
我是如何用 redis 做实时订阅推送的
前阵子开发了公司领劵中心的项目,这个项目是以 redis 作为关键技术落地的。
先说一下领劵中心的项目吧,这个项目就类似京东 app 的领劵中心,当然图是截取京东的,公司的就不截了。。。
其中有一个功能叫做领劵的订阅推送。
什么是领劵的订阅推送?
就是用户订阅了该劵的推送,在可领取前的一分钟就要把提醒信息推送到用户的 app 中。
本来这个订阅功能应该是消息中心那边做的,但他们说这个短时间内做不了。所以让我这个负责优惠劵的做了 -.-!。具体方案就是到具体的推送时间点了,coupon 系统调用消息中心的推送接口,把信息推送出去。
下们我们分析一下这个功能的业务情景。公司目前注册用户 6000W+,是哪家就不要打听了。。。比如有一张无门槛的优惠劵下单立减 20 元,那么抢这张劵的人就会比较多,我们保守估计 10W+,百万级别不好说。我们初定为 20W 万人,那么这 20W 条推送信息要在一分钟推送完成!并且一个用户是可以订阅多张劵的。所以我们知道了这个订阅功能的有两个突出的难点:
推送的实效性:推送慢了,用户会抱怨没有及时通知他们错过了开抢时机。
推送的体量大:爆款的神劵,人人都想抢!
然而推送体量又会影响到推送的实效性。这真是一个让人头疼的问题!
那就让我们把问题一个个解决掉吧!
推送的实效性的问题:当用户在领劵中心订阅了某个劵的领取提醒后,在后台就会生成一条用户的订阅提醒记录,里面记录了在哪个时间点给用户发送推送信息。所以问题就变成了系统如何快速实时选出哪些要推送的记录!
方案 1:
MQ 的延迟投递。MQ 虽然支持消息的延迟投递但尺度太大 1s 5s 10s 30s 1m,用来做精确时间点投递不行!并且用户执行订阅之后又取消订阅的话,要把发出去的 MQ 消息 delete 掉这个操作有点头大,短时间内难以落地!并且用户可以取消之后再订阅,这又涉及到去重的问题。所以 MQ 的方案否掉。
方案 2:
传统定时任务。这个相对来说就简单一点,用定时任务是去 db 里面 load 用户的订阅提醒记录,从中选出当前可以推送的记录。但有句话说得好任何脱离实际业务的设计都是耍流氓~。下面我们就分析一下传统的定时任务到底适不适合我们的这个业务!
| 能否支持多机同时跑 | 一般不能,同一时刻只能单机跑。 |
| 存储数据源 | 一般是 mysql 或者其它传统数据库,并且是单表存储 |
| 频率 | 支持秒、分、时、天,一般不能太快 |
综上所述我们就知道了一般传统的定时任务存在以下缺点:
性能瓶颈。只有一台机在处理,在大体量数据面前力不从心!
实效性差。定时任务的频率不能太高,太高会业务数据库造成很大的压力!
单点故障。万一跑的那台机挂了,那整个业务不可用了 -。- 这是一个很可怕的事情!
所以传统定时任务也不太适合这个业务。。。
那我们是不是就束手无策了呢?其实不是的! 我们只要对传统的定时任务做一个简单的改造!就可以把它变成可以同时多机跑, 并且实效性可以精确到秒级,并且拒绝单点故障的定时任务集群!这其中就要借助我们的强大的 redis 了。
方案 3:定时任务集群
首先我们要定义定时任务集群要解决的三个问题!
1、实效性要高
2、吞吐量要大
3、服务要稳定,不能有单点故障
下面是整个定时任务集群的架构图。
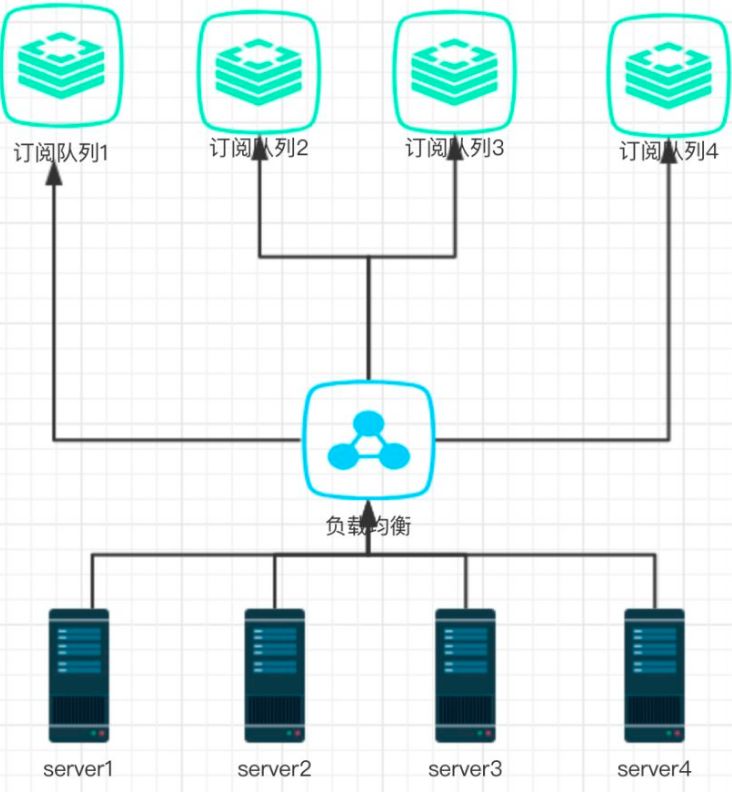
架构很简单:我们把用户的订阅推送记录存储到 redis 集群的 sortedSet 队列里面, 并且以提醒用户提醒时间戳作为 score 值,然后在我们个每业务 server 里面起一个定时器频率是秒级,我的设定就是 1s,然后经过负载均衡之后从某个队列里面获取要推送的用户记录进行推送。下面我们分析以下这个架构。
1、性能:除去带宽等其它因素,基本与机器数成线性相关。机器数量越多吞吐量越大,机器数量少时相对的吞吐量就减少。
2、实效性:提高到了秒级,效果还可以接受。
3、单点故障?不存在的!除非 redis 集群或者所有 server 全挂了。。。。
这里解析一下为什么用 redis?
第一 redis 可以作为一个高性能的存储 db,性能要比 MySQL 好很多,并且支持持久化,稳定性好。
第二 redis SortedSet 队列天然支持以时间作为条件排序,完美满足我们选出要推送的记录。
ok~ 既然方案已经有了那如何在一天时间内把这个方案落地呢?是的我设计出这个方案到基本编码完成,时间就是一天。。。因为时间太赶鸟。
首先我们以 user_id 作为 key,然后 mod 队列数 hash 到 redis SortedSet 队列里面。为什么要这样呢,因为如果用户同时订阅了两张劵并且推送时间很近,这样的两条推送就可以合并成一条~,并且这样 hash 也相对均匀。下面是部分代码的截图:

然后要决定队列的数量,一般正常来说我们有多少台处理的服务器就定义多少条队列。因为队列太少,会造成队列竞争,太多可能会导致记录得不到及时处理。
然而最佳实践是队列数量应该是可动态配置化的,因为线上的集群机器数是会经常变的。大促的时候我们会加机器是不是,并且业务量增长了,机器数也是会增加是不是~。所以我是借用了淘宝的 diamond 进行队列数的动态配置。

我们每次从队列里面取多少条记录也是可以动态配置的

这样就可以随时根据实际的生产情况调整整个集群的吞吐量~。 所以我们的定时任务集群还是具有一个特性就是支持动态调整~。
最后一个关键组件就是负载均衡了。这个是非常重要的!因为这个做得不好就会可能导致多台机竞争同时处理一个队列,影响整个集群的效率!在时间很紧的情况下我就用了一个简单实用的利用 redis 一个自增 key 然后 mod 队列数量算法。这样就很大程度上就保证不会有两台机器同时去竞争一条队列~.

最后我们算一下整个集群的吞吐量
10(机器数) * 2000(一次拉取数) = 20000。然后以 MQ 的形式把消息推送到消息中心,发 MQ 是异步的,算上其它处理 0.5s。
其实发送 20W 的推送也就是 10 几 s 的事情。
ok~ 到这里我们整个定时任务集群就差不多基本落地好了。如果你问我后面还有什么可以完善的话那就是:
加监控, 集群怎么可以木有监控呢,万一出问题有任务堆积怎么办~
加上可视化界面。
最好有智能调度,增加任务优先级。优先级高的任务先运行嘛。
资源调度,万一机器数量不够,力不从心,优先保证重要任务执行。
目前项目已上前线,运行平稳~。
如有文章对你有帮助,
“在看”和转发是对我最大的支持!
推荐, GitHub 书籍仓库 https://github.com/ebooklist/awesome-ebooks-list 整理了大部分常用 技术书籍PDF,持续更新中... 你需要的技术书籍,这里可能都有...
点击文末“阅读原文”可直达
整理不易,麻烦各位小伙伴在GitHub中来个一键三连
