深度学习时代工业界最常用的检索算法?
共
2447字,需浏览
5分钟
·
2022-05-28 12:57
今天给大家分享一个在工业界、实际工作中非常常用的技术——向量检索。得益于深度学习、表示学习的迅猛发展,向量化检索逐渐成为实际应用中很常见检索方法之一,是深度学习时代很多成熟系统的基础模块,在诸如文档检索系统、广告系统、推荐系统应用广泛。通过离线或在线将实体表示成向量的形式,再进行向量之间的距离度量,实现线上检索。举个例子,在文档检索系统中,一种常见的方法是训练能够将query和document分别进行编码的Encoder,一般采用query和docuemnt的匹配度为label进行训练,并将document的向量表示存储起来。在线阶段,使用query和docuemnt的向量计算内积,得到query和各个候选document的距离,根据距离排序,实现topK检索。在其他系统中的实现方法也是类似的,区别是编码的实体差异,例如在广告系统中可能是根据user或query的向量和广告的向量进行召回。
由于目前工业界的系统数据量都很大,直接进行全量数据的向量检索计算代价非常高。因此,ANN(Approximate Nearest Neighbor,近似近邻检索)成为一种高效替代方案。其中,基于量化的ANN方法是目前工业界最常用的向量检索方案之一。本文给大家整理了基于量化的ANN检索方法的发展历程。
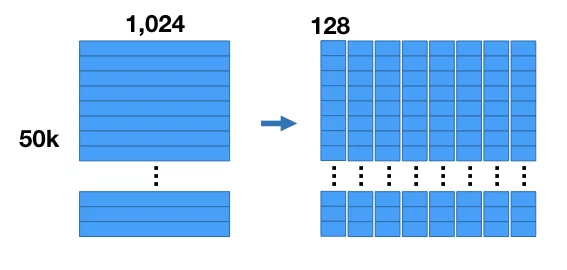
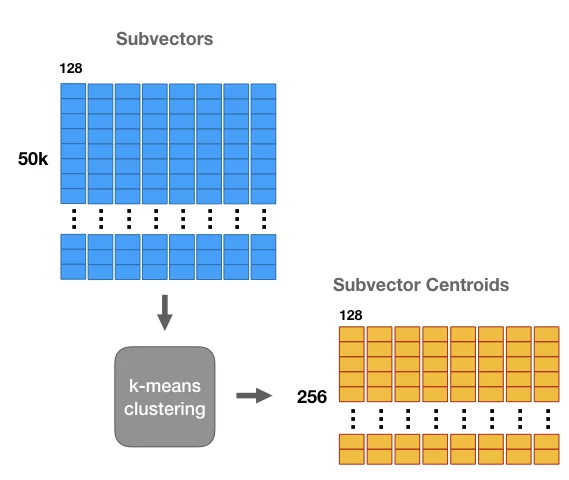
基于量化的近邻检索方法最早提出于 Product quantization for nearest neighbor search(2010)这篇文章。Product Quantization(PQ)的整个过程可以表示为如下形式。假设我们做的是搜索广告召回,每个广告都表示成一个维度为1024的向量。首先将每个向量分成多段(如这里是8段,每段128维)字向量。接下来,在每一段内部通过Kmeans聚类的方式得到K个质心(如256个),这样就得到一个codebook,代表了每段内每个cluster_id和向量的对应关系。最后对于每个样本的每段向量,用距离其最近的聚类中心的id表示。通过这种方式,我们将原来的1024维度浮点数向量,压缩成了8维的整型向量,大幅压缩了向量体积。在还原阶段,也可以使用codebook对压缩的向量进行还原,还原前后向量的欧式距离即为压缩带来的失真度,可以表示为如下公式,其中i表示量化过程(encoder),c表示还原过程(decoder)。
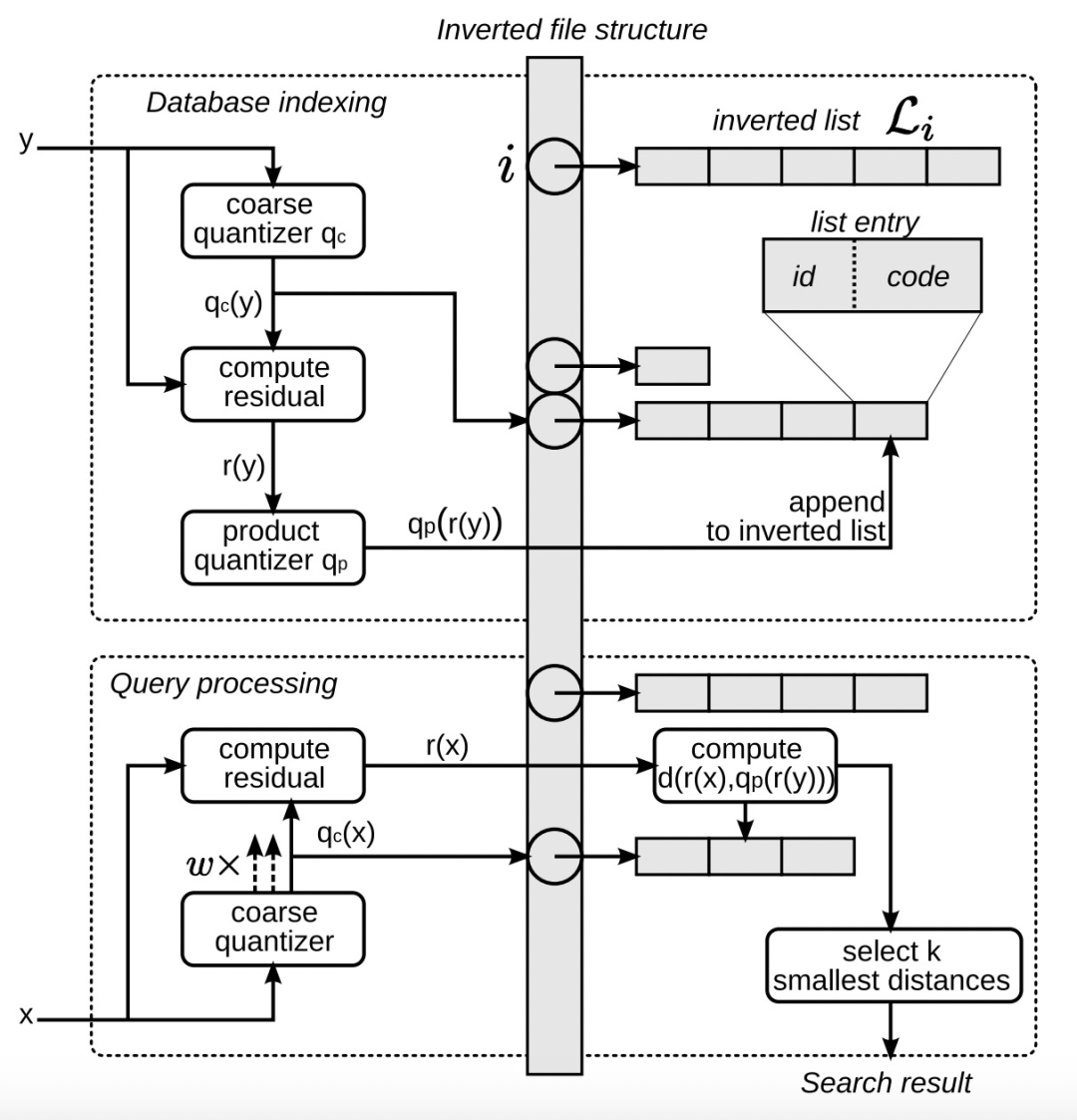
那么,得到量化后的向量,如何进行近邻检索呢?主要包括两种方法,一种是SDC(symmetric distance computation),另一种是ADC(asymmetric distance computation)。在下图中,x和y分别表示query和某个候选广告对应的原始向量,q()函数表示量化函数。SDC的方法是将x和y都量化成聚类中心,利用聚类中心的距离表示x和y的距离。ADC的方法是不对x进行量化,直接计算x和量化后y的聚类中心的距离。最终整体的距离是各段量化距离之和。
为了进一步优化PQ的运行效率,文中提出了inverted file with asymmetric distance computation (IVFADC)的PQ实现方法。IVFADC将量化分为粗量化和积量化两个步骤,粗量化时借助Kmeans使用较少的质心表示所有数据,积量化采用PQ对粗量化的残差进行分段量化。这种方法进一步提升了检索效率。
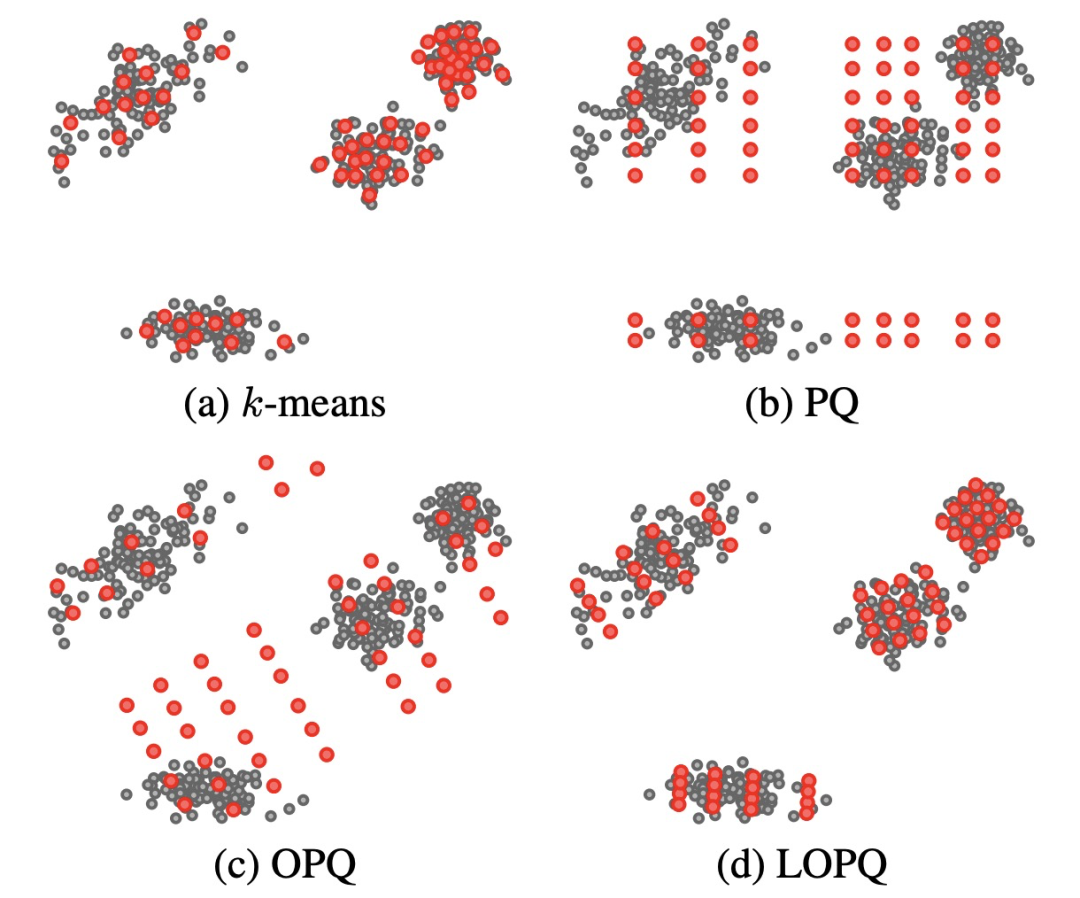
Optimized Product Quantization基础的PQ算法并没有考虑如何对原始向量进行分割,能把量化前后的向量失真度降到最低。向量的分割方法在PQ中和数据完全无关,而更好的方案是根据数据分布进行向量划分调整。Optimized Product Quantization(2014)对PQ算法进行了优化,以量化前后的失真度作为优化目标对向量进行分割,以及生成codebook,相比原来的优化增加了将向量分割方式考虑到优化目标内。整体优化过程可以表示为如下公式,其中R表示一个正交矩阵,定义了向量的分割方式,可以理解为利用R将codebook的向量空间进行了旋转,以更好的适应数据分布:
针对上述优化问题,文中提出了参数化和非参数化两种求解方法。非参数方法交替优化R矩阵和codebook,固定R使用基础PQ方法优化codebook,再固定codebook使用SVD方法优化R矩阵。
Locally Optimized Product Quantization(LOPQ,2014)在OPQ的基础上更近一步,对每个子空间都进行旋转。Kmeans、PQ、OPQ、LOPQ这4种方法生成的质心对比如下图所示。
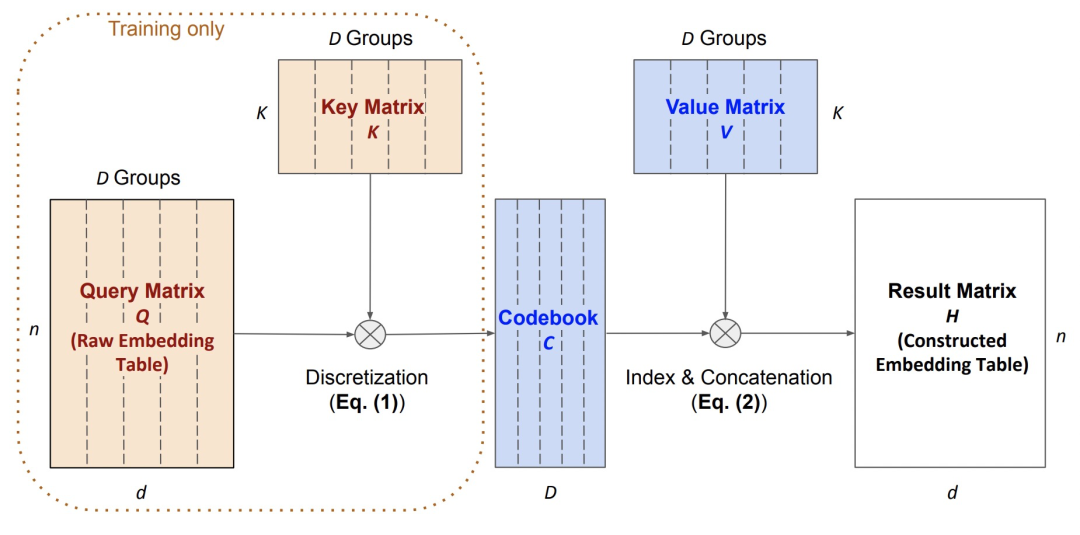
Differentiable Product Quantization for End-to-End Embedding Compression(ICML 2020)提出了可导的量化方法(DPQ),利用可导量化的思路提出了对embedding table进行压缩的方法。首先将原始的embedding table利用一个Key Matrix进行离散化生成codebook,再使用一个Value Matrix进行逆向操作生成重构的embedding表。在实际使用的时候,只保留中间产出的codebook和value matrix。在离散化过程中,将embedding和Key矩阵的向量都分成D份,计算每份的距离并以距离最小的作为其对应的离散化id表示,和量化方法类似。为了让上述过程是可导的,将距离计算取最小的argmin操作改为softmax操作,实现了离散化过程可导的目的。
向量检索是工业界很多在线系统的基础,而量化更是实现高效的向量检索中最常用的方法之一。这篇文章整理了量化的核心思路,以及后续优化工作,可以在实际应用中进行尝试。
点赞
评论
收藏
分享

手机扫一扫分享
举报
点赞
评论
收藏
分享
手机扫一扫分享
举报
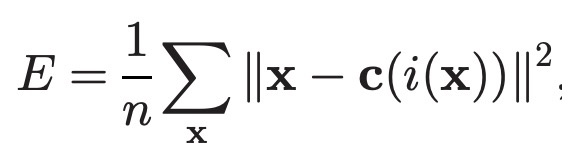

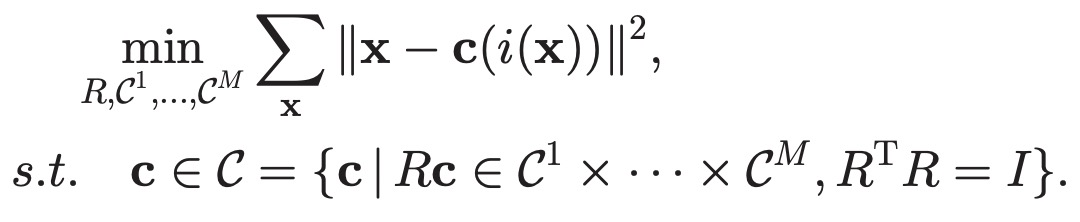
 下载APP
下载APP