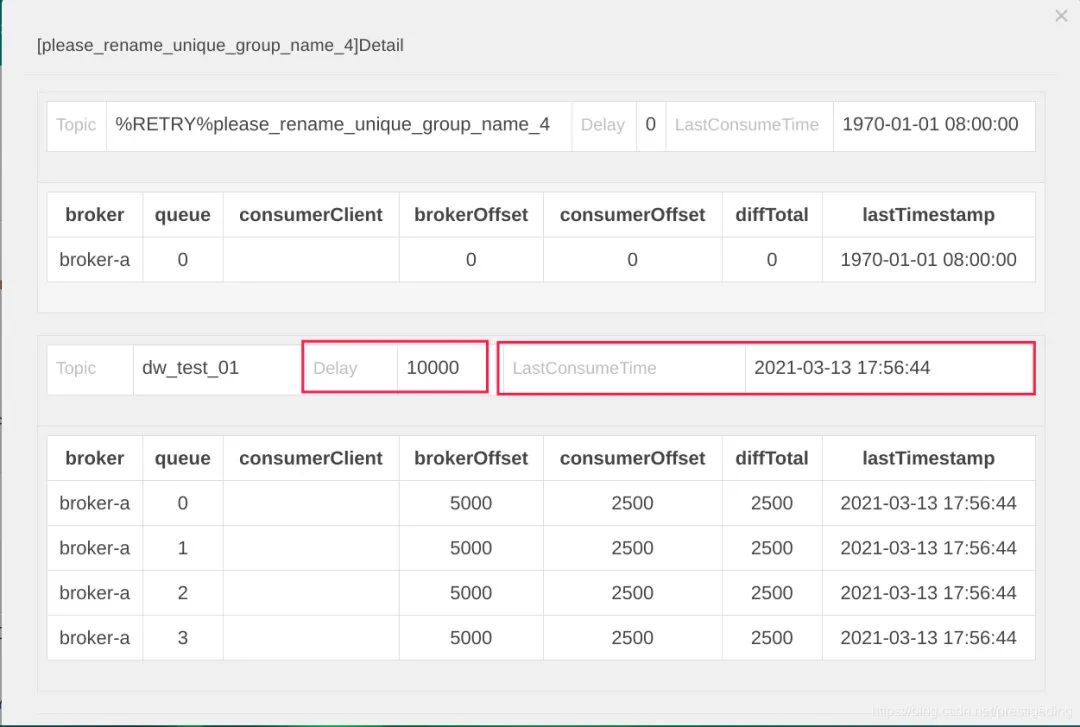
Delay:消息积压数量,即消费端还剩下多少消息未处理,该值越大,说明消费端遇到瓶颈了。 LastConsumeTime:表示上一次成功消费的消息的存储时间,该值离当前时间越大,同样能说明消费端遇到瓶颈了。
那为什么会积压呢?消费端是在哪遇到瓶颈了呢?
如何定位问题
消费端出现瓶颈,如何识别是客户端的问题还是服务端的问题,一个最简单的办法是看集群内其他消费组是否也有积压,特别是和有问题的消费组订阅同一个主题的其他消费组是否有积压,按照笔者的经验,出现消息积压通常是客户端的问题,可以通过查询 rocketmq_client.log加以证明:
grep "flow" rocketmq_client.log
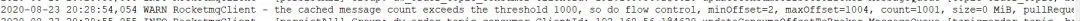
出现so do flow control 这样的日志,说明触发了消费的限流,其直接触发原因:就是消息消费端积压消息,即消费端无法消费已拉取的消息,为了避免内存泄露,RocketMQ在消费端没有将消息处理完成后,不会继续向服务端拉取消息,并打印上述日志。
那如何定位消费端慢在哪呢?是卡在哪行代码呢?
通常的排查方法是跟踪线程栈,即利用jstack命令查看线程运行情况,以此来探究线程的运行情况。
通常使用的命令如下:
ps -ef | grep java
jstack pid > j1.log
通常为了对比,我一般会连续打印5个文件,从而可以在5个文件中查看同一个消费者线程,其状态是否变化,如果未变化,则说明该线程卡主,那就是我们重点需要关注的地方。
在RocketMQ中,消费端线程以ConsumeMessageThread_开头,通过对线程的判断,如下代码让人为之兴奋:
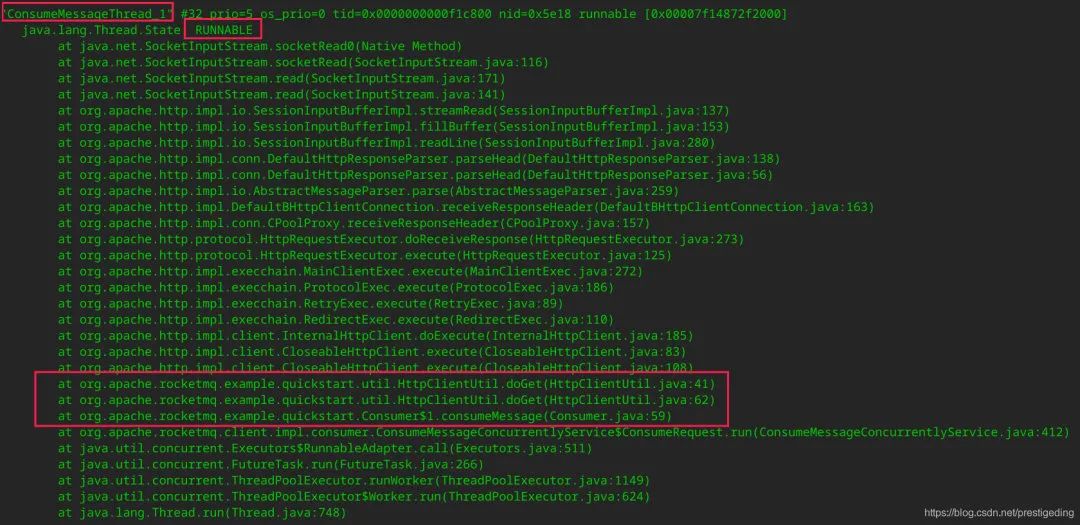
消费端线程的状态是RUNNABLE,但在5个文件中其状态都是一样,基本可以断定线程卡在具体的代码,从示例代码中是卡在掉一个外部的http借口,从而加以解决,通常在涉及外部调用,特别是http调用,可以设置一个超时时间,避免长时间等待。
解决方案
其实根据第三步骤,大概率能明确是哪个地方慢,遇到了性能瓶颈,通常无非就是调第三方服务,数据库等问题出现了瓶颈,然后对症下药。数据库等性能优化,并不在本文的讨论范围之内,故这里可以点到为止,当然面试官后续可能会继续聊数据库优化等话题,这样就实现了与面试官的交流互动,一环扣一环,技术交流氛围友好,面试通过率大大提高。
最后,我还想和大家探讨一个问题,出现消息积压就一定意味着遇到消费瓶颈,一定需要处理吗?
其实也不然,我们回想一下为什么需要使用MQ,不就是利用异步解耦与削峰填谷吗?例如在双十一期间,大量突发流量汇入,此时很可能导致消息积压,这正式我们的用意,用MQ抗住突发流量,后端应用慢慢消费,保证消费端的稳定,在积压的情况下,如果tps正常,即问题不大,这个时候通常的处理方式就是横向扩容,尽可能的降低积压,减少业务的延迟。
这篇文章来自于我的好基友的公众号 「中间件兴趣圈」,由《RocketMQ技术内幕》作者,RocketMQ社区优秀布道师维护,主打成体系分享JAVA主流中间件,打造完备的互联网架构体系,目前涵盖Java并发、微服务、消息、调度、数据异构等领域,未来继续关注监控、在线诊断等领域。
点击关注公众号回复【RMQPDF】可以领取由阿里巴巴根据我RocketMQ专栏整理的电子书:
私人微信我也给你们要来了,可以加他偷窥他的朋友圈,还可以私聊他进技术群,群内有来自不同大厂的N多大佬。