数据库的索引分为主键索引(Primary Inkex)与普通索引(Secondary Index)。InnoDB和MyISAM是怎么利用B+树来实现这两类索引,其又有什么差异呢?这是今天要聊的内容。
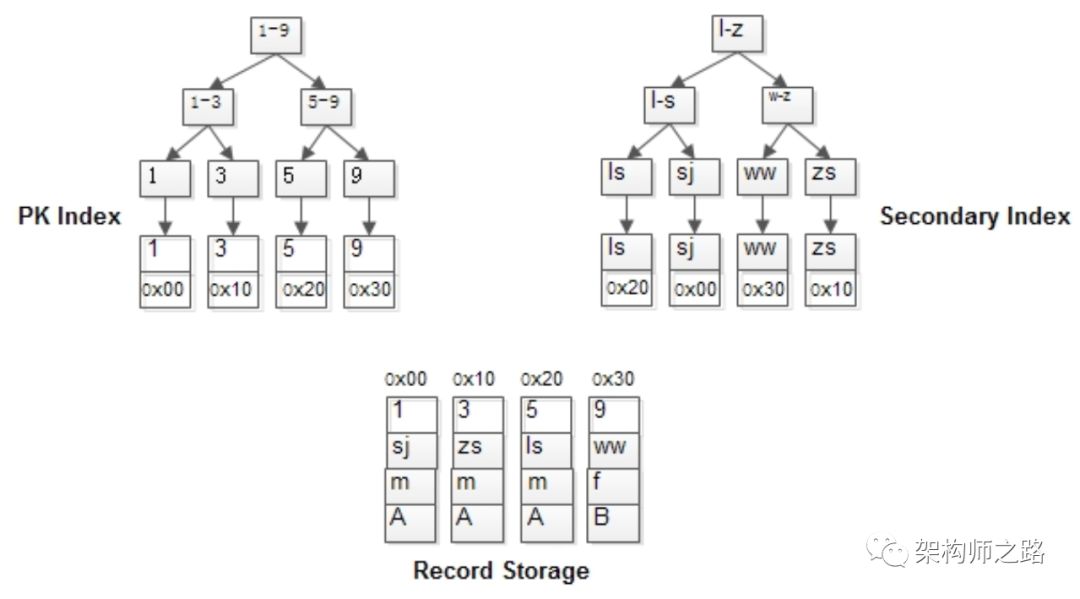
MyISAM的索引与行记录是分开存储的,叫做非聚集索引(UnClustered Index)。(2)主键索引的叶子节点,存储主键,与对应行记录的指针;(3)普通索引的叶子结点,存储索引列,与对应行记录的指针;主键索引与普通索引是两棵独立的索引B+树,通过索引列查找时,先定位到B+树的叶子节点,再通过指针定位到行记录。t(id PK, name KEY, sex, flag);1, shenjian, m, A
3, zhangsan, m, A
5, lisi, m, A
9, wangwu, f, B
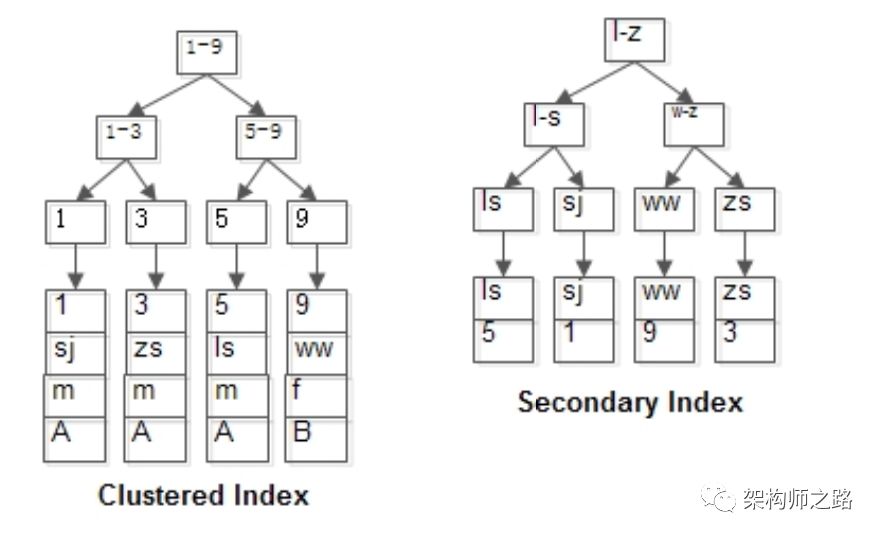
(2)id为PK,有一棵id的索引树,叶子指向行记录;(3)name为KEY,有一棵name的索引树,叶子也指向行记录;InnoDB的主键索引与行记录是存储在一起的,故叫做聚集索引(Clustered Index):(2)主键索引的叶子节点,存储主键,与对应行记录(而不是指针);(2)如果表没有定义PK,则第一个非空unique列是聚集索引;(3)否则,InnoDB会创建一个隐藏的row-id作为聚集索引;
聚集索引,也只能够有一个,因为数据行在物理磁盘上只能有一份聚集存储。InnoDB的普通索引可以有多个,它与聚集索引是不同的:(1)普通索引的叶子节点,存储主键(也不是指针);(1)不建议使用较长的列做主键,例如char(64),因为所有的普通索引都会存储主键,会导致普通索引过于庞大;(2)建议使用趋势递增的key做主键,由于数据行与索引一体,这样不至于插入记录时,有大量索引分裂,行记录移动;t(id PK, name KEY, sex, flag);1, shenjian, m, A
3, zhangsan, m, A
5, lisi, m, A
9, wangwu, f, B
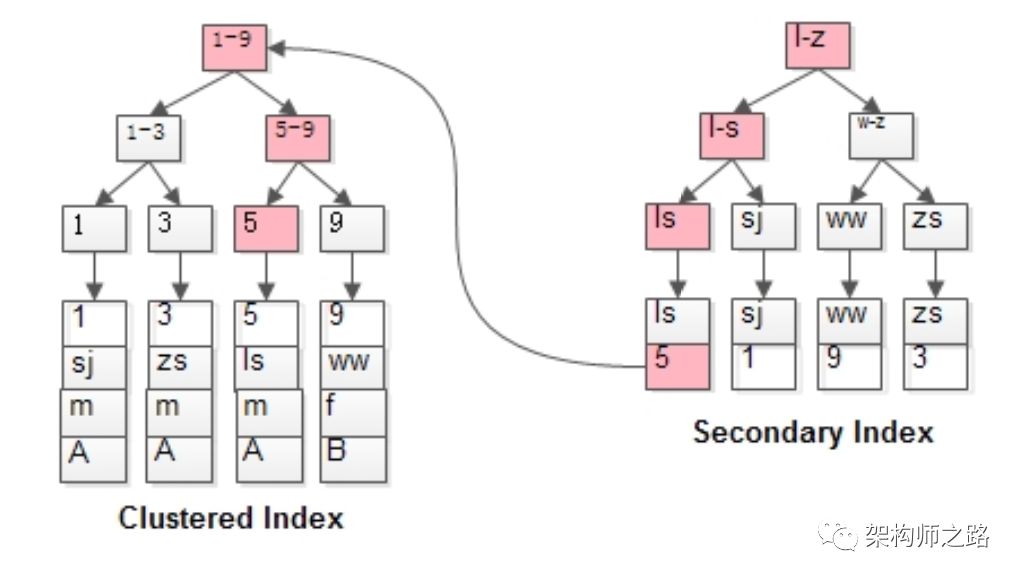
(2)name为KEY,有一棵name的索引树,叶子存储id;select * from t where name=‘lisi’;会先通过name辅助索引定位到B+树的叶子节点得到id=5,再通过聚集索引定位到行记录。MyISAM和InnoDB都使用B+树来实现索引:(2)MyISAM的索引叶子存储指针,主键索引与普通索引无太大区别;(4)InnoDB的聚集索引存储数据行本身,普通索引存储主键;(6)InnoDB建议使用趋势递增整数作为PK,而不宜使用较长的列作为PK;
四,如何系统学习数据库知识体系?
腾讯技TDSQL术专家秦玮联手前58集团高级架构师陈东,打磨了一套《数据库实战32讲》在线专栏课,帮你快速掌握数据库核心架构技术。
费用:1.99(原价499,粉丝福利价 1.99)扫码报名,耐心等待顾问老师通过